

How Our Threat Analytics Multi-Region Data Lake on AWS Stores More, Slashes Costs

Data is the lifeblood of digital businesses, and a key competitive advantage. The question is: how can you store your data cost-efficiently, access it quickly, while abiding by privacy laws?
At Imperva, we wanted to store our data for long-term access. Databases would’ve cost too much in disk and memory, especially since we didn’t know much it would grow, how long we would keep it, and which data we would actually access in the future. The only thing we did know? That new business cases for our data would emerge.
That’s why we deployed a data lake. It turned out to be the right decision, allowing us to store 1,000 times more data than before, even while slashing costs.

What is a data lake?
A data lake is a repository of files stored in a distributed system. Information is stored in its native form, with little or no processing. You simply store the data in its native formats, such as JSON, XML, CSV, or text.
Analytics queries can be run against both data lakes and databases. In a database you create a schema, plan your queries, and add indices to improve performance. In a data lake, it’s different — you simply store the data and it’s query-ready.
Some file formats are better than others, of course. Apache Parquet allows you to store records in a compressed columnar file. The compression saves disk space and IO, while the columnar format allows the query engine to scan only the relevant columns. This reduces query time and costs.
Using a distributed file system lets you store more data at a lower cost. Whether you use Hadoop HDFS, AWS S3, or Azure Storage, the benefits include:
- Data replication and availability
- Options to save more money – for example, AWS S3 has different storage options with different costs
- Retention policy – decide how long you want to keep your data before it’s automatically deleted
No wonder experts such as Adrian Cockcroft, VP of cloud architecture strategy at Amazon Web Services, said this week that “cloud data lakes are the future.”

Analytic queries: data lake versus database
Let’s examine the capabilities, advantages and disadvantages of a data lake versus a database.
The data
A data lake supports structured and unstructured data and everything in-between. All data is collected and immediately ready for analysis. Data can be transformed to improve user experience and performance. For example, fields can be extracted from a data lake and data can be aggregated.
A database contains only structured and transformed data. It is impossible to add data without declaring tables, relations and indices. You have to plan ahead and transform the data according to your schema.
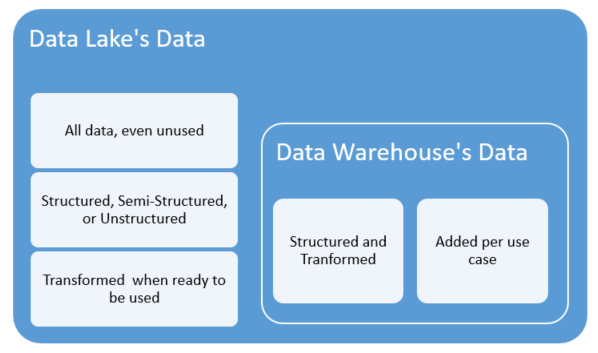
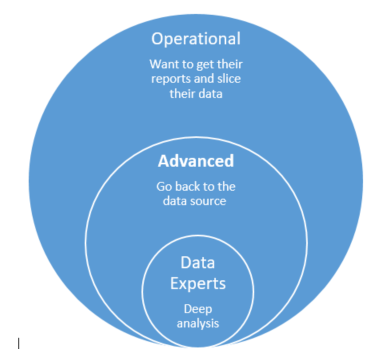
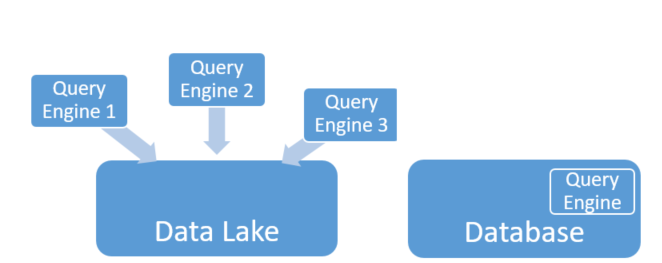
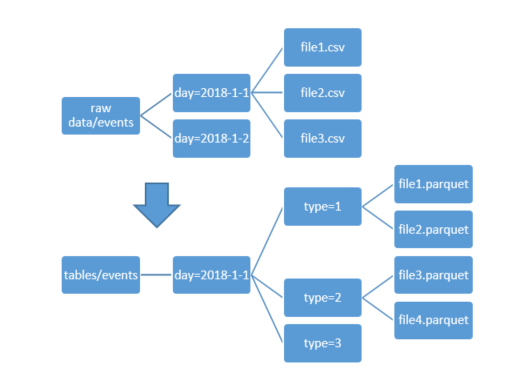
Figure 1: Data Lake versus Database
The Users
Most users in a typical organization are operational, using applications and data in predefined and repetitive ways. A database is usually ideal for these users. Data is structured and optimized for these predefined use-cases. Reports can be generated, and filters can be applied according to the application’s design.
