

How GitOps Raises the Stakes for Application Security
The rise of GitOps comes from the industry’s increased adoption of Kubernetes. As organizations and teams shift towards Kubernetes, scaling their cluster management practices becomes imperative as teams and workloads grow in size. This is where GitOps comes into the picture as it aims to bring together Git + Kubernetes with the objective of providing some form of the operating model to developers in their endeavors to deliver Kubernetes-based infrastructure and applications. GitOps is offered as a solution to continuous delivery when developing in Kubernetes and hence to increase the ‘velocity’ of those working with Kubernetes.
The approach of GitOps was basically invented by Weaveworks, who open-sourced a Git-Ops operator (read blog to its entirety to understand what an GitOps-Operator means) called Flux that runs within a Kubernetes or OpenShift cluster.
WeaveWorks is organizing a GitOps conference starting tomorrow, May 20th, 2020. I’d encourage everyone to attend this conference in order to understand it’s relevance and importance.
GitOps conceptually seems interesting. However, there are some misunderstandings and confusion around the terminology. That is why it is vital for us to cut through the hype to understand how GitOps actually works.
Why GitOps and how is it relevant?
Modern software development is generally performed with agile principles. One important part of Agile Development is Continuous Integration/Continuous Deployment (CI/CD), which automatically tests, builds and deploys every commit made by the developers to the central code repository.
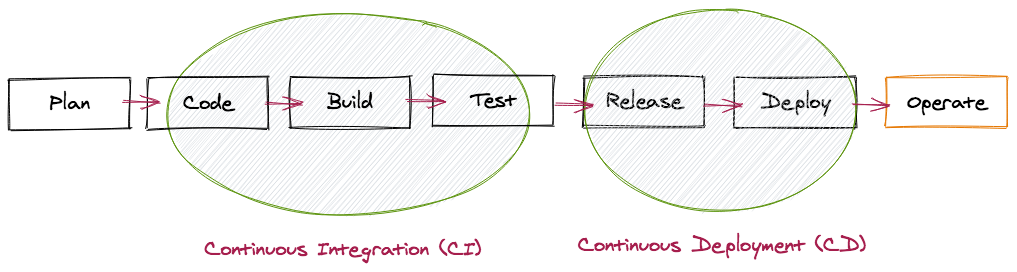
The deployment makes the latest version available in a test or production environment in a computing cluster. Those CI/CD tasks are performed by a pipeline agent as part of a centralized CI/CD system.
Traditionally, pipelines push new deployments directly to a cluster.
Thus, they need to have authorization to modify the cluster structure and access all its resources. The pipeline agents handling the credentials to this most important system are often insecure, due to the usage of unverified third-party plugins, rare updates and because regular developers have to manage the pipeline and the pipeline agent’s security without proper training. Thus, their main focus is to make the pipeline work, so they can start developing code.
Therefore, the production environment is vulnerable to attacks via the pipeline agent, which could enable an attacker to delete or extract stored data and/or modify the cluster.
To combat this security issue, and for other non-security reasons, GitOps was introduced to “pull” rather than “push pipelines.
In GitOps, the whole deployment state is defined in a git repository. Then, the pipeline writes or proposes a modification of the deployment repository and does not communicate with the cluster directly. For the synchronization of the deployment repository, an operator is placed inside the kubernetes (or OpenShift) cluster which can update all resources according to the definitions in the repository.
