

Testing the Waters: First Impressions of CloudTrail Lake
AWS just announced CloudTrail Lake, in their words: “…a managed audit and security lake that allows you to aggregate, immutably store, and query your activity logs for auditing, security investigation, and operational troubleshooting.” (from the blog post announcing CloudTrail Lake)
Breaking that up:
- Aggregate activity logs: Basically – collect all or some of your CloudTrail logs (across regions, and across accounts) in one place.
- Storage (immutable, long-term): Store files for seven years such that they can’t be modified.
- Querying: Run SQL queries on the data.
So, CloudTrail Lake is a fully-functional, standalone managed service, independent of a traditional CloudTrail setup, that collects CloudTrail activity logs, handles their secure, immutable, long-term storage, and lets you run SQL queries on them. In theory, this may seek to replace, at least partially, the traditional CloudTrail deployment: “This removes the need to maintain separate data processing pipelines that span across teams and products to analyze CloudTrail events.” (from the blog post). In practice, it can be deployed alongside CloudTrail.
As a big CloudTrail aficionado, I decided to take it for a spin and share my impressions.
TL;DR:
- For customers who don’t have a solution for querying (and safely storing) CloudTrail logs, this is an easy solution that can get them up and running quickly and simply. That’s pretty cool, and for a lot of AWS customers, a big step forward.
- At least for now, in my opinion, it probably won’t replace comprehensive log querying solutions that more mature organizations have deployed.
The Alternative
The in-house AWS alternative to CloudTrail Lake is to use a CloudTrail Trail writing encrypted (KMS/SSE-S3) logs to an S3 Bucket queried with Athena with encrypted results going to an S3 Bucket. For more advanced customers, the AWS solution is Athena Bootstrap. The first two pieces of this puzzle are about logging and storage and they are constant, the last two pieces are about querying and analysis – and here while Athena (and CloudWatch Events, CloudWatch Insights and CloudTrail Insights) are the solutions inside AWS, there are many 3rd-party solutions, such as: Splunk, DataDog, Sumologic, and our own Ermetic activity log.
Setup
Quick Setup
AWS CloudTrail Lake setup is easy, you can set up completely in about 5 minutes. The user guide has a complete walkthrough, but just to give you an impression of how easy it was:
- Go to CloudTrail in the console.
- Click “Lakes” on the sidebar.
- Click “Create Data Event Store”.

- Type in a name, tick enable for all accounts in my organization, click next.

- Click next on the default options, management events only, read and write.

- Click “Create event data store”.
And… we’re done! 7 clicks to get set up with a lake for management events in all regions, in the entire organization, ready to run SQL queries. No worrying about an S3 bucket, encryption settings, storage lifecycle, etc. That’s a win in my book.
Advanced Setup
Let’s discuss some of the options we’ve skipped along the way when next-next-nexting our way through setup. some are rather standard options:
- Single-account event store
- Single-region event store (but it has to be the current region)
- Excluding KMS event and RDS Data API events
- Data events, selected and filtered with the same mechanism as CloudTrail
This is basically (almost) feature parity with cloudtrail, the only difference seems to be that in CloudTrail, we get to pick the regions for the event sources, the trail, and the S3 bucket, and they don’t all have to be in the same region.
The biggest difference in the setup stage is that an organizational trail can only be set up from the management account. This somewhat goes against the best practices of keeping logging in a separate account, and of only doing in the management account what is absolutely necessary.
Ease of Use
We’ve seen how easy it is to set up a CloudTrail Lake; once set up, querying is also easy, if you are sufficiently proficient in SQL. No need to create a bucket for Athena results, recent queries and results are saved, and a very short (but handy) list of sample queries is provided to get us started. However, if you don’t like SQL, aren’t proficient, or would like a different query language or perhaps a GUI – better get accustomed to SQL.