Advanced users, by contrast, may go beyond an application to the data source and use custom tools to process the data. They may also bring in data from outside the organization.
The last group are the data experts, who do deep analysis on the data. They need the raw data, and their requirements change all the time.
Data lakes support all of these users, but especially advanced and expert users, due to the agility and flexibility of a data lake.
Figure 2: Typical user distribution inside an organization
Query engine(s)
In a database, the query engine is internal and is impossible to change. In a data lake, the query engine is external, letting users choose based on their needs. For example, you can choose Presto for SQL-based analytics and Spark for machine learning.
Figure 3: A data lake may have multiple external query engines. A database has a single internal query engine.
Support of new business use-case
Database changes may be complex. Data should be analyzed and formatted, while schema has to be created before data can be inserted. If you have a busy development team, users can wait months or a year to see the new data in their application.
Few businesses can wait this long. Data lakes solve this by letting users go beyond the structure to explore data. If this proves fruitful, than a formal schema can be applied. You get to results quickly, and fail fast. This agility lets organizations quickly improve their use cases, better know their data, and react fast to changes.
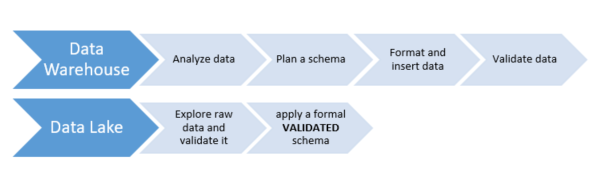
Figure 4: Support of new business use-case
Data lake structure
Here’s how data may flow inside a data lake.
Figure 5: Data lake structure and flow
In this example, CSV files are added to the data lake to a “current day” folder. This folder is the daily partition which allows querying a day’s data using a filter like day = ‘2018-1-1’. Partitions are the most efficient way to filter data.
The data under tables/events is an aggregated, sorted and formatted version of the CSV data. It uses the parquet format to improve query performance and for compression. It also has an additional “type” partition, because most queries work only on a single event type. Each file has millions of records inside, with metadata for efficiency. For example, you can know the count, min and max values for all of the columns without scanning the file.
This events table data has been added to the data lake after the raw data has been validated and analyzed.
Here is a simplified example of CSV to Parquet conversion:
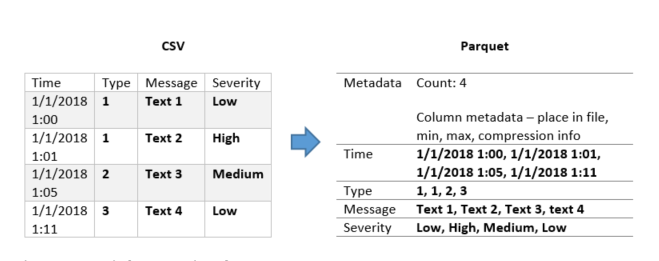
Figure 6: Example for conversion of CSV to Parquet
Parquet files normally hold large number of records, and can be divided internally into “row groups” which have their own metadata. Repeating values improves compression and the columnar structure allows scanning only the relevant columns. The CSV data can be queried at any time, but it is not as efficient as querying the data under the tables/events data.
Flow and Architecture
General
Imperva’s data lake uses Amazon Web Services (AWS). Below shows the flow and services we used to build it.
