
Concentric Applies Deep Learning Algorithms to Data Security
Fresh off raising an additional $7 million in funding, Concentric has launched a tool that employs deep learning algorithms to enable cybersecurity teams to identify documents and repositories where sensitive data has been stored.
Company CEO Karthik Krishnan said the Semantic Intelligence platform takes the place of relying on users to remember where documents containing personally identifiable information (PII) data might be stored, for example. The technology takes less than 30 minutes to install and about a week to learn the overall environment. Once the deep learning algorithms are trained to identify sensitive data, cybersecurity teams can focus their efforts on securing the documents and repositories where that data is stored, he said.
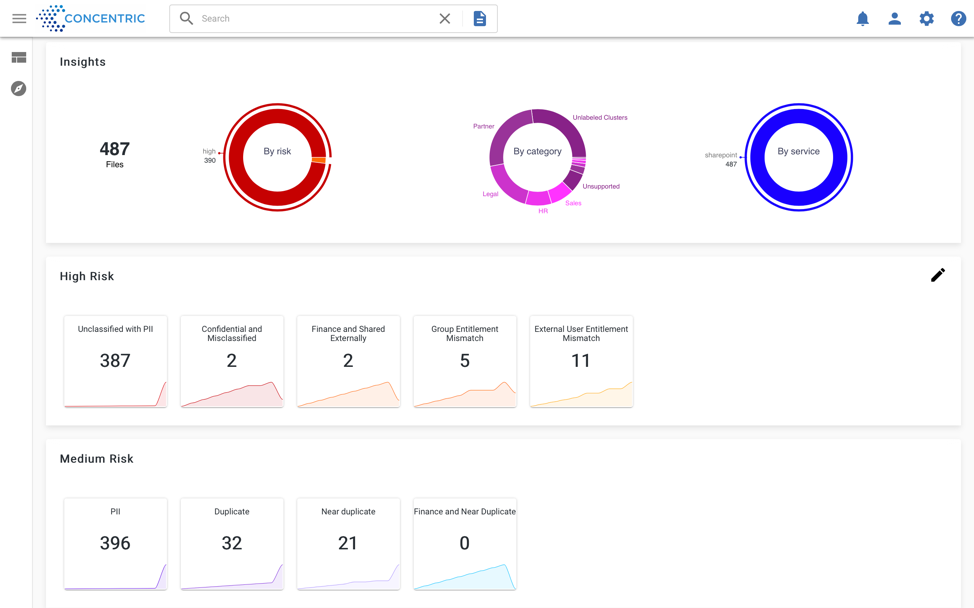
Krishnan said Concentric’s deep learning algorithms, also known as neural networks, have already been employed by beta customers to find millions of unprotected or inappropriately shared documents accessible by thousands of employees.
A business on average has nearly 10 million documents, he said, with 1.2 million documents deemed business-critical. Of those business-critical documents, more than 15% are at risk because of improper sharing with users and groups or inadequate/incorrect data classification. In addition to the inherent cybersecurity risks those documents represent, Krishnan noted organizations could be fined millions of dollars for breaching any number of compliance mandates.
Cybersecurity and compliance teams have wrestled with data classification issues for decades. Most processes are deeply flawed because they rely on end users to determine how sensitive a document might be. Over time, the number of documents that are misclassified even though they may include, for example, Social Security numbers starts to multiply. Rather than rely on end users, Concentric is making the case for employing artificial intelligence (AI) in the form of deep learning algorithms to determine the appropriate level of classification for any document and identify which policies should be applied, said Krishnan.
The existence of an AI tool to classify data should not absolve end users of the responsibility to classify data. However, given that people make mistakes or simply forget, an AI tool will enable cybersecurity and compliance teams to enforce policies at a more granular level without having to disrupt the business. That capability is becoming a fundamental requirement as regulations such as the General Data Protection Rule (GDPR) and California Consumer Privacy Act (CCPA) raise the stakes involving almost any type of data breach or even accidental sharing of sensitive data.
While there’s obviously a lot of hype surrounding AI these days, it’s arguably in the realm of rote tasks where algorithms can prove most effective. The more narrowly focused the task, the more accurate algorithms tend to become. Of course, the more the humans employed to train algorithms know about a process, the faster the AI system tends become effective. The challenge now is cutting through all the hype to identify practical use cases for AI. Arguably, data classification along with other data security and data management functions make an ideal area of initial focus.
