

Baffle’s Proxy Architecture
Proxy versus Agent and API-based architectures
Baffle implements database encryption and role-based access control using a reverse proxy configuration that operates at the SQL session layer. This blog will explore what that means and compare it to competing API and agent-based architectures.
Before we dive into the details, we have to understand the goals behind enabling database encryption and access control.
No Code Changes
One of the biggest challenges to adding encryption and access control to an existing system is any requirement to modify existing code. Modifying code in applications not only requires development resources, but extensive testing before being put into production. Older applications may be further hampered by the use of technology and code that no one in the organization is still familiar with. And most third-party application code can’t be modified at all.
One of Baffle’s key advantages is there are no code modifications necessary. . With Baffle, you can have encryption and access controls implemented in hours, while a solution that requires code changes is still trying to find the old code repositories.
Database vs Application Encryption and Centralized Control
Several databases provide their own options for database encryption. A primary example is transparent data encryption (TDE). Cloud providers also include database encryption called full disk encryption (FDE), often enabled by default. Regardless of whether you use TDE or FDE, on retrieval the data is decrypted “transparently”, making it easy for users, but therein lies the security problem. There is no access control using the encryption. Any user with SELECT permission gets the data decrypted automatically.
This model was invented back when physical theft of the hard drive was the primary concern. Though important to consider, most CISOs are not losing sleep over physical theft of hard drives these days. Most data breaches today involve stolen credentials of authorized users ,often a database admin, and remote access. The solution is to encrypt and decrypt the data outside of the database such that direct attacks on the database – remote or physical – are not an issue.
There are other reasons to encrypt and provide access control outside of the database. The concept of least privilege means that the database administrator shouldn’t have access to data they don’t need to do their jobs. This includes virtually any personally identifiable information (PII), personal health information (PHI) payment card information (PCI), and proprietary organization information like finances, intellectual property, strategic marketing, and roadmap planning. By encrypting and providing access control outside of the database, this separation of duties is now possible. Not only that, if moving databases to the cloud, all the major cloud providers have similar policies where the infrastructure is their responsibility, but the data security and privacy remain the responsibility of their customers.
Here are the responsibilities straight from Azure’s website. AWS and GCP are virtually identical. Data is #1 and access control is #3 on the items that they never manage.
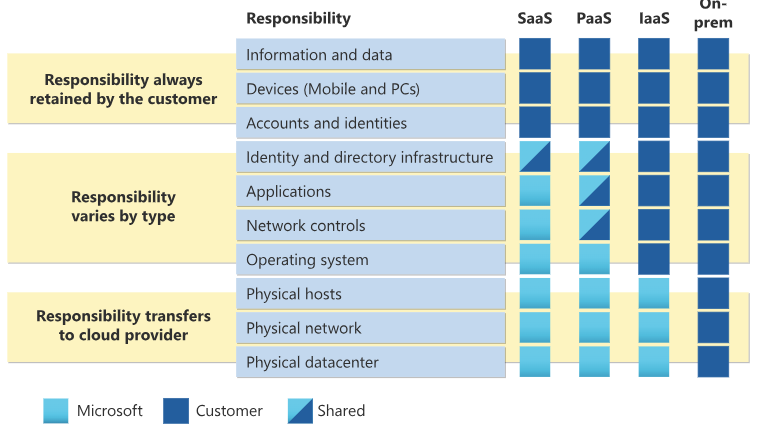
Figure 1. Azure Responsibility Matrix
Finally, encryption at the database level marks it difficult to provide centralized control over the data across multiple databases and data pipelines. By moving the access control outside of the database, centralized control of access for accounts and identities becomes easier.
Exact match vs complex SQL queries.
An “exact match” means that a SQL query is asking for data in a field or fields where no further processing on the encrypted data is required such as a query that reads a given person’s social security number. “Complex queries” include anything that requires processing on the encrypted data before the results can be returned. This includes any sort, search, or mathematical operations. An example would be to find the average insulin level of people with diabetes. In this example, first the diabetes patients have to be identified and then their insulin levels have to be averaged. Either or both of these fields are going to be encrypted to protect the PHI, posing a dilemma to most encryption systems. Baffle’s Advanced Encryption provides the ability to do complex queries on encrypted data. The industry refers to the ability to do queries on encrypted data as “privacy enhanced computation” or PEC.
