

The Last Mile of Sensitive Data
Almost any given modern software project these days will contain a set of technologies that offer a developer-productivity story, for traditional cloud stacks and cloud native stacks. One such stack is your typical Kubernetes stack. Which may contain Kubernetes itself, but also Istio, Helm, Docker and various Docker tools, Kustomize, various development and testing tooling such as k3s or minikube and your set of cloud SaaS vendors to interact with such as AWS, GCE, or Mailgun, Mixpanel, and many others.
These all are bound to change. Their features, their documentation, their integration points, API surface area, and above all the best practices of how to use all of these in perfect concert securely. One crucial part of gluing everything together — since these all have to integrate together eventually — is authentication, authorization and secrets and access detail.
With these challenges comes a painful disorder for the developers needing to build a coherent, single development experience for themselves, which is almost guaranteed to end up with shortcuts, scripts and makeshift tools to enable access and integration: How do you pull a token from mailgun, inject it into your Kube cluster, but also have the sandbox token in your minikube cluster, and perform an integration test for all of those combined? How do you move from minikube to k3s and take all of those specially-crafted scripts that pull secrets from all kinds of places?

PS: “The last mile” is a term used in supply chain management and transportation planning to describe the last leg of a journey comprising the movement of people and goods from a transportation hub to a final destination. We can find examples of a last mile in telephony where the last mile is a physical last mile of copper wire, and in eCommerce, where the last mile is the fulfilment process, where your goods will be shipped and handled and arriving at your doorstep.
Developers, developers, developers.
When software projects are successful, production workloads are healthy, monitored, alerts are in place, fire-drills and processes are well-known and well-rehearsed, and when something fails, you probably know about it. In terms of data safety – sensitive data can travel freely within our production clusters back and forth safely.
When it comes to the last mile of handling sensitive data and secrets in software, and more specifically in software development processes and our individual development habits — it is often uncharted territory and a developer workstation can become chaotic.
This small chaos that’s created isn’t great, to say the least. It leads to forgotten keys, misplaced tokens, exposure and leak of secrets and sensitive files, and above all – cause individuals to mistakenly override organizational security controls. You can have great security on your production workloads, but a small chaos in the last mile of it: the habits of day to day software development.
To deal with this last-mile problem, as developers, we use solutions and practices such as 12-factor apps, .env and various next-gen developer-friendly software vaults, such as Hashicorp Vault and cloud native developer-friendly key value stores like Consul and Etcd (all of which open source!). Still, often it’s hard to visualize what “productive” looks like with all these, and to create a streamlined, razor-sharp and secure workflow to support developer productivity and also security.
That’s why we built Teller, and we’re open sourcing it today
Never leave your command line for secrets