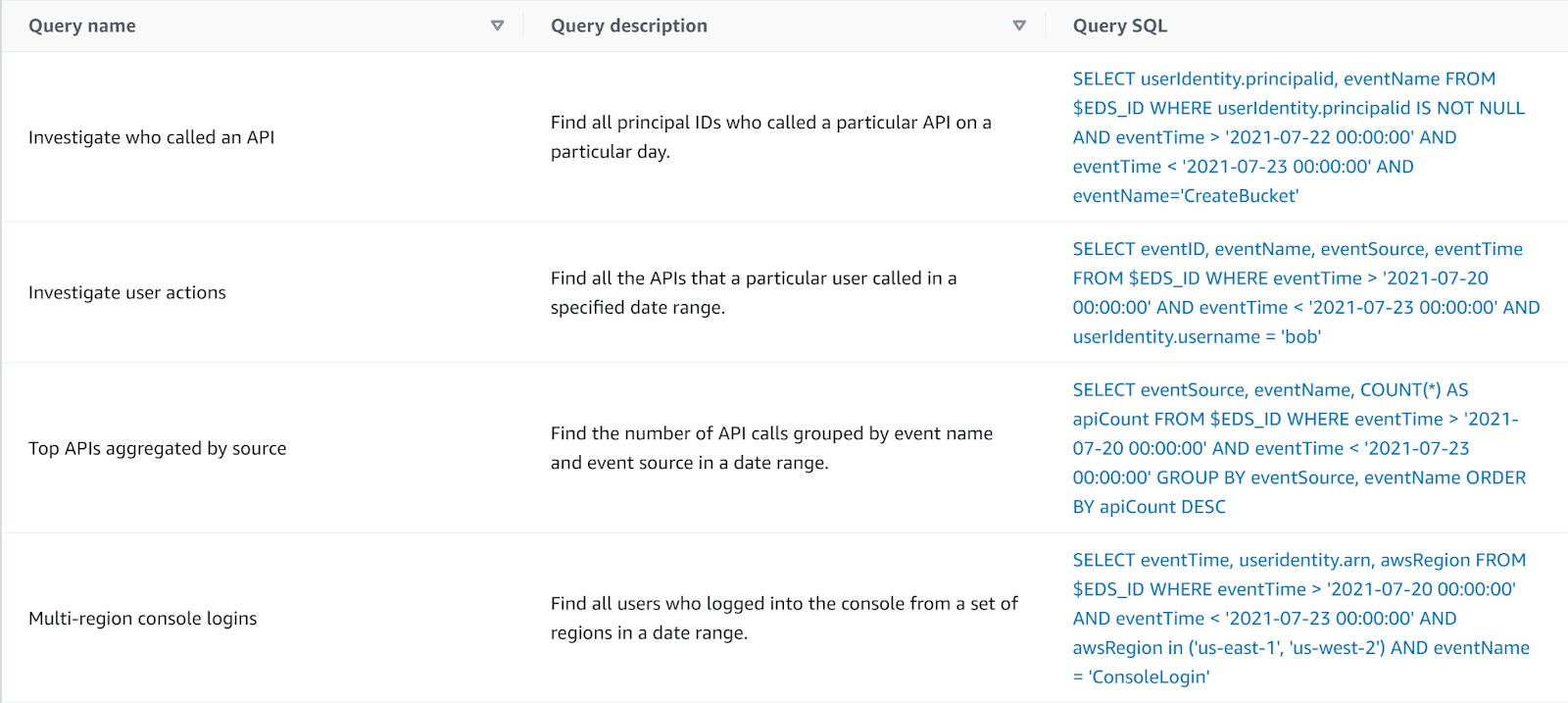
CloudTrail Lake also has certain SQL constraints, being read-only is of course a feature, not a bug, but being unable to build certain advanced SQL queries is a limitation one should be mindful of. On the flip side, it sets you up with the proper schema for CloudTrail events right off the bat.
How hard is the alternative?
Setting up the alternative AWS pipeline (CloudTrail->S3->Athena->S3) is not the most complicated thing in the world, and people who have a grip on AWS can get it set up pretty quickly, but it is not nearly as easy as deploying a managed service, and we haven’t yet discussed Lifecycle rules, S3 Storage classes, protecting the trail and the logs from deletion and modification, and managing encryption.