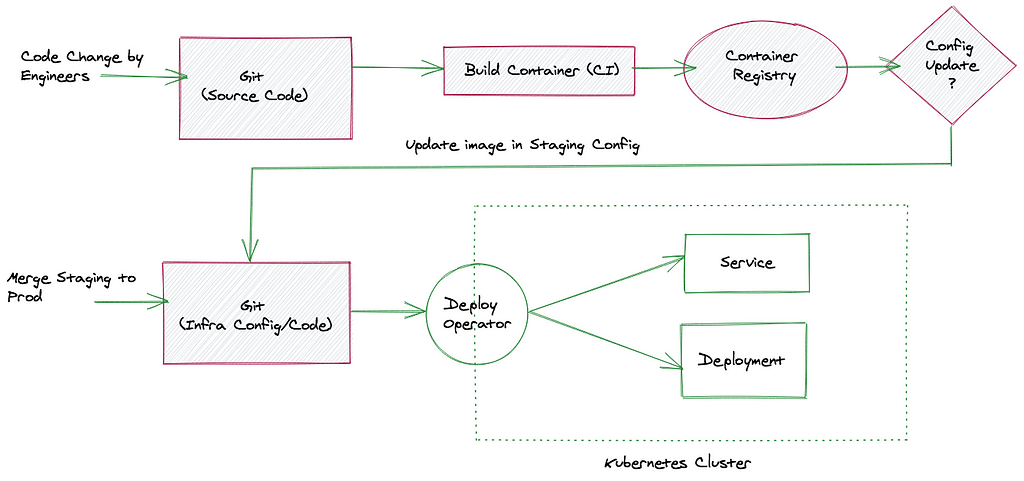
The final goal is to have a pipeline, which is authorized to only deploy the newly built artifacts, but not modify or access the structure or any other resources of the deployment defined in the repository thereby adhering to the security principle of defense in depth and limit an attacker’s impact.
Fundamental Shift from Push to Pull Model
The currently incumbent “push” pipeline model deploys the final build artifact — usually a Docker image — in a cluster as its final pipeline step. Obviously, the CI/CD tool where the pipeline runs needs to have write access to the cluster in order to deploy anything. The deployment will start immediately after the build process is finished and instructions about cluster configuration changes (mostly updated Docker image tags) are submitted to the cluster.
Plugins for the CI/CD system are required for the communication with the cluster, but no independent tools are necessary. The pipeline steps, which are defined in the source code repository are specific to a cluster environment — the cluster location can be set through external environment variables as well.
In the GitOps based pull model, deployment artifacts are pulled into the cluster. Therefore, the last pipeline step of the push approach is omitted after the image has been pushed into a Docker registry.
Thus, there is no direct contact between the CI/CD pipeline and the cluster
With this approach, the cluster state is declared in a separate git repository for all microservices of an application, which is why it is also called GitOps.
In the pipeline, the final step is to clone this deployment repository and commit a new image tag to be used for the microservice. Alternatively, a pull request can be created by the pipeline if every deployment should be signed by a human operator. On the other end, in the cluster, a GitOps operator runs and regularly compares the cluster state with the deployment repository. After the CI/CD pipeline has finished, the GitOps operator detects the new image tag in the deployment repository and deploys a new version. Often, this operator provides a dashboard and monitoring endpoints to detect and log deviations caused by cluster degradation or deployment repository updates and connects to existing notification solutions to reach responsible people quickly in case of errors or unexpected results. The whole system is described declaratively in the deployment repository, so every change made to the cluster will be recorded with a timestamp and reason, which allows easy auditing and rollbacks. Different GitOps operators can theoretically work with the same deployment repository and deploy into different clusters without a change to the pipeline. In fact, a new deployment in a new cluster can be created from the deployment repository alone if the old cluster gets damaged or needs to be replaced for another reason.
