

On Trust and Transparency in Detection
This blog / mini-paper is written jointly with Oliver Rochford.
When we detect threats we expect to know what we are detecting. Sounds painfully obvious, right? But it is very clear to us that throughout the entire history of the security industry this has not always been the case. Some of us remember the early days of the network IDS intrusion detections systems were delivered without customers being able to see how the detections worked . The market spoke, and these vendors are all dead and buried by Snort and its descendants, who opened their detection signatures for both review and modification.
Ever since, most detections have been quite easy to access and understand, with visible logic primarily based on string searches, regular expressions, and syntaxes using pattern matching and simple IF/ELSE/AND/OR statements.
But as we increasingly move towards more elaborate detection approaches like detection-as-code using languages like the Sigma language, or Python, it is becoming more difficult to deduce in detail how certain threat detections work. In the case of cloud native detections, the underlying code may not be available at all, as they are deeply integrated into the cloud application or infrastructure layer, with users only ever seeing the resulting alerts.
And let’s not even mention the challenges involved in trying to understand machine learning algorithms, especially deep learning. Some EDR vendors today already run mostly off opaque detections, hiding their rules, threat intelligence and their algorithmic detections. They are generally quite successful in the market with this approach, and they do not perceive this as a limitation at all.
It seems as though the era of opaque detections is upon us, again. Such opaqueness comes in many coats: hidden by the vendors for commercial reasons, obscured by the high knowledge barrier to understand the logic or hidden by inherently opaque detection methods like ML. And we are not even talking about the managed services where the customers may only ever see alerts, and never the detection logic.
As a consequence, security teams are beginning to place much greater emphasis on being able to understand how a detection machine made a decision since they cannot simply look at what the signature does.
The reason for this increased scrutiny isn’t hard to understand — the cornerstone of all effective cyber threat detection systems is accurate detection. Alert fatigue is an acute industry-wide problem, so being able to understand why a detection misfires is crucial to decide whether it is worth keeping or needs to be disabled or tuned. And more importantly, as we seek to deploy more autonomous threat response processes, it doesn’t matter how much malicious activity is blocked if the system is also incorrectly blocks benign traffic sometimes.
Now, who is accountable?
There have been attempts in the past to use more sophisticated detection approaches such as Bayesian analysis for virus, malware, or spam detection and even to enable basic automatic response. These usually suffered from the dual curse of low accuracy and low explainability, generating many false positives (and false negatives), while at the same time being difficult to decipher and explain to the leadership.
Most security leaders showed low tolerance for automatic actions if business activities were disrupted even just a few times, especially in the absence of true positives and measurable successes. The ratio of blocking true threats versus false positives was low, so in the case of virus detection it was often difficult to demonstrate value sufficiently before false positives undermined any trust the business may have had.
The bigger question was, who is responsible if a business-critical activity is interrupted? Who is accountable? We need to discuss this before we get back to detection accuracy and transparency. Inevitably, this was the IT or security leader and their team, and this hasn’t really changed.
In most organizations, selecting security tools is the CISO’s team responsibility, so any fallout for security technology misbehaving would also land on them. A CISO is unlikely to select a solution that has the potential to interrupt the business without being able to justify that decision and be able to explain why something has gone wrong. It’s one thing deploying a solution that can block ransomware before it can encrypt most critical data, but another thing entirely when that solution keeps blocking legitimate users and you can’t work out why. No sane CISO will pick a tool that might cost them their job.
Of course, this applies mainly when we are talking about detections driving autonomous containment actions.
However, would security leaders accept opaque directions if the vendor is responsible? This may apply to managed or curated detections that are essentially “guaranteed to work.” Will the security buyers and users accept an opaque system if the vendor offers some guarantee of performance? This is a bit similar to some self-driving car approaches being tested where a car buyer or driver will not be responsible for crashes.
In fact, what role does detection accuracy play in all of this?
So what about accuracy?
Frankly, the main reason we need to be able to understand threat detections is in case they fail. False positives are the most common form of detection failure. False positives (FP) are the bane of security operations, with some studies claiming that up to 99% of all detections are FP’s[1], resulting in alert fatigue to the point of negatively affecting staff health and retention[2].
Many security teams already spend much of their time investigating false positives even when the logic or code for detections is available. Making it even harder to work out why an opaque detection failed will consume even more time.
