

New Imperva Framework: Accelerating the development of large scale solutions with “Stepping”
Handling large amounts of data at scale is a common task in the high-tech industry nowadays. To address this challenge many frameworks have been developed and made publicly available such as distributed messaging queues, distributed databases, lightweight protocols and caching servers, among others.
These tools and frameworks are already part of the toolkit of any developer. However, these frameworks don’t help us write our in-memory code in an efficient way that deals with the challenges created by handling vast amounts of data. Since we’re still required to write our business logic, algorithms, and other dedicated data processing in order to achieve our teams’ goals, this is a critical part of any system’s efficiency.
When facing a challenge regarding the manipulation of large volumes of data at high scales, we need to take care of many aspects that aren’t directly related to the business value we’re asked to achieve, such as data retrieval, parallel processing, or result persistence.
On top of that, we also care a lot about the performance of our solution. We want to make sure that the latency added by these infrastructures is as minimal as possible.
‘Stepping’ is a framework designed and developed by Imperva to tackle these common issues and ease the implementation of solutions relying heavily on data processing while allowing developers to focus on their real mission, which is usually the implementation of business logic.
In this article, we’ll review the ‘Stepping’ framework at a high level, show how it works, and explain why you should consider using it within your teams.
Data Streaming Challenges
Let’s take a common scenario which all of us have encountered in one way or another: We’re asked to create a data processing solution which is required to fetch data from a certain data source – a MySql DB for instance – serialize it, convert it, process it, and finally flush it to a Kafka cluster.
Before we even start writing the first lines of code we already know that we’ll need to address many technical infrastructure issues that aren’t related to the task we’ve been assigned to, such as serializing and converting the data.
For example, we need to decide how to split the data processing logic into different phases, think about our threading policy, how to handle communication between the different stages, add error handling mechanisms, and more.
One of the most important subjects is the threading policy of our solution. We need to think about how many threads to open, whether we need to distribute the data processing phase to multiple ‘executors’ in parallel, and whether there’s a need for a thread-safe communication layer between the threads.
The amount of infra code in order to achieve all of the above is huge and not always portable between projects, resulting in developing the same solutions over and over again which eventually decreases our development velocity.
‘Stepping’ High Level Architecture and Value
Stepping is an event-driven, multithreaded, thread-safe (lockless) framework that handles the following challenges:
- Handling concurrency and thread safety
- Exposing an easy way to split the entire data-processing logic into small units (called ‘steps’) and making sure that all the units are always occupied and efficient
- Communication between the different parts (Steps) of the solution
- Enabling consumers to split the processed data so that it can be processed in parallel by different units (Steps)
- Exposing an extremely easy API to process logic on top of data-streaming
- Enabling customers to implement custom error handling policies
Let’s take the data processing platform example above. We probably can imagine what our flow will look like at a very high level:
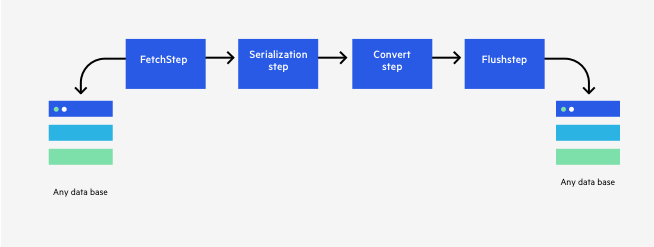
Usually, we’d implement this flow by creating different classes and methods that trigger the flow until the data arrives at the final ‘FlushStep’. Each object is aware of the next object and the method to call, pass certain parameters, process the data, and then flush it somewhere.
But how many threads do we need? Should we work with the same thread that receives the first chunks of data in the ‘FetchStep’ and use it to perform the entire data pipe processing? Or do we need to split the workload to different threads so those threads that perform I/O can continue fetching and flushing data while the CPU threads work on manipulating the data? What happens if the ‘ConvertStep’ needs multiple instances in order to meet the performance requirements? Can we split the work for specific Steps of the algorithm? How can we safely send data to other Steps if the solution uses multiple threads? If required, how can we add another Step in between ‘SerializationStep’ and ‘ConvertStep’? If one or more Steps fails, can we decide whether to continue as if nothing happened or do we kill the process?
These kinds of questions are the reason that we, at Imperva, decided to create the ‘Stepping’ framework.
Internally, ‘Stepping’ contains many players, but in this article we’ll cover only the core ones.
Core Players
Algo
Algo is the first Class to review as it’s the first entry point to the ‘Stepping’ ecosystem. Each Algo represents a set of Steps and is in charge of creating, configuring and initializing each of its Steps.
