

Understanding the Risks of Long-Lived Kubernetes Service Account Tokens
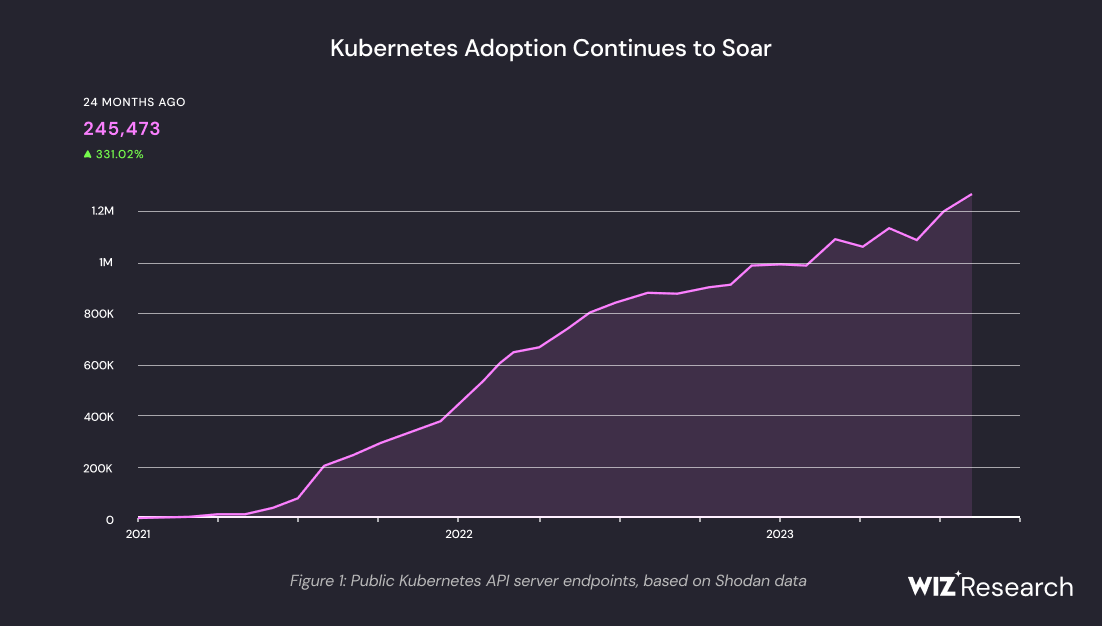
The popularity of Kubernetes (K8s) as the defacto orchestration platform for the cloud is not showing any sign of pause. This graph, taken from the 2023 Kubernetes Security Report by the security company Wiz, clearly illustrates the trend:
As adoption continues to soar, so do the security risks and, most importantly, the attacks threatening K8s clusters. One such threat comes in the form of long-lived service account tokens. In this blog, we are going to dive deep into what these tokens are, their uses, the risks they pose, and how they can be exploited. We will also advocate for the use of short-lived tokens for a better security posture.
What Are Kubernetes Service Account Tokens?
Service account tokens are bearer tokens (a type of token mostly used for authentication in web applications and APIs) used by service accounts to authenticate to the Kubernetes API. Service accounts provide an identity for processes (applications) that run in a Pod, enabling them to interact with the Kubernetes API securely.
Crucially, these tokens are long-lived: when a service account is created, Kubernetes automatically generates a token and stores it indefinitely as a Secret, which can be mounted into pods and used by applications to authenticate API requests.