Cost
After a 30-day/5GB trial, this is the cost table for CloudTrail Lake
Pricing
| Details | Pricing |
| Ingest & Store | |
| First 5TB: $2.5 per GB | |
| Next 20TB: $1 per GB | |
| Over 25TB: $0.5 per GB | |
| Analyze* | $0.005 per GB of data scanned. |
So, not very cheap, but it’s hard to look at these numbers in a vacuum, let’s compare it to the alternative.
CloudTrail cost:
Your first management event trail is free. Additional copies of management events cost 2$ per 100,000, but there aren’t many reasons to have those. Data events cost 0.10$ per 100,000 events.
S3 Cost:
S3 storage for the first copy of CloudTrail management events is free. For data events, S3 standard tier costs 0.023$/GB/month, so theoretically, for 7 years (84 months), if you were inclined to keep your data for that long, that’s almost 2$, so definitely in the ballpark. The caveat is that not only do most organizations not keep 7 years of CloudTrail logs in S3 standard tier, it appears that neither does CloudTrail Lake, see this note:
*Queries running on data more than 1 year old will require data retrieval time of 1 min to 12 hours.
It appears that CloudTrail Lake is, in fact, Glacier-backed. Glacier is the S3 storage class for long-term backups, and this specific number: 1 min to 12 hours is the data retrieval time for S3 Glacier Flexible Retrieval. The cost for that is actually $0.0036 per GB, so only 0.25$ for the next six years, which adds up to 0.60$ for the whole span (one year of S3 standard plus six years of S3 Glacier Flexible Retrieval). However, this also perfectly demonstrates the type of complexity that CloudTrail lake saves most customers: setting up lifecycle rules and handling the transition of data between S3 storage classes.
Data query costs appear to be identical to Athena. And these, in turn, tend to be much cheaper than an ElasticSearch cluster or most similar solutions.
Do note, you should still keep CloudTrail logs (at least for management events) in an S3 bucket alongside a CloudTrail Lake, since the first management events Trail is free.
Estimating Your Monthly Costs
From CloudTrail Storage Bucket
- Access your CloudTrail Storage bucket in S3, if you don’t know where it is:
- Go to the CloudTrail console
- Click your organizational Trail
- Click the link under “Trail log location”
- Click the bucket name after “Amazon S3” in the top navigation, which has something like: Amazon S3 > [bucket name] > AWSLogs > [account id]
- Click the “Metrics” tab
- Multiply the total bucket size in Gigabytes by 2.5$: This is how much it would have cost you to ingest the contents of this bucket if you were using CloudTrail Lake.
If you would like to estimate monthly costs, divide the total size by the number of full months for which events are stored in the bucket (this can be inferred by exploring the bucket’s directory: what is the earliest year & month for which the directory AWSLogs/[account id]/CloudTrail/[region]/[year]/[month]/[day] exists.
From Billing
To estimate your monthly CloudTrail Lake costs (after the trial period):
- Go to the AWS Billing console.
- Click “Bill Details” next to “Month-to-Date Spend by Service”
 Click “CloudTrail” under “AWS Service Charges”
Click “CloudTrail” under “AWS Service Charges”- For each region, click the region name and add the number of events under “[region code]-FreeEventsRecorded. If you’re logging data events and intend to store them in CloudTrail Lake, also add the number of events under “[region code]-DataEventsRecorded.

- Divide the total number of events by 2,500,000 – that’s your very rough cost estimate.
After using the Trial, you can also examine “AWS CloudTrail [region code]-FreeTrialIngestion-Bytes” and just multiply that number by 2.5$ to get a much more accurate approximation.
To summarize: the convenience of a managed service does, unsurprisingly, come at a certain cost. Whether that’s worth it absolutely depends on the value it gives your organization, your alternatives and your needs.