Each process can host one or more Algos, while the ‘Stepping’ framework makes sure that each Algo and its Steps are completely isolated from each other.
This comes in handy when we want to start hosting multiple Algos in the same process, choosing to move the “busy” Algos to a different process (and a different hardware) only when necessary. This way developers can take advantage of multiple Algos while sharing the same hardware but can easely decide when to split the logic into different processes.
Algo is also the root exception handler in the exception handling chaining flow. When an exception occurs, ‘Stepping’ grants you full control over how to handle it. You can hook into the exception bubbling flow and create your CustomExceptionHandler which will catch any unhandled exception and let you decide whether you want to close your Algo, swallow the exception or do anything else with it. ‘Stepping’ also exposes a way of instructing the system to kill the entire process by throwing a special exception of type SystemCriticalException.
For more information about Exception Handling please click here.
Now that we’ve covered Algo, which acts as a Steps preparator and initializer, we can start reviewing the Step class.
Step
Step represents the actual logic that we want to run – a specific phase of our algorithm.
As in the example above, we’ve split the data processing task into four different phases, each known as a Step.
Steps can’t communicate directly with each other just by calling their function. The communication is event-driven, and implemented as a pub-sub system which enables each Step to be completely autonomous with no knowledge about any other Step. Stepping makes sure that communicating Steps don’t interfere with each other, thereby releasing the Steps as quickly as possible. Behind the scenes, ‘Stepping’ makes use of in-memory queues to handle the incoming messages.
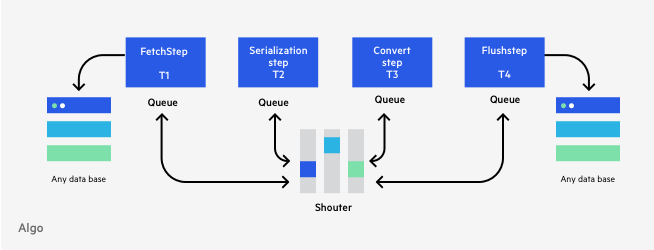
Each Step registers itself to the Subjects (events) it’s interested in, and the framework makes sure that, whenever a Subject is triggered, the registered Steps will be notified. Once a Subject is triggered the relevant Steps get a chance to perform their data processing. With this communication model you can easily add or remove Steps without affecting any other Step – remember, Steps aren’t aware of each other.
For example, imagine that we’re asked to add a new Step that logs all other Steps’ activities into a file. We could just add a LoggerStep that listens to all other Steps’ Subjects to do the job.
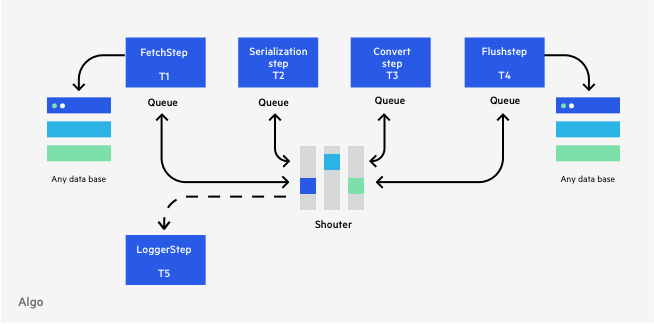
When the data processing stage is done, Steps can notify subscribers (other Steps subscribed to their event) and send them the result of the processing stage so they can execute further logic on the data.
Steps and Threads
‘Stepping’ is multithreaded in the sense that each Step runs in its own thread to maximize efficiency of the Steps. While Step B is busy executing its logic on the data, Step A can start executing its logic on a different chunk of data. Usually there are always threads that perform I/O, so the number of Steps can be greater than the number of cores of the machine.
Splitting the logic into different Steps is important not only to increase the threads’ efficiency, but also for the separation of concerns. Therefore, creating more Steps than the number of cores in the machine is still acceptable unless you create dozens of steps on a four core machine. In this case you might discover that your efficiency actually decreases.
Concurrency Policy
Although each Step works in a dedicated thread, Stepping makes sure that only one thread executes a Step.
This thread policy allows consumers of ‘Stepping’ (Steps’ implementations) to use local variables inside their Steps, as the variables are always accessed by the same single thread, thus avoiding visibility issues between threads.
‘Stepping’ is lockless, meaning that threads’ flow is not controlled by locks which might hurt the concurrency of the program.
Duplicated Nodes
In order to maximize CPU usage, ‘Stepping’ enables consumers to split the workload to multiple threads.