Secret sprawl is a semi-standard term for the bad practice that happens when your organization stores sensitive information such as secrets, keys, and other types of sensitive data in many different places. In order to make life easy, and lacking any proper solution, developers may place such secrets in code itself — hardcoded, in configuration files, in IaC (infrastructure as code) repos, in their private workstation setup (shell environment, zsh, IDEs) and more.
When secret sprawl initially happens — as a function of organization growth — the problem grows exponentially. For a healthy and growing organization, codebases grow, people duplicate, share, or release code internally, which gets shared once again, and the network effect takes care of growing secret sprawl massively inside the organization.
Often secret sprawl happens without individuals realizing it, because it’s naturally hard to see the bigger picture, and existing solutions are not doing a good enough job (disclaimer: that’s why we’re building Spectral, which solves this problem precisely).
Make the best out of your best practices
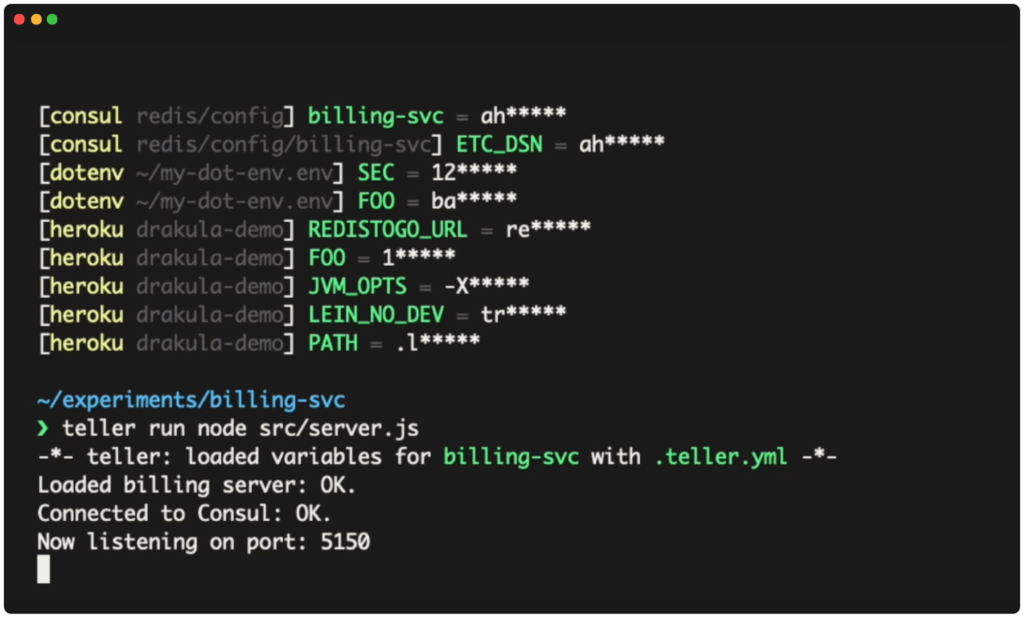
Teller removes these risks completely as it acts as the “last mile shipping hub” of secrets on your workstation. And worry not — a given teller.yml file contains no secrets — but instead contains the metadata that is required to fetch these secrets. The secrets are always stored in their best and most secure place to be – the organizational vault or other secure key stores (we support almost all keystores that exist!), Teller makes sure that they are never written to any file or persisted to any storage device.
Teller encourages developer environment hygiene, where it will never give a child process being run secrets that the owning shell process may contain — every process is run with a context which is on a need-to-know basis. This has a nice side effect that nullifies the vulnerability where hackers build processes that steal environment variables, often containing tokens and secrets that the developer is using constantly in their development environment.
Reduce microservice and cloud-native fatigue

In a micro-services or could-native landscape in the organization, it is very easy to find yourself needing to bring up a couple Go services, as well as a Kafka and a Node service from a few different teams, just to get going. And it’s reasonable to assume that you’re not aware of how these should be set up in terms of their data, context, and secrets. Not only that, it’s quite obvious that, out of security reasons, the originating teams wouldn’t want to share their secrets.
Vaults and key stores can be used to provide different teams safe and sandboxed secrets. However, the details of how to get and set these up are baked into READMEs, custom scripts and word-to-mouth, which is far from ideal. Teller can take all of that domain knowledge and pack it into one simple teller.yml file that each team creates. From there on, you just teller run the required services.
This can help developers and teams demo their product, tame the complexity and context switch more effectively without the fatigue associated with remembering, instructing, and checklisting these actions.
Summary
Teller is an open source and free tool that helps developers create a clean and hygienic development environment and helps keep infosec policies and first-class use of existing vaults, key stores and other sensitive data storage facilities in the organization.
As a side effect, by merely using Teller, we can block a number of possible attacks on our processes and personal workstations.
You can mix and match any kind of vault, key store, or API you can think of to grab keys from and have them ready for your process (everything is safe and secure, in memory).
You can get started with Teller right now – take it for a spin or build from source.
Image credits – Road at sunset – Johnathan Conlon
The post The Last Mile of Sensitive Data appeared first on Spectral.
*** This is a Security Bloggers Network syndicated blog from Security Boulevard – Spectral authored by Dotan Nahum. Read the original post at: https://spectralops.io/blog/the-last-mile-of-sensitive-data/