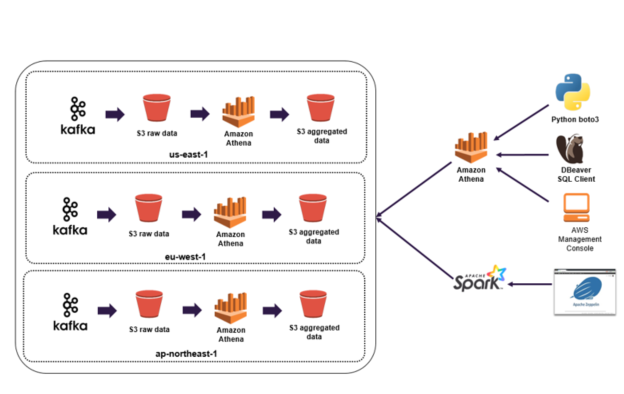
Figure 7: Architecture and flow
Adding data (ETL – Extract -> Transform -> Load)
- We use Kafka, which is a producer-consumer distributed streaming platform. Data is added to Kafka, and later read by a microservice which create raw Parquet files in S3.
- Another microservice uses AWS Athena to hourly or daily process the data – filter, partition, and sort and aggregate it into new Parquet files
- This flow is done on each of the AWS regions we support
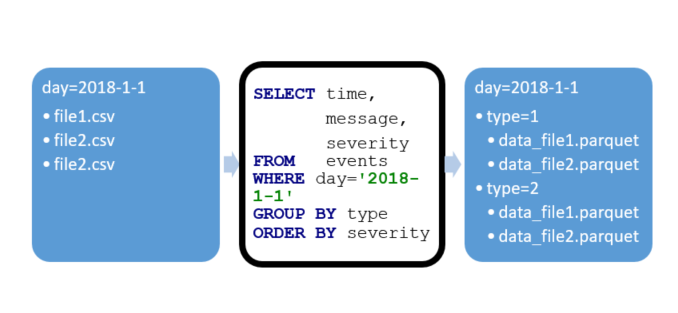
Figure 8: SQL to Parquet flow example
Technical details:
- Each partition creation is done by one or more Athena:
- Creating a Table from Query Results (CTAS).
- Process the results by code for more complex data transformation
- Each query result with one more more Parquet files
- ETL microservices run on a Kubernetes cluster per region. They are developed and deployed using our development pipeline.
Uses:
- Different microservices consume the aggregated data using Athena API through boto3 Python library
- Day to day queries are done using SQL client like DBeaver with Athena JDBC driver. Athena AWS management console is also used for SQL queries
- Apache Spark engine is used to run spark queries, including machine learning using the spark-ml Apache Zeppelin is used as a client to run scripts and display visualization. Both Spark and Zeppelin are installed as part of AWS EMR service.
Multi-region queries
Data privacy regulations such as GDPR add a twist, especially since we store data in multiple regions. There are two ways to perform multi-region queries:
- Single query engine based in one of the regions
- Query engine per region – get results per region and perform an aggregation
With a single query engine you can run SQL on data from multiple regions, BUT data is transferred between regions, which means you pay both in performance and cost.
With a query engine per region you have to aggregate the results, which may not be a simple task.
With AWS Athena – both options are available, since you don’t need to manage your own query engine.
Threat Analytics Data Lake – before and after
Before the data lake, we had several database solutions – relational and big data. The relational database couldn’t scale, forcing us to delete data or drop old tables. Eventually, we did analytics on a much smaller part of the data than we wanted.
With the big data solutions, the cost was high. We needed dedicated servers, and disks for storage and queries. That’s overkill: we don’t need server access 24/7, as daily batch queries work fine. We also did not have strong SQL capabilities, and found ourselves deleting data because we did not to pay for more servers.
With our data lake, we get better analytics by:
- Storing more data (billions of records processed daily!), which is used by our queries
- Using SQL capabilities on a large amount of data using Athena
- Using multiple query engines with different capabilities, like Spark for machine learning
- Allowing queries on multiple regions for an average, acceptable response time of just 3 seconds
In addition we also got the following improvements:
- Huge cost reductions in storage and compute
- Reduced server maintenance
In conclusion – a data lake worked for us. AWS services made it easier for us to get the results we wanted at an incredibly low cost. It could work for you, depending on factors such as the amount of data, its format, use cases, platform and more. We suggest learning your requirements and do a proof-of-concept with real data to find out!
The post How Our Threat Analytics Multi-Region Data Lake on AWS Stores More, Slashes Costs appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Ori Nakar. Read the original post at: https://www.imperva.com/blog/how-our-threat-analytics-multi-region-data-lake-on-aws-stores-more-slashes-costs/
