

What is a false positive and why is having a few around a good sign?
Why false positives in security tools could be a positive, and why you should not go after the lowest false positive rates possible.
“We want a security tool with low false positives. Our developers are too busy.”
“Our proof-of-concept process is to test a single repo with two tools, and we pick the one with low false positives as decided by our engineers”
“Our current SAST tool was not well-received by developers. How are you different?”
These are snippets from conversations we’ve had with prospective users. Developers and AppSec engineers are quite right to be worried about the quality and quantity of the results produced by automated security tools; after all, no one wants a developer spending their time like this:
False-positive and false-positive rate (FPR) are two terms that seem to get a lot of attention in the application security industry, even more so than their counterpart terms, false-negative and false-negative rate. The perception seems to be that a tool or a device with a high false-positive rate or a high false-negative rate is bad and useless.
Why? Well…
- A high false-positive rate means that legitimate findings can be hidden by irrelevant ones. Updates to software might get delayed.
- A high false-negative rate means that legitimate findings are under-reported, and therefore, risky software or updates may get released to end-users.
Let’s also take a look at how false positives and false negatives matter in other fields:
Self-diagnosis lateral flow tests for Covid-19: A high false-positive rate would incorrectly send more people to labs to get expensive PCR and laboratory-based tests. A high false-negative rate would increase the rate of infection and mutation of the disease, increasing the risk of Covid-19 to the people.
LED screens and CPU chip fabrication quality tests: A high false-positive rate would imply that more screens and CPUs were incorrectly rejected, resulting in loss of revenue due to good units being thrown out. A high false-negative rate means more defective parts were shipped out to the customers, resulting in an increased return rate and possibly the loss of major contracts.
Now, let’s return to application security and software engineering. What is wrong with asking for a code analysis platform to not return any false positives? Why can’t vendors like ShiftLeft tell their engineers or code scientists to create rules with zero false positives in the first place?
SAST detects all possible vulnerabilities as early as possible. It’s more important that it detects everything, giving AppSec the opportunity to filter things out with policies than to reduce false positives and risk missing critical issues. Because SAST is so comprehensive, we can rely on it to detect serious threats missed by other tools — that’s a very good thing. But, with its coverage comes extra information that teams might not find as helpful.
To understand this better, let’s look at two misconceptions about false positives, two kinds of false positives that really depend on your specific setup, and finally two kinds of “false positives” that come down to your philosophy of application security.
Misconception #1: If results don’t make sense immediately, they are likely false positives.
No one comes to a tool with a blank slate, so it’s important to consider your perspective as well as the goals of the software. This is especially important for engineers who have only used linters and are now seeing data-flow presentations from SAST.
The messages returned by a linting tool are usually just single-line snippets with a brief description. In contrast, data flows provide a full view of a vulnerability from where data enters the application, called sources, to where the application uses the data, called sinks. The benefit is a much clearer understanding of the issue, but this requires an in-depth understanding of the code and dependencies.
Understanding what a data-flow presentation is saying about a vulnerability makes it much easier to verify its exploitability and can open more options for remediation. It will help catch many more issues than a linter and will make engineers more informed about dealing with them, but its context needs to be understood upfront.
Misconception #2: If it was a true positive, it would have been captured by the security framework
This topic requires a separate blog on its own, but in short, developers and AppSec engineers often overestimate the security elements offered by open-source frameworks and tools like static type checkers and linters.
For example, consider TypeScript: TypeScript comes with built-in features that can catch several type-related errors, such as the assignment of a string to a number variable (the left side of the screenshot below shows this error thrown during compilation):
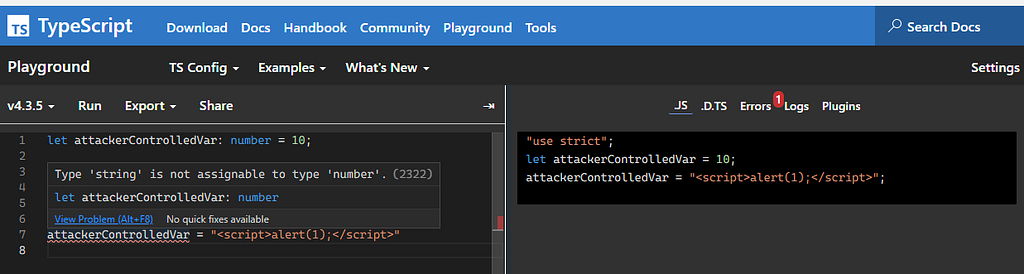
However, when a TypeScript application, such as a React.js single page application or a Node.js Koa serverless microservice, gets deployed to the production, tools such as webpack, esbuild, and ngc transpile the apps into a JavaScript representation (shown on the right side of the screenshot above). Notice how no type-related checks are present, making this code snippet vulnerable to XSS and other vulnerabilities.
I have participated in similar triage discussions for Python apps, where the same problems exist. Similarly, people tend to overestimate the protection offered by OWASP ESAPI, Spring Security, and other sanitizers without understanding their limitations.
