
Rethinking Cloud Infrastructure Authentication
Hopefully, you’ve moved beyond “p4$$w0r9s” and use secure keys and multifactor authentication (MFA) for all of your cloud infrastructure. However, how many people have access to each little node, piece of software, server or management console? How many keys are scattered around so that scripts can execute? How many trusted IPs are there? If one bad actor gets one of these, can they take down your network? How many places do you have to change passwords when someone leaves?
Who has access to change and reconfigure your cloud? Clearly, an administrator has access. Also, think about your CI/CD pipeline and various DevOps scripts that change things. How do all of these things authenticate and gain access to the system? Is it a password, a trusted IP or MFA? What happens if one of those is compromised?
The traditional approach to corporate security involves a set of rules (encrypted passwords, TLS, patches applied, firewalls) and scans to ensure they are followed. This approach worked when there was a server or 10 locked in a corporate data center. But what if you have a cloud (or three) with hundreds of virtual machines distributed around the world?
In a distributed architecture, you now have multiple vectors of attack to consider. Those include people involved in maintenance, software and machines that you trust and the ever-present configuration errors that creep up in any complex system. In the cloud, with more places to copy data, software and configuration—and with more credentials and software to manage—there are bigger attack surfaces and a different threat model. To run a secure cloud or set of clouds globally, you need a new approach to ensure software is deployed securely and consistently.
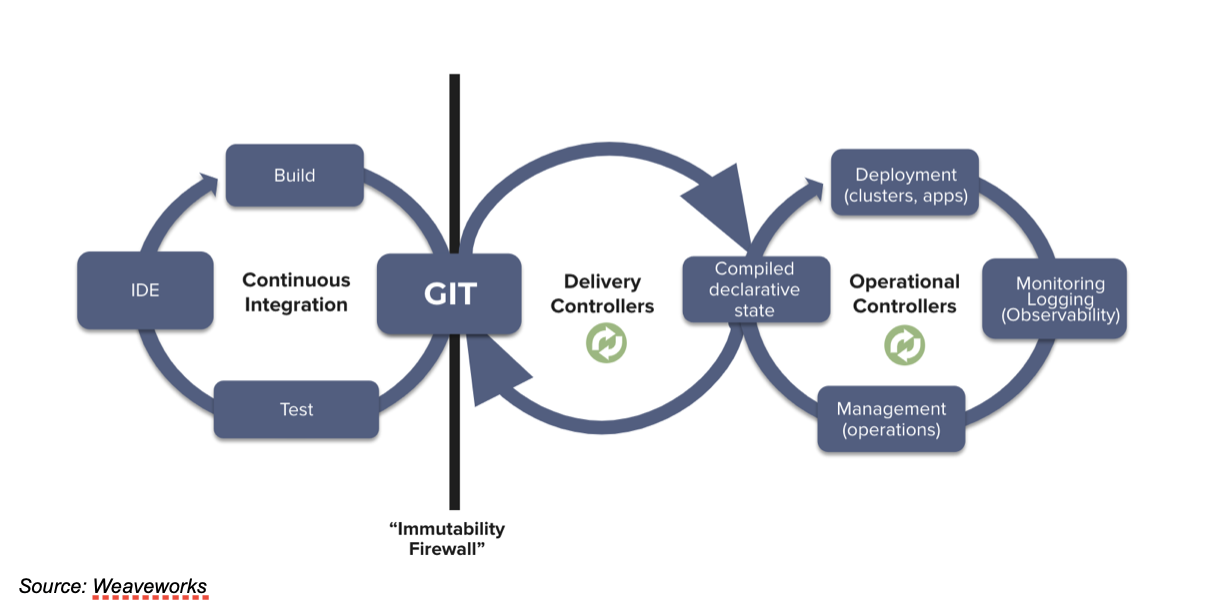
Last year, ShiftLeft’s Chetan Conikee wrote in Security Boulevard about a different approach called GitOps that changes the way software is developed and deployed. GitOps essentially supersedes DevOps and moves from a “push” to a “pull” model composed in the git revision control system and executed by autonomous software agents running in the target environment. This approach addresses the issue of who and what to trust and the issue of consistency in deployments.
Vectors of Attack
With a traditional DevOps approach to software deployment and configuration, there are several vectors of attack:
- Credentials are stored throughout the network to connect to the target infrastructure.
- People necessarily have access to the repository where configuration and software is stored, but often also have access to portions of the target infrastructure to apply changes.
- Scripts for deploying bespoke configuration are often subjected to a lower level of security review and frequently become inconsistent as infrastructure is upgraded. Credentials and access are distributed to these miniature agents of change.
- Target infrastructure often has trusted or relatively open access in order to apply change.
The key to each of these vectors of attack is human error. While human error can never be completely eliminated, automation reduces the likelihood of it occurring during any particular deployment or change as well as reduces the time to correct such mistakes.
Consistency
In addition to bugs and vulnerabilities being exploited, misconfigurations are also a leading source of security breaches. They’re caused either by simple human error, or are the result of drift. In any complex system, some number of errors will occur due to network issues, performance-related timeouts and just plain old glitches. These errors occur during deployment or configuration.