But what if detections have a high degree of accuracy, and a very low false positive rate? Do you still need interpretability? Of course, the answer depends on how much more accurate. Some detections can be very precise, but it is usually impossible to only use detections with a high degree of precision without also sacrificing recall[3]. Limiting detection to only utilize high confidence detections will mean making a trade-off between detection accuracy and threat visibility. In essence, you boost a chance for a false negative! It’s also a numbers game. Surveys and studies cite very different numbers for the amounts of alerts enterprises must review, anywhere from hundreds[4,5] to thousands [6] per day. Even a small false positive rate means that security teams will be spending time trying to analyze a black box or engaging with technical support.
And can you ever ensure 100% accuracy and 0% false positives? No idea, but you frankly don’t want to! Also, for opaque detections, any potential gains in higher precision may be offset by the additional time it takes to investigate the result of non-transparent detections (Go and triage “Access Anomaly” or “Risk Score is 73” alerts!).
So even if you can assure a high degree of precision — is superior performance of an opaque approach sufficient to gain user trust? This is hotly debated [7,8]. Some people must see the code to trust the system (an approach naturally conflicting with ML approaches) while others will trust the system based on other criteria (explainability, superior performance, vendor performance guarantees, support for situations where detections backfire, etc).
Due to negativity bias, bad experiences leave a much greater impression than positive ones [9], and most users lose faith in detections very quickly if they experience even a few false positives, and may even begin to mistrust correct findings. Detection and automation vendors who ignore this, do so at their own peril.
But perhaps full transparency of detection code is not the only way to get to trust. This brings us to a quick detour to Interpretability vs Explainability.
Understanding? Or Explaining?
Is being able to see the code the only path to trust? What other paths may be conceivable here? A parallel may be found in the field of data science, where the problem of understanding decisions taken by opaque ML models is sometimes intrinsic. Interpretability and explainability are related concepts that can easily be confused. When referring to AI and Machine Learning, “Explainable AI models “summarize the reasons […] for [their] behavior […] or produce insights about the causes of their decisions,” whereas Interpretable AI refers to AI systems which “describe the internals of a system in a way which is understandable to humans” [10]
Applied to threat detections, interpretability refers to the ability for a human to understand a detection by looking at the actual detection code and related parameters. For simplicity’s sake we can consider it the “How”. Explainability, on the other hand, is the ability of an organization to understand the reasons that caused a detection to fire, for example which specific behavior or indicators of compromise. We can view this as the “Why”.
In the case of threat detections, explainability could for example mean showing the criteria that caused a connection to be flagged as malicious. Is the concept of explainability transferable for detection-as-code and ML detections?
What would good explainability look like for detection-as-code?
Essentially, anything that analyzes or processes data must at least be explainable, especially when it is intended for decision support or decision automation. As important as this is in the case of AI approaches such as deep learning, it is just as critical for detection-as-code. Even if your detection has a 100% accuracy rate, how can that be verified without sufficient information? And If a human is going to be accountable for these decisions, especially if they plan to fully automate processes, there’s no way around them needing to be able to understand why a decision was made.
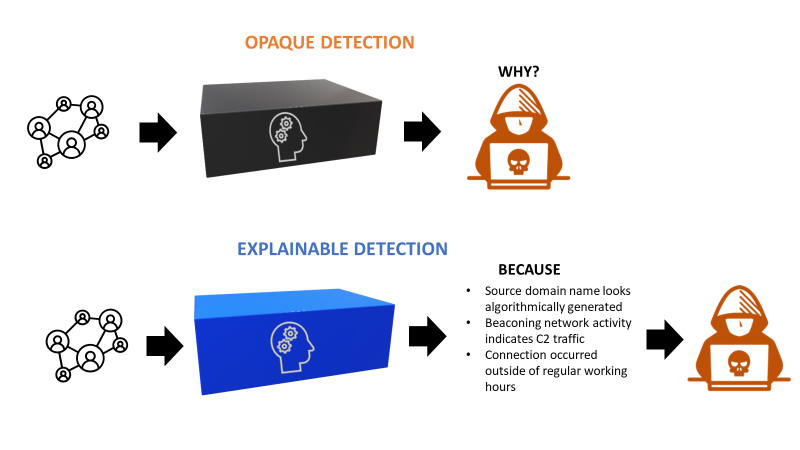
Good explainability will need to meet a list of requirements to be suitable for and effective in modern security operations.
It will need to be detailed and verbose enough to:
- Support troubleshooting efforts in case the outcome of the detection is in doubt.