Security
The Pros: Secure by Default
- Since storage is fully managed in CloudTrail Lake Event Stores, the customer doesn’t need to worry about encryption at rest, and doesn’t face the same risks as they do with an unencrypted S3 bucket.
- No need to worry about public buckets or external access – event stores are only accessible within the account.
- The data can’t be changed under any circumstances. Comparatively, CloudTrail does allow change detection, but that requires that the user actively check for violations, and still doesn’t prevent changes.
- By default, event stores are protected by termination protection, but that mostly protects against accidental deletions.
- There is a seven-day pending period before event stores actually get deleted (I would advise setting up an alert on cloudtrail:DeleteEventDataStore).
The Cons: Less Configurable Security
- No resource policy protection: Protection within the account is entirely dependent on the security of identity-side IAM policies.
- No Service Control Policy protection in management account: An organizational event store can only be set up in the management account – unfortunately, that means you can’t limit access using SCPs, as they do not apply in the management account.
- Logs cannot be separated into a different account – so users have to query organizational trails in the management account, and the logs can’t have the protection of being in a separate account where access is more tightly controlled.
1 1/(2.5($/gb)*(160e-09 gb/event))=2,500,000. 160 Bytes per event is a rough estimate of average compressed event size. I am estimating that the ingestion fee is based on compressed data as it appears to be in Athena, if ingestion fees turn out to be based on uncompressed data size, expect them to be about 10 times greater. (Note, if you have more than 5TB of events, consult the pricing chart).
CloudTrail Lake seems significantly more secure than a quick manual setup, and leaves much less room for mistakes and misconfigurations, but is not always as secure as the most refined setup, and is harder to defend with multiple layers of security.
Another thing to consider – does it fit your workflow?
It seems that CloudTrail Lake is conceptualized as a standalone solution mainly: it doesn’t naturally “play nice” with SIEMs, 3rd party SaaS solutions, and anything else that will want to read CloudTrail data from S3. You can keep a dual setup, but for data events that does come at a cost.
Integration with AWS’s own offerings for CloudTrail data analysis isn’t all there yet either, as integration with CloudWatch/CloudTrail Insights and with CloudWatch Events are not yet available.
The fact that events are exclusively stored in at most two accounts (the source account of the event and the management account), combined with the fact that event stores can’t be accessed cross-account also won’t fit everyone’s workflow.
Final Impressions
These are initial impressions from an initial launch. Both the community’s experience with CloudTrail Lake and, more importantly, the service itself and the features it offers will evolve over time, but at this point in time – these are my thoughts:
There is that magical zing about CloudTrail Lake – it’s pretty cool! It gets you from nothing to a secure, functional, queryable organizational lake in about 7 clicks and 5 minutes, and for those who don’t have a setup to query CloudTrail logs it beats using the Event History console by a mile.
Though for seasoned professionals it might seem easy to set up CloudTrail to send events to S3 to query with Athena to send results to S3, we know it’s not really that easy. If you also want to take care of encryption, check log integrity and create lifecycle rules to save cost, the complexity adds up fast. So for those who need ease of use, this managed service definitely does the trick, and does it well.
However, even ignoring cost considerations, for those that have a system that works for them, I think this feature might not be the best fit right now, and it might not be the solution that replaces existing complex deployments quite yet. The versatility and configurability of having all CloudTrail events stored in S3 is something a lot of organizations depend upon, and at this point in time CloudTrail Lake does not offer a way to work around that other than keeping a dual setup.
For more mature organizations, the multilayered security offered by account separation, service control policies and resource policies isn’t matched, at this point, by CloudTrail Lake’s secure but limited defaults.
Feel free to reach out to me with any thoughts, corrections, suggestions and opinions.
Noam Dahan
[email protected]
Twitter: @NoamDahan
The post Testing the Waters: First Impressions of CloudTrail Lake appeared first on Ermetic.
*** This is a Security Bloggers Network syndicated blog from Ermetic authored by Noam Dahan. Read the original post at: https://ermetic.com/blog/aws/testing-the-waters-first-impressions-of-cloudtrail-lake/