As a reminder, the Kubelet on each node is responsible for mounting service account tokens into pods, so they can be used by applications within those pods to authenticate to the Kubernetes API when needed:
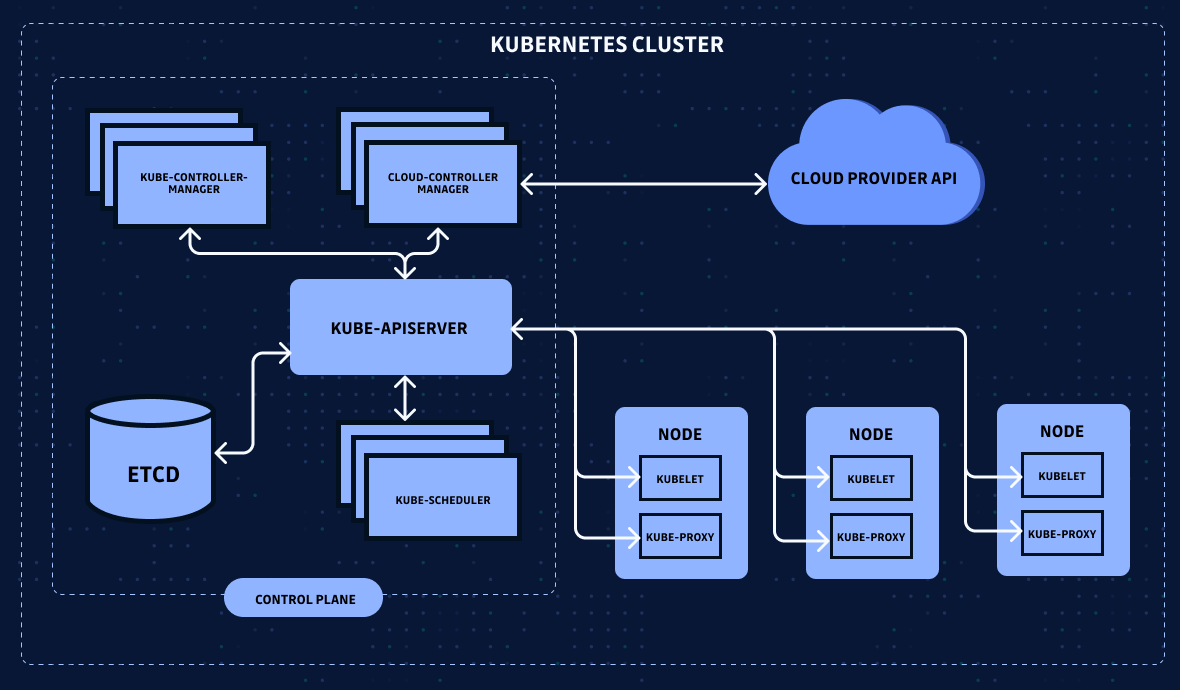
If you need a refresher on K8s components, look here.
The Utility of Service Account Tokens
Service account tokens are essential for enabling applications running on Kubernetes to interact with the Kubernetes API. They are used to deploy applications, manage workloads, and perform administrative tasks programmatically. For instance, a Continuous Integration/Continuous Deployment (CI/CD) tool like Jenkins would use a service account token to deploy new versions of an application or roll back a release.
The Risks of Longevity
While service account tokens are indispensable for automation within Kubernetes, their longevity can be a significant risk factor. Long-lived tokens, if compromised, give attackers ample time to explore and exploit a cluster. Once in the hands of an attacker, these tokens can be used to gain unauthorized access, elevate privileges, exfiltrate data, or even disrupt the entire cluster's operations.
Here are a few leak scenarios that could lead to some serious damage:
– Misconfigured Access Rights: A pod or container may be misconfigured to have broader file system access than necessary. If a token is stored on a shared volume, other containers or malicious pods that have been compromised could potentially access it.
– Insecure Transmission: If the token is transmitted over the network without proper encryption (like sending it over HTTP instead of HTTPS), it could be intercepted by network sniffing tools.
– Code Repositories: Developers might inadvertently commit a token to a public or private source code repository. If the repository is public or becomes exposed, the token is readily available to anyone who accesses it.
– Logging and Monitoring Systems: Tokens might get logged by applications or monitoring systems and could be exposed if logs are not properly secured or if verbose logging is accidentally enabled.
– Insider Threat: A malicious insider with access to the Kubernetes environment could extract the token and use it or leak it intentionally.
– Application Vulnerabilities: If an application running within the cluster has vulnerabilities (e.g., a Remote Code Execution flaw), an attacker could exploit this to gain access to the pod and extract the token.
How Could an Attacker Exploit Long-Lived Tokens?
Attackers can collect long-lived tokens through network eavesdropping, exploiting vulnerable applications, or leveraging social engineering tactics. With these tokens, they can manipulate Kubernetes resources at their will. Here is a non-exhaustive list of potential abuses:
– Abuse the cluster's (often barely limited) infra resources for cryptocurrency mining or as part of a botnet.
– With API access, attackers could deploy malicious containers, alter running workloads, exfiltrate sensitive data, or even take down the entire cluster.
– If the token has broad permissions, it can be used to modify roles and bindings to elevate privileges within the cluster.
– The attacker could create additional resources that provide them with persistent access (backdoor) to the cluster, making it harder to remove their presence.
– Access to sensitive data stored in the cluster or accessible through it could lead to data theft or leakage.