Unified Encryption and Tokenization Solution
Some offerings provide encryption one way and tokenization a different way. Tokenization is defined here as different from encryption in that the ciphertext has to match the data type and length of the plaintext. This is required in many applications or testing of applications because they may not be able to handle the change in ciphertext data type using traditional encryption. For example, the application may be expecting a nine-digit social security number, and if encrypted data that looks like this: ºÿ ü’ `Gê¢íæ ¯` ÁG$v Ý Ð×VS+zö ù …, then it may error.
Baffle uses format preserving encryption (FPE) to tokenize data. This enables traditional encryption and tokenization to be handled in the same way – through an algorithm – such that additional infrastructure is not required. The other architectures discussed below do not preclude using FPE. However, many vendors have implemented tokenization by randomly assigning a token to each piece of sensitive data and then tracking them in a look-up table, often also called a “vault.” This vault is in reality another database that is potentially as large as the original database and therefore opens its own cost, management, performance, and security issues. In the agent and API architectures discussed below, imagine that tokenization requires additional calls to the look-up table to return the token or original values. With Baffle’s FPE, there is no reason to have two separate systems for traditional encryption vs tokenization.
Agent Architecture
Figure 2 shows an agent-based architecture. Here, the client hosting the application has a separate program (agent) that intercepts the communications between original application and database, which can happen at the application or database driver-level.
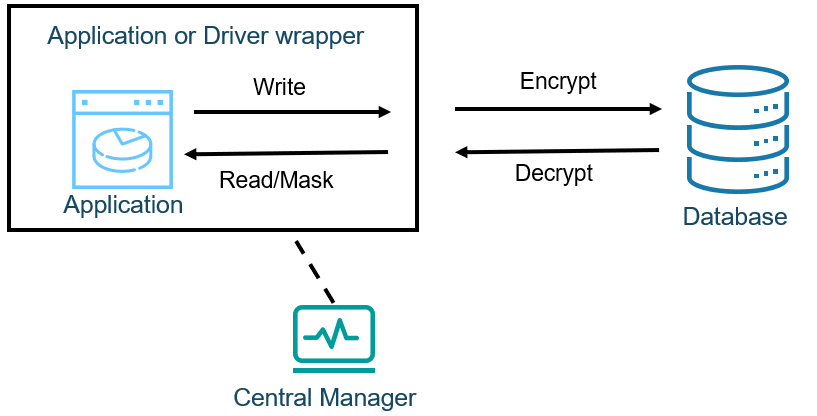
Figure 2. Agent Based Architecture
This architecture can provide a no code solution. It also has the least number of network trips (one) of the three architectures discussed.
However, the agent approach has issues of its own. Many security products today come with agents and management of them becomes very complex over time. When the solution is first deployed, all the client devices have to be accessed for installation. They may be spread all over the world and if they are employee devices, they may not always be on the network. Regular updates have to be deployed as well and those always come with the risks of compatibility issues with the OS, applications, drivers, and other installed agents such as anti-virus software. The interception of communications is a common goal of malware, so behavior-based anti-virus may cause such conflicts.
Finally, it isn’t clear how complex queries could be handled at all. If the application sends a query to the database asking to sort the data, for example, the sort would be on encrypted data and therefore nonsensical. Additional infrastructure is required on the database to implement any complex query solutions.
Application Programming Interface (API) architecture
Figure 3 shows an application programming interface (API) based architecture. On the left side is a write operation where the application first sends the sensitive data to the API for encryption, receives the ciphertext, and then performs the write operation to the database. On the right side is a read operation, where the application pulls the ciphertext from the database, then to the API for decryption, and finally receives the plaintext.