- Guide any further investigation into the pre and post-stages of whatever activity the detection is flagging.
- Provide any relevant indicators of compromise, or raw event data to facilitate triage and investigations.
- Be suitable to be submitted as evidence in resulting legal and criminal proceedings.
- Meet requirements for regulatory data breach notification obligations.
- Be auditable to meet compliance and risk management mandates.
- Be sufficiently comprehensive to be able to share with and convince other stakeholders, such as IT Operations, HR, Legal, or even external parties such as partners and customers.
Ideally, any opaque detections must also provide insight into operational performance metrics such as accuracy and false positive rates, and describe under what circumstances the detection may fail.
Is Explainability enough, though?
But is explainability really enough though, or do we always also require interpretability, i.e. access to the actual detection code, as well? Does it matter that we can’t interpret in detail how a detection functions if it works effectively? And is it even possible to be truly explainable without exposing all the mechanics of the detection? To bring back the detection as cooking analogy, would you eat the food if it is tasty and the vendor guarantees its safety …but you don’t know what’s inside the package?
Making detections explainable might address some concerns resulting from not having full code access. But this would depend on enough information being provided to not only understand the rationale for a detection triggering, but also permit troubleshooting if it misfired, not to mention support all of the necessary post-detection activity such as incident investigation.
Users will likely critical of the reasons for not being granted access to detection code. There is a fundamental difference between having to accept the limitations of deep learning not being interpretable if it’s the only way to detect a particularly stealthy attack technique, and a vendor trying to prevent competitors seeing how they are detecting badness.
In the case of the former, the trade-off is obvious for a security user — the black box problem is inherent in the approach, and if you want to benefit from it, explainability may be as good as it gets. But a vendor artificially creating a black box means they are prioritizing commercial paranoia over usability. Interpretability should be the ideal and should always be chosen unless technical limitations make it impossible.
Sadly, true positives have become more common, and some users plagued by ransomware and ever more sophisticated attacks may have become more willing and forgiving of opaque detections. But this is likely a temporary state as businesses catch up with the attackers again. If opaque detections are here to stay, vendors will need to develop new and effective ways to achieve transparency and build trust, and that will mean becoming better at making detection results explainable. The detections had better also be more precise and effective than those from competitors who expose the inner workings of their detections, or users will most likely vote with their feet.
To conclude, opaque detections are here to stay, but we need the reliable approaches to confirm that we can trust them. As threats evolve, users plagued by ransomware and more sophisticated attacks may have become more willing and forgiving of opaque detections. But this is likely a temporary state as businesses catch up with the attackers again. If opaque detections are here to stay, vendors will need to develop new and effective ways to achieve transparency and build trust, and that will mean becoming better at making detection results explainable. Also, the opaque detections had better also be dramatically more effective than those from competitors who expose the inner workings of their detections, or users will most likely vote with their feet.
All in all, interesting times ahead for threat detection!
This blog / mini-paper is written jointly with Oliver Rochford.
Related posts
- Detection as Code? No, Detection as COOKING!
- How to Measure Threat Detection Quality for an Organization?
- Why is Threat Detection Hard?
- On Threat Detection Uncertainty
- How to Make Threat Detection Better?
- Role of Context in Threat Detection
- What Are You NOT Detecting?
Endnotes
1. https://www.usenix.org/system/files/sec22summer_alahmadi.pdf
2. https://www.channelfutures.com/mssp-insider/soc-analysts-quitting-over-burnout-lack-of-visibility
3. https://www.securonix.com/blog/thwarting-evasive-attacks-with-behavioral-analysis/
4. https://www.darkreading.com/risk/56-of-large-companies-handle-1-000-security-alerts-each-day
6. https://threatpost.com/cutting-through-the-noise-from-daily-alerts/168319/
8. https://medium.com/anton-on-security/detection-as-code-no-detection-as-cooking-d37278f6533a
9. https://www.tandfonline.com/doi/abs/10.1080/17470919.2019.1696225?journalCode=psns20
10. https://arxiv.org/pdf/1806.00069.pdf
On Trust and Transparency in Detection was originally published in Anton on Security on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from Stories by Anton Chuvakin on Medium authored by Anton Chuvakin. Read the original post at: https://medium.com/anton-on-security/on-trust-and-transparency-in-detection-52ae6a29afdf?source=rss-11065c9e943e------2
