
Secrets Detection: An Emerging AppSec Category
Applications are no longer standalone monoliths, they now rely on thousands of independent building blocks: cloud infrastructure, databases, SaaS components such as Stripe, Slack and HubSpot, just to name a few. This is a significant shift in software development. Secrets are the glue that connects these different application building blocks by making a secure connection between them, allowing them to pass information and data.
Using a distributed architecture like this comes with many advantages, including the ability to independently update services, scale services rapidly and offload development work to dedicated services such as SaaS vendors. This does come with a tradeoff, however; now we need to manage all the hundreds – or even thousands – of secrets that connect these different building blocks.
Because these secrets are designed to be used programmatically, they often end up being hardcoded into source code. This can be done by including them in application source code, configuration files, environment files or any other number of other methods. The problem is that source code is very leaky. Code is copied and transferred everywhere, and git is designed in a way that allows, even promotes, the free distribution of code. Projects can be cloned onto multiple machines, forked into new projects, distributed to customers, made public – you get the picture. Each time it’s duplicated on git, the entire history of that project is also duplicated.
The worst place for secrets to end up is in public git repositories, but this happens with alarming regularity. The 2021 State of Secrets Sprawl report from GitGuardian showed that over 5 million secrets were detected in public repositories, a 20% increase from the previous year. These figures, of course, don’t include the huge number inside private repositories.
Why Existing Solutions Fail to Solve This Problem
As the way we build applications has changed, so, too, has the way we work together as developers and protect our code. Many tools exist to help keep our code secure, but these fail to effectively prevent secrets sprawl.
Leaked secrets is a unique security challenge that’s different from all other vulnerabilities. That’s because the threat exists for the entire lifespan of a project. If we look at other common vulnerabilities – such as XSS, code injection, vulnerable dependencies, for example – what all these vulnerabilities have in common is that they only present a risk in the current, or production version of an application. If you have an XSS vulnerability in your code, once this has been updated and a new version pushed, that vulnerability is no longer an issue. If you have a vulnerable dependency, once it’s patched and updated, again, there is no longer a risk. If, however, you leak a secret into git, even if you remove it, it remains a risk until it is revoked. This is because the tools we use to develop software keep records of all changes. Someone just needs to go and peer into your history to discover the vulnerability. One clear example of this is in code reviews.
Detecting Secrets in Reviews (or Not)
One great advantage of git is the ability to quickly and clearly see changes made, and compare previous and proposed code states. Therefore, it’s common to believe that if secrets are leaked in source code, they will be detected within a code review or in a pull request.
Conducting code reviews is a great way to detect logic flaws and keep code quality high by enforcing good coding practices. But they are not a reliable way to detect when secrets have leaked into source code. This is because reviews are generally only concerned with the net difference between the current state and the proposed state. Code reviews do not consider the complete history of a development branch. This is problematic, because branches are often cleaned before a review, temporary code used for testing is removed, log files, and other unnecessary documents, are removed so these don’t end up in the master branch. The problem is that they stay in the history; unless the reviewer goes through the branches’ entire history, which could be extensive, any secrets previously committed will remain.
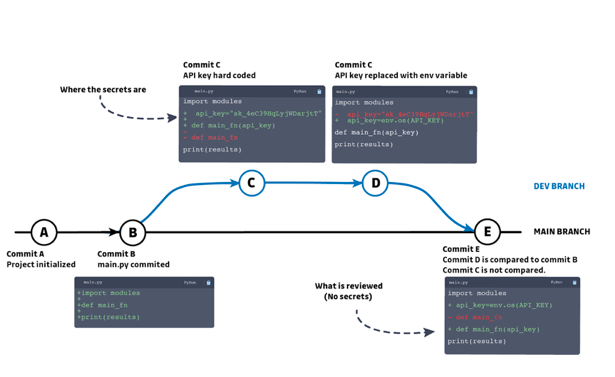
Above is a simplified version of a git tree that may paint a familiar story.
A new development branch is created and the developer, wanting to move quickly, hardcodes secrets into the source code (commit C). After finalizing the changes and getting the feature working as intended, he cleans his code, removing the hardcoded secrets and replacing them with environment variables.
Secrets Management Solutions
Secrets management systems are a great first step in trying to combat the issue of secrets sprawl. This is because, regardless of how strong your tools and policies are, if there is a human involved (and there always is), there exists the risk of secrets sprawl.
If a person wants to get from point A to point B, most of the time, they choose the path of least resistance. If we can pick a path and avoid unnecessary obstacles, then we certainly will
The same logic can be applied when we are talking about handling secrets. Encrypting secrets and keeping them tightly wrapped with access controls makes it much more difficult for developers to access and distribute them. This makes it tempting to choose the path of least resistance, which may include hardcoding them, storing them in easy-to-access locations, sharing them through unsecured channels like messaging systems, saving them into configuration files or even storing them in internal wikis.
Introducing Secrets Detection
Some smaller, niche application security companies have provided secrets detection solutions for years. The rapid acceleration of secrets sprawl, and its significance in many prominent data breaches, has led major players to introduce secrets detection into their security offerings as an independent category.
Secrets detection, however, is inherently difficult to introduce. This is because secrets detection is probabilistic—that is to say that it is not always possible to determine what is a true secret (or true positive).
Successful solutions must weigh the probability of a secret candidate being a true positive based on multiple different indicators and weak signals. Some secrets have fixed patterns that can easily be identified, but most do not; they can also be different character sets, lengths and appear in many different contexts. All these factors make detecting secrets accurately – without also alerting on false positives – extremely difficult.
Another big consideration is selecting a solution that can detect secrets within a wider perimeter, not just within company-controlled repositories, but also in employees’ personal repositories. In fact, only 15% of leaked secrets happen within organizations’ own repositories, while the remaining 85% occur in developers’ personal repositories. Many high-profile security incidents have occurred due to secrets being leaked and discovered within employees’ repositories including Uber, and, more recently, SolarWinds.
The way we build applications has drastically changed to include a distributed system of building blocks that are linked together using secrets. These secrets are often hardcoded into source code, as they are designed to be used programmatically. This can lead to a phenomenon we call secret sprawl. Secret sprawl is a unique threat to organizations because, unlike other vulnerabilities, once a secret has been leaked, it remains a threat for the secret’s entire lifespan. After all, it remains accessible in the project history. For this reason, and because the software will always have a human element prone to mistakes, current application security tools are not adequate to protect against this new threat. This has given birth to a new category of application security called automated secrets detection. While conceptually simple, detecting secrets in source code is inherently difficult due to the probabilistic nature of secrets; additionally, secrets can sprawl into assets that organizations have no control over, such as employees’ git repositories. For these reasons, organizations need to be deliberate in making sure the solution they select not only has adequate detection capabilities, but also covers assets both internal and external to the organization.