Over time, the difference between any two nodes in the system becomes profound. When configuration is applied as a set of DevOps scripts that focus on “the margin,” or how to change the present state to the desired state, configuration drift becomes incremental.
One way to attack a system “quietly” is in steps or pieces. The first DevOps script changes one thing that seems innocuous. The second exploits that change. Does this seem like the right way to change the state of a system?
How GitOps Addresses Several Issues at Once
Security professionals are incredulous when someone claims we’re a software install away from security nirvana. Indeed, GitOps includes software and implementation, such as the open source Flux project or commercial open source offerings such as Weave GitOps, that extends Flux for collaboration, compatibility, policy, observability and integration.
GitOps is also a set of practices and a mindset change.
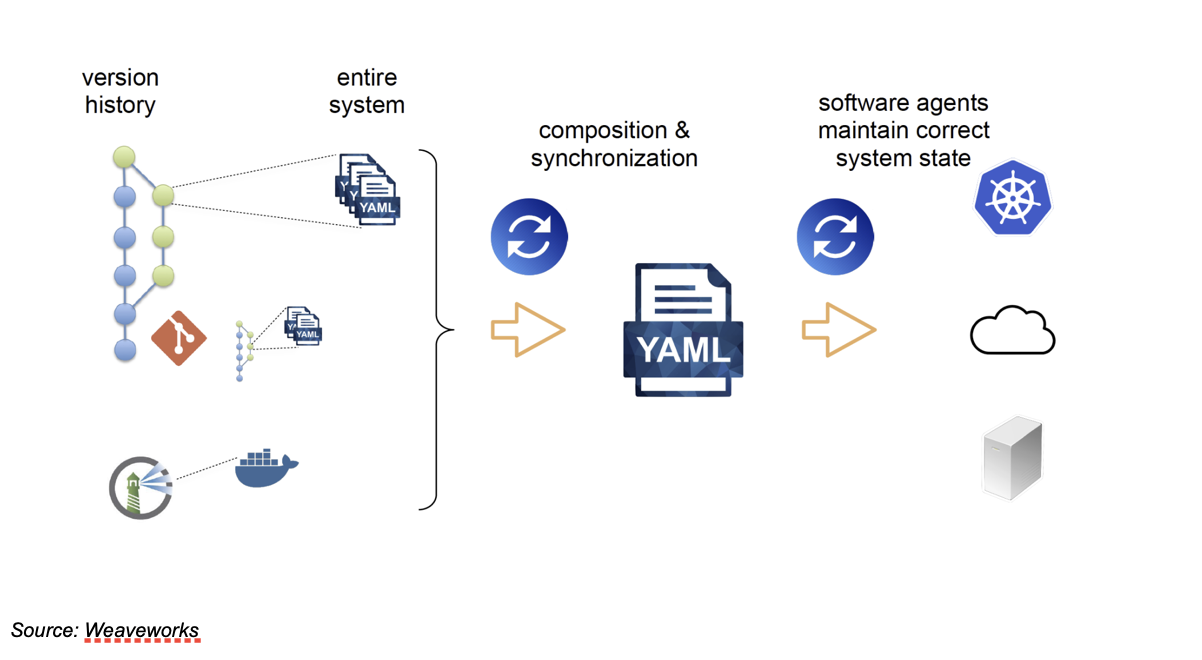
Key to this shift is that configuration is created declaratively by developers and DevOps professionals who submit a pull request. The request is reviewed and applied. A software agent compiles the configuration and determines which components on the network are out of sync with this state. There is no configuration drift, and credentials need not be shared with anyone but the software agents.
Thus—no one and nothing besides the agents need to authenticate to deploy or change the cloud configuration.
Maintaining this process requires not only a mindset change but continued discipline. It is often “so simple” to create a script and then just change something, but if GitOps is implemented properly, this opportunity does not even exist. To make the change requires going through the declarative configuration held in git.
GitOps requires more work to get started, but saves time over the life of the system, reduces errors and essentially hardens the overall system. However, people still make mistakes, and sometimes even internal personnel can be malicious. GitOps addresses this by building an auditable log of changes inherent to revision control directly into the system. “Whodunnit?” is merely a matter of executing the “git blame” command and the why is in each git commit message.
Putting it Together
Human frailty, configuration drift and over-propagation of trust can be mitigated through better practices and automation. GitOps is a set of technologies and best practices that address all three through automation, declarative configuration applied by software agents and inherent auditing.
Using GitOps tools and technologies, organizations can mitigate the vectors of attack by reducing the number of people and machines that have access to the target system.
However, implementing GitOps is not merely an install but a change in process. Configuration becomes declarative and automatically deployed instead of something an operator “does” to the system through a series of scripts for CI/CD pipelines. By implementing secure GitOps pipelines, security professionals benefit through fewer deployments, fewer errors and fewer people involved in the circle of trust.
In short, rethink the way people and machines authenticate by dramatically reducing the number of people, machines and scripts that authenticate or change the system.