Why Aren’t Service Account Tokens Short-Lived by Default?
Short-lived tokens are a security best practice in general, particularly for managing access to very sensitive resources like the Kubernetes API. They reduce the window of opportunity for attackers to exploit a token and facilitate better management of permissions as application access requirements change. Automating token rotation limits the impact of a potential compromise and aligns with the principle of least privilege—granting only the access necessary for a service to operate.
The problem is that implementing short-lived tokens comes with some overhead.
First, implementing short-lived tokens typically requires a more complex setup. You need an automated process to handle token renewal before it expires. This may involve additional scripts or Kubernetes operators that watch for token expiration and request new tokens as necessary.
This often means integrating a secret management system that can securely store and automatically rotate the tokens. This adds a new dependency for system configuration and maintenance.
Second, software teams running their CI/CD workers on top of the cluster will need adjustments to support dynamic retrieval and injection of these tokens into the deployment process. This could require changes in the pipeline configuration and additional error handling to manage potential token expiration during a pipeline run, which can be a true headache.
And secrets management is just the tip of the iceberg. You will also need monitoring and alerts if you want to troubleshoot renewal failures. Fine-tuning token expiry time could break the deployment process, requiring immediate attention to prevent downtime or deployment failures.
Finally, there could also be performance considerations, as many more API calls are needed to retrieve new tokens and update the relevant Secrets.
By default, Kubernetes opts for a straightforward setup by issuing service account tokens without a built-in expiration. This approach simplifies initial configuration but lacks the security benefits of token rotation. It is the Kubernetes admin’s responsibility to configure more secure practices by implementing short-lived tokens and the necessary infrastructure for their rotation, thereby enhancing the cluster's security posture.
Mitigation Best Practices
For many organizations, the additional overhead is justified by the security improvements. Tools like service mesh implementations (e.g., Istio), secret managers (e.g., CyberArk Conjur), or cloud provider services can manage the lifecycle of short-lived certificates and tokens, helping to reduce the overhead.
Additionally, recent versions of Kubernetes offer features like the TokenRequest API, which can automatically rotate tokens and project them into the running pods.
Even without any additional tool, you can mitigate the risks by limiting the Service Account auto-mount feature. To do so, you can opt out of the default API credential automounting with a single flag in the service account or pod configuration. Here are two examples:
- For a Service Account:
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-robot
automountServiceAccountToken: false
...
- And for a specific Pod:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
serviceAccountName: build-robot
automountServiceAccountToken: false
...The bottom line is that if an application does not need to access the K8s API, it should not have a token mounted. This also limits the number of service account tokens an attacker can access if the attacker manages to compromise any of the Kubernetes hosts.
Okay, you might say, but how do we enforce this policy everywhere? Enter Kyverno, a policy engine designed for K8s.
Enforcement with Kyverno
Kyverno allows cluster administrators to manage, validate, mutate, and generate Kubernetes resources based on custom policies. To prevent the creation of long-lived service account tokens, one can define the following Kyverno policy:
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: deny-secret-service-account-token
spec:
validationFailureAction: Enforce
background: false
rules:
- name: check-service-account-token
match:
any:
- resources:
kinds:
- Secret
validate:
cel:
expressions:
- message: "Long lived API tokens are not allowed"
expression: >
object.type != "kubernetes.io/service-account-token"
This policy ensures that only Secrets that are not of type kubernetes.io/service-account-token can be created, effectively blocking the creation of long-lived service account tokens!
Applying the Kyverno Policy
To apply this policy, you need to have Kyverno installed on your Kubernetes cluster (tutorial). Once Kyverno is running, you can apply the policy by saving the above YAML to a file and using kubectl to apply it:
kubectl apply -f deny-secret-service-account-token.yamlAfter applying this policy, any attempt to create a Secret that is a service account token of the prohibited type will be denied, enforcing a safer token lifecycle management practice.
Wrap up
In Kubernetes, managing the lifecycle and access of service account tokens is a critical aspect of cluster security. By preferring short-lived tokens over long-lived ones and enforcing policies with tools like Kyverno, organizations can significantly reduce the risk of token-based security incidents. Stay vigilant, automate security practices, and ensure your Kubernetes environment remains robust against threats.
*** This is a Security Bloggers Network syndicated blog from GitGuardian Blog - Automated Secrets Detection authored by Thomas Segura. Read the original post at: https://blog.gitguardian.com/understanding-the-risks-of-long-lived-kubernetes-service-account-tokens/