Conditional false positives #1: Mitigation by external layers of defense
“We don’t have XSS in our applications because we use this Cloudflare WAF!” exclaimed an engineer during a proof-of-concept review. Hilarity ensued, however, when I shared exploits for successful WAF bypasses (some were even in the form of tweets).
Jokes aside, the engineer is correct in thinking that a WAF could offer some protection, freeing up dev time to focus on features and value-creating output. But, it is the responsibility of the AppSec engineer and security champions to evaluate and decide on additional mitigation based on the application’s risk profile.
Yes, writing secure code that properly validates and sanitizes user input leads to software that is secure with or without a WAF. However, the presence of an external layer wouldn’t make a finding a false positive in and of itself. For example, we have doors in our house that go outside, but we still use a safe for our valuables. Furthermore, the tool is not aware of the layers of security. It cannot tell if you have a WAF or whether it is configured and working properly, so it needs to report the vulnerability that it detects.
Conditional false positive #2: Incorrect scan configuration
Should an application security tool report findings belong to unit tests and end-to-end tests?
The solution turns out to be, “it depends.”
From my experience, I find that developers using an enterprise language like Java or C# are more open to seeing findings in their test projects. Conversely, JavaScript/TypeScript developers typically do not want their Cypress and Jest tests to be statically analyzed and results reported.
So, when we designed our JavaScript product, we automatically excluded the following directories from the analysis:
- test
- e2e
- *.test.[js|ts]
- *.mock.[js|ts]
This default setting generally works well for real-world projects, but developers need to understand it and adapt it to their specific environment. If the unit tests are named differently, you need to find the — exclude argument to let the tool know what you do not want to scan.
Another issue arises when an engineer copies and pastes a third-party library from node_modules into their project, which is then analyzed by the tool. SAST is very good at finding issues in the code you point it at, so a best practice is to make sure you are limiting its scope for the desired results.
Intentional Alert #1: Tool’s default coverage
Application security tools are built by teams of security engineers and code scientists, and at times the rules and logic reflect the team’s understanding and their preferences. Take the universally accepted OWASP Benchmark project, where ShiftLeft scores the industry-leading 74.4% (With 100% True Positive and 25% False Positive). We recently reported a bug in OWASP Benchmark with ShiftLeft reporting several hundred False Negatives which the benchmark script was not expecting.
unintended cookie attribute injections · Issue #139 · OWASP/Benchmark
The gist of the argument is whether the attacker-controlled getRequestURI method in servlet should be reported or not. We found that while Tomcat offered some basic mitigations by triggering an exception, the vulnerability was exploitable under JBoss Wildfly. Is this then an application vulnerability or not? Should ShiftLeft accept OWASP’s default position or do what we think is right? We decided to do the right thing and report these False Negatives. The bug 139 still remains open as of today and the reader could read and make up their mind.
Intentional Alert #2: vulnerability is reachable but not exploitable
OWASP benchmark is a great example for a project where many insecure code snippets do not become exploitable by mere luck. While the benchmark project is used to score and rate the tools, it is also a model project to demonstrate the vision and purpose of a code analysis platform like ShiftLeft.
Consider the below example (https://github.com/OWASP/Benchmark/blob/b38d197949f775b3c165029bda9dc6bd890265fb/src/main/java/org/owasp/benchmark/testcode/BenchmarkTest01826.java#L162-L165):
In this example, the vulnerable attacker-controlled payload is stored under the key “keyB-38565”. This is then retrieved into the variable “bar”, thus creating an attacker reachable vulnerability.
bar = (String)map38565.get(“keyB-38565”);
However, there is a code duplication and by mere luck, there is a reassignment, and the code is safe.
bar = (String)map38565.get(“keyA-38565”);
As per the OWASP benchmark, this is a false positive that would reduce your score. At ShiftLeft, we believe that the purpose of our platform is to educate and help developers become secure developers. If such near misses don’t get reported by the tool, then what is the point in adopting a code analysis platform that only reports serious problems without giving an opportunity to learn and improve? Out of the 25% False Positives, most of them are near-misses like this. With the ShiftLeft policy language, it is indeed possible to customize our platform to reduce the false-positive rate. I’m leaving this to the reader as an exercise.
I, personally, believe that a code analysis platform like ShiftLeft should aim for the highest True Positive Rate and the lowest False Negative Rate by default. There should then be mechanisms such as developer feedback, configuration options, and policies to tune and reduce the False Positive Rate. This combination would balance the need for security without compromising developer productivity.
Closing Thoughts
False positives are really not that bad, as they provide the basis for learning and teaching your team to write secure code. The purpose of a code analysis platform is to optimize for high True Positive and Low False Negatives out-of-the-box. Reducing False positives via the configuration and policies commonly known as “secure pipeline engineering” is then an AppSec-Developer collaboration is as important as application development and deployment for organizations.
What is a false positive and why is having a few around a good sign? was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from ShiftLeft Blog - Medium authored by The ShiftLeft Team. Read the original post at: https://blog.shiftleft.io/what-is-a-false-positive-and-why-is-having-a-few-around-a-good-sign-4acd4dbccf67?source=rss----86a4f941c7da---4