Consumers just need to specify the number of Steps’ nodes and, internally, ‘Stepping’ will create the corresponding number of threads that will work in-parallel on the data in order to increase throughput. This configuration granularity is per Step, which means that we can configure different amounts of nodes per each Step.
‘Stepping’ will ensure the creation of new instances of the duplicated Step.
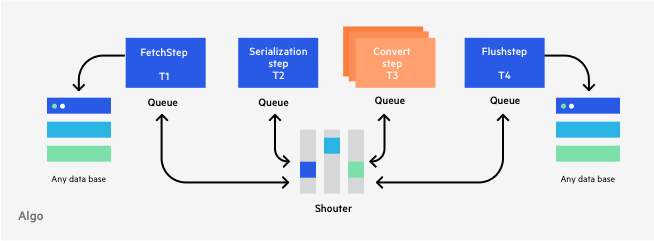
With ‘Stepping’ you can safely start with a single Step node and increase the number of Steps later on without being worried about thread-safety and race conditions. You can just increase or decrease the number of Steps’ nodes.
When you decide to work with multiple Step nodes for the same task you obviously need a way of deciding how to distribute the data between the replicated Steps. ‘Stepping’ has several predefined distribution strategies which you can use out-of-the-box, but it grants you the full power to hook into it the distribution logic via a custom distribution strategy to meet your specific use case.
For more information about Distribution Strategy please click here.
Leveraging Stepping to Accelerate Development in Imperva
We developed the Stepping framework after recognizing the amount of time and effort our teams were spending on the boundaries of the core logic of their products, instead of on the logic itself. Using the “write once, use everywhere” concept, the first to adapt this was the data analytics team, who hold the knowledge and experience of processing, manipulating, and calculating enormous amounts of data into human understandable actionable insights, by using quite complex algorithms. The challenge they were facing was to write and deploy a scalable microservice-based solution that would ingest many billions of database records per day, process them, and output the results.
The nature of such a task is similar to what Stepping has to offer – a pipeline in which there are many steps which each have their own logic, their own scale needs, and that each receive or send data to other steps in the pipeline.
The analytics team used the Stepping framework from day one, allowing them to focus on what really mattered to them – the core logic.
Case study: ETL
Among the microservices developed using Stepping was a pretty straightforward ETL microservice, the purpose of which was to aggregate similar records within a given timeframe, thus reducing the amount of data the microservices down the pipeline need to cope with.
The microservice needed to read records from Kafka, enrich and manipulate the records with metadata coming from another microservice and domain expertise knowledge, aggregate the records based on some common properties, and finally flush the aggregated records every few minutes by writing them to Kafka.
We can break this down to the following steps:
- Extract – read from Kafka
- Transform – enrich and manipulate the records
- Aggregate – hold the records in memory for a predefined time to allow aggregation
- Load – write the records to Kafka
Each one of these steps is an independent unit, with its own scalability characteristics, and with a need to read and write data from and to various steps or systems.
In this project the team needed the flexibility to:
- Scale each step independently
- Detect when the system was overloaded and slow down the incoming volume to a Step until that Step could handle the current load, thus avoiding crashes.
- Have a working flow up and running as fast as possible, so it could be tested and validated. As this was a new microservice, there was a need to “fail fast”.
As early adopters of the Stepping framework, the analytics team provided important feedback for improving it and ramping it up to be production-ready. As an open-source platform, they also contributed to these improvements.
Building the ETL “shell” in Stepping took one day. The flow was in place and the team was able to focus on what each Step did.
The communication between the Steps, the multithreading of each Step, the “main” method – these were all taken care of by the framework.
ETL has been up and running for the past year, processing billions of records per day. Some fine-tuning with scalability, durability, and error handling was added throughout this time, requiring no change to the core logic, just the usage of built-in Stepping mechanisms.
Following the successful use of Stepping in this project, the Analytics team went on to use this framework as the backbone of the next six microservices they developed.
Quoting their Tech Lead: “Our logic and algorithms are complex and require the very best of our focus and attention. Stepping allowed us to do this exactly, while not “wasting” time on all of the very important but, until now, very time-consuming data flow and thread management. Stepping saved us the need to repeatedly write flow management code that is not our main focus or forte”.
Use and Contribute
At this point, you should have an idea of how ‘Stepping’ works and how you can benefit from it. ‘Stepping’ has many other features and infrastructures that can speed up the development of data processing projects. For a full review, more information, and code snippets please visit Imperva’s github repository.
The post New Imperva Framework: Accelerating the development of large scale solutions with “Stepping” appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Gabriel Bayo. Read the original post at: https://www.imperva.com/blog/new-imperva-framework-accelerating-the-development-of-large-scale-solutions/