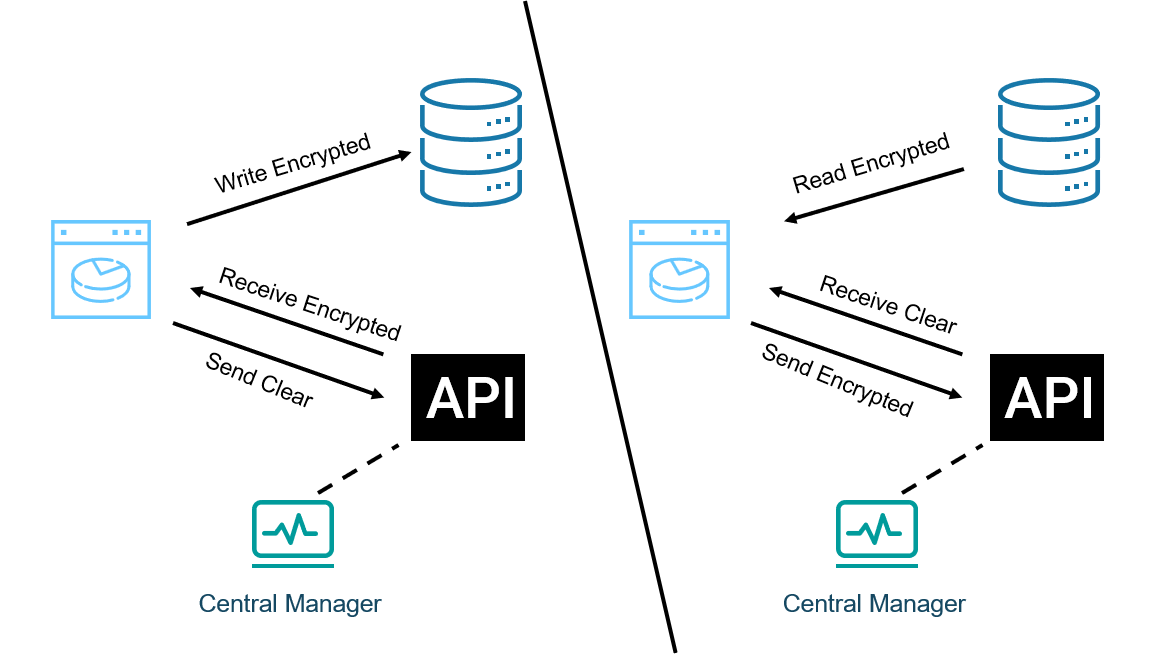
Figure 3: Left Side, API Write. Right Side, API Read
The first issue to notice is the data has to make three trips across the network. Of the three architectures noted, the API approach has the most and could contribute to overall performance issues.
The next issue is that existing applications must be modified to include the API call. This means code changes that may be difficult to incorporate or not even possible at all. If code changes are possible, there is more to it than simply adding the API calls. The application has to have knowledge of what information is sensitive and therefore must be encrypted/decrypted. This is difficult to implement in one application, but further complicated if multiple applications are involved. There is no industry standard for implementing the API calls, so the code has to be unique to the vendor, causing potential vendor lock-in.
Just like the API architecture, it isn’t clear how complex queries could be handled at all. If the application sends a query to the database asking to sort the data, for example, the sort would be on encrypted data and therefore nonsensical. Additional infrastructure is required on the database to implement any complex query solutions.
Baffle’s Proxy Architecture
Figure 4 shows the Baffle reverse proxy architecture. At the highest level, the idea is to intercept the communications between the application and database to encrypt on write and decrypt (or mask) on read while having no impact to the application or database. In practice, the only application change required is to the connection string. On the database side, when Baffle Shield connects, it inserts a unique table that translates between the data type of the plaintext data and the data type of the encrypted data.