Vendors/OSS Projects in play with PULL based CD principle (with and without declarative principle)
– WatchTower
– Keel.sh
– OpenShift ImageStreams
– GitKube
– Weave Cloud and Weave Flux (Alexis invented the concept of #GitOps)
– ArgoCD
– JenkinsX
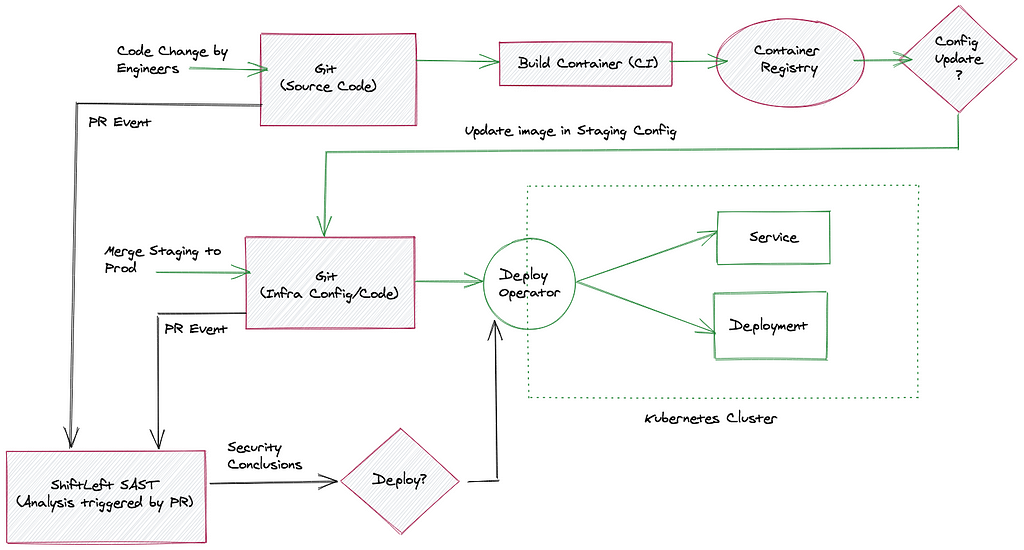
GitOps Operator decisioning — extending from infra security application security
I would recommend reading this article by Alexis Richardson, which gets to the into the crux of how a GitOps operator orchestrates it’s pull decisioning.
Alexis starts his post by asking these 5 seminal questions and continues to answer these questions throughout the post.
- Do you have direct access to the container image repository?
- Do you have direct access to the production cluster?
- How do you know what’s actually running in your cluster?
- Can you tell when expected vs actual state diverges?
- Would you have to re-run every CI/CD pipeline to recover a cluster after a disaster?
He also dedicates one section primarily to emphasize Security By Design and goes about listing ten principles defined by OWASP project

Alexis highlighted only a subset of these core principles (as indicated above) and then goes about explaining its context of CI/CD operator decisioning.
I would like to focus on the rest of 6 critical principles (not highlighted and primarily aligned with Application Security) that also need to influence this GitOps-Operator based decisioning process.
- Establish secure defaults : Beside host and network configurations, an application deployed should ideally be measured against a standard architecture specifications defined by an organization’s security architect.
Such specification should verify:
– Is the application adhering to a recommended authentication/authorizaion model?
– Is the application using vulnerable OSS components?
– Is the application using it’s 3rd party SaaS SDKs (Twilio, PayPal, Stripe, ..) in a secure way? - Fail securely : When an application fails, what are the primary reasons of failure?
– Due to a lack of rate limiting, can a Denial of Service attack cause failure?
– If a failure occurs, are exceptions (errors) carry sensitive information of assets (MySQL uid/pwd incorrect, Apache server timeout, etc …)
– Can this information enable an attacker to progressively improve active reconnaissance? - Don’t trust services : When an application is analyzed, is it possible to understand what it does (it’s business logic, insider attack potential, workflow, etc) and thereafter draw out a trust worthiness score of it?
- Fix security issues correctly : If an application encompassed in a container image contains vulnerabilities that have not been addressed yet packaged and ready to deployed, then the entire fleet of services are at risk of being compromised.
I like to take this opportunity to thank Andrew Fife for the effort that he contributed to edit, augment and review this narrative.
How GitOps Raises the Stakes for Application Security was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from ShiftLeft Blog - Medium authored by Chetan Conikee. Read the original post at: https://blog.shiftleft.io/how-gitops-raises-the-stakes-for-application-security-65dbb9a7f75d?source=rss----86a4f941c7da---4