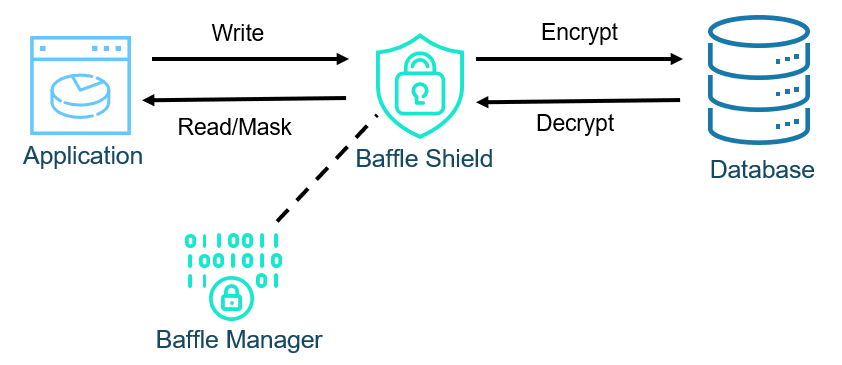
Figure 4: Baffle Proxy Architecture
The above solution is fantastic for direct match use cases. However, it is very common for customers to realize that complex queries are required as well. Figure 5 shows how Baffle implements complex queries using Advanced Encryption. The database proxy monitors the queries going to the database. Queries involving only non-encrypted data are passed through. Direct match queries on sensitive data are decrypted or masked as usual. However, complex queries involving encrypted data are intercepted and sent to user-defined functions (UDF) in the database. Here, the encrypted data is pulled into the UDF for processing and then the results are returned. The UDF never stores any decrypted data and the memory is not accessible to any database users through standard means.
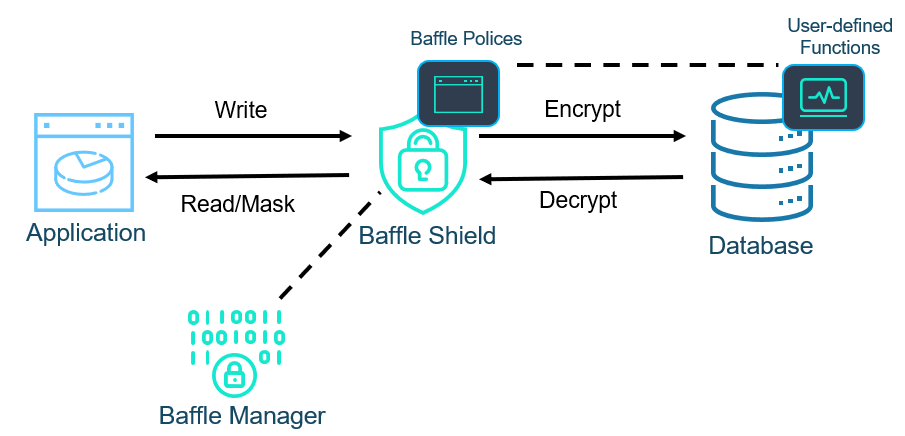
Figure 5: Baffle Proxy Architecture For Advanced Encryption
In the past, the UDF approach was not compatible with cloud managed database offerings like AWS’s RDS or Aurora. However, they have recently opened up this option to “procedural languages” such as RUST implementations. Baffle is currently working to implement this approach for our first customers.
Beyond encryption and tokenization, Baffle can provide dynamic data masking for real-time access controls. This means each application or even application user can be assigned a role and that role determines how the sensitive data is returned. For example, an employee social security number may be fully decrypted for an administrator in human resources, but anybody else in HR gets a partially masked version (XXX-XX-1234) and anybody outside of HR gets a fully masked version (**confidential**).
Baffle also handles all the encryption key mapping so your application doesn’t have to. And with our two-tiered key management system, bring your own key (BYOK) is enabled. This is even extended to tenants on your multi-tenant SaaS application through our record-level key feature (every record in a given column is encrypted with its own key) and logical-database key feature (every logical database in an instance is encrypted with its own key). This enables your SaaS to scale while logically isolating your tenant data with encryption.
The final note on Baffle’s architecture is its flexibility. The database proxy is deployed as a container, allowing server or Kubernetes-based deployments. The containers may be deployed 1:1 with applications or 1:many. Both vertical and horizontal scaling are possible as well and any HA/DR configurations that are required. Baffle Manager provides centralized configuration, management, and reporting of the database proxies.
Baffle’s reverse proxy architecture is a pragmatic balance between cost, implementation, agility, scale, and data security.
Contact Baffle for a demo
The post Baffle’s Proxy Architecture appeared first on Baffle.
*** This is a Security Bloggers Network syndicated blog from Baffle authored by Billy VanCannon, Director of Product Management. Read the original post at: https://baffle.io/blog/baffles-proxy-architecture/
