

Lessons learned building supervised machine learning into DDoS Protection
Imperva’s Data Scientists trained a machine-learning model to auto-configure DDoS security policies and this blog shares some of the lessons learned along the way.
Data scientists consider labeled data the gold standard and, despite having to filter out anomalies, there is an overall tendency to trust it. In training a supervised machine learning model that auto-configures security policies and working closely with the experts the model was imitating, we learned many lessons about the many biases contained in man-made labels, and how to account for them.
The problem
Security policy 101
The problem statement was to auto-create security policies for network DDoS protection. Every protected IP range has a unique security policy based on its traffic, which is crucial for the successful mitigation of network DDoS attacks because it defines:
For years, our experts – the Security Operations Center (SOC) engineers – have been responsible for configuring security policies by familiarizing themselves with the system through trial and error.
As talented and hard-working as these engineers might be, the growing number of customers and ranges in play means we are slowly, but surely, reaching a point where manual intervention just doesn’t scale.
And it’s not only new security policies that require attention. Network traffic is a living thing that tends to change with time. It grows as more users register to a web service, and it can shift when a site goes global or offers new services. Since the COVID-19 outbreak, we’ve seen traffic patterns change significantly as companies adopted work-from-home policies and started relying heavily on video conferencing apps. This created a demand for more manpower to provide the optimal protection.
Finally, with so many policies being created and maintained manually, the risk of human error is always there.
Creating a security policy
Our experts commonly create and update security policies by visually inspecting an IP range’s time series traffic and figuring out the traffic’s pattern. Once they figure out the pattern, they set multiple thresholds, each one indicating the risk level and the corresponding mitigation protocol to be used.
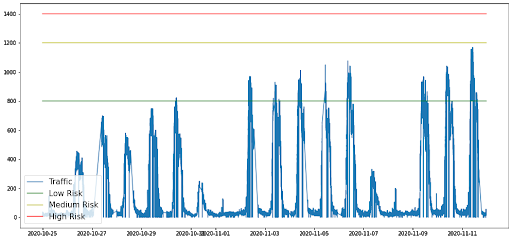
This process is performed for multiple protocols and ports; each one gets its own set of thresholds. As you can see, this process is very time-consuming and requires a lot of focus to ensure all thresholds are accurate.
Machine Learning For The Win
As you might have guessed, we solved this problem by creating an ML model that uses time series traffic to predict an IP range’s security policy.
Despite the many obstacles we came up against, the process was actually quite simple:
- Collect time series traffic from IP ranges per communication protocol
- Extract features from the time series traffic
- Use each IP range’s corresponding security policy, predefined by our experts, as a label
- Train and deploy the model
Surprisingly, training a great high-performance model was actually the easy part. In fact, it was the only easy part. There were obstacles to overcome every step the way, and we learned many valuable lessons in the process.
Data collection
Our initial thought was to create a labeled data set by simply collecting time series traffic from IP ranges and coupling them with their corresponding security policies to serve as labels. Sounds simple, right? As you might guess, it wasn’t.
Lesson 1: Get your experts closer to the data
Data freshness:
As time goes by, data starts to rot and lose context. When our experts update a security policy, they can look back at up to three months of traffic to understand the traffic’s pattern. However, it’s impossible to know simply by examining a security policy, which time frame was used by our experts to configure it.
We solved this problem by creating an automatic data collection process. Every time an expert updated a security policy, it would trigger a process to capture the timeframe used by the expert, couple it with the updated security policy and save it to our database. This helped us create a DB of reliable training examples that would stay relevant forever.
Special / edge cases
Filtering your training data by removing anomalies can make a big difference in the model’s performance, although spotting these anomalies isn’t always easy. In our case, some security policies were tailored to the customer’s requirements. For example, some customers have backup ranges – ranges that are “off” and have no traffic, but are set in place just in case something happens to the main IP range. Backup ranges have a security policy that reflects the main IP range’s traffic, i.e. their potential traffic, rather than the actual traffic flowing through them.
We solved this by allowing our experts to provide feedback while adjusting security policies via a quick questionnaire. We used this feedback to map all the different cases the model might encounter, and set a solution in place.
Simplify the data
Encourage your experts to work on the raw data. The traffic dashboards which our experts rely on to create security policies are aggregated and smoothed, as is customary, to give a better picture of the traffic’s trends. However, this means there’s a mismatch between the data our experts work on and the raw data used by our machines to perform DDoS mitigation. Our experts know how to bridge this gap using their previous knowledge of the range, combined with an array of additional sensors such as logs and alerts, but passing this knowledge on to a model isn’t easy or scalable. Instead of presenting our experts with smoothed time series dashboards, and relying on their ability to bridge the gap, we have created an alternative dashboard that presents the raw data. This simplified our data and allowed us to create a simple, straightforward and explainable model,, because once our experts were presented with raw data they didn’t need any previous knowledge or additional sensors in order to set the best security policy.
Training and validating
Now that we have our dataset, what’s next?
We preprocessed our training data set by performing feature extraction on the time series traffic, selecting the best features, and coupling them with their corresponding security policy. Once we started exploring this data, before feeding it to the model, we discovered additional problems with our labels which we had to solve.
Lesson 2: Human experts are still human
Heterogeneous labels:
When asked to spot if there’s a car in a picture, most humans will probably give the same answer. However, if you ask them to estimate the car’s age you might get a range of different answers to the same question.
We encountered this precise issue with our data, when, given the same dataset, our experts produced different security policies. We decided to solve this problem by leveraging a cognitive bias known as Anchoring which means that when initial information is presented to an individual, it serves as an anchor causing all future decisions and estimations to happen in relation to that initial information.
During the training and deployment process, using Anchoring meant that when an expert would start to adjust a security policy, our model would suggest a security policy, anchor the expert to it, and effectively reduce the number of heterogeneous labels. At first we suggested security policies based on simple heuristics, and as we collected data we trained and retrained the model to suggest better policies. This does not mean that the experts accepted the suggested policy, but rather that, when given the same data set, they were all now anchored to the same suggestion, meaning less variation between their answers.
Normally, we would want to avoid this bias, especially when guesswork is involved. However, in this case it wasn’t a real problem because the experts would always check if their security policy matched the traffic, so no amount of bias would cause them to create a bad security policy. On top of that, we simply replaced an existing anchoring bias – the previous security policy.
Pretty numbers bias:
Humans tend to prefer round “pretty” numbers, and as the number grows, the number of trailing zeros grows too. This is especially noticeable when choosing initial numbers. Although it only mildly affects a security policy, it does cause a problem when validating results because the model will never generate pretty numbers, and we wouldn’t want to hinder its accuracy by forcing it to. We solved this problem by suggesting a security policy to the experts, thus reducing their tendency to use round pretty numbers because the expert wouldn’t choose the initial values and would just adjust them as required.
Monitoring and rollout
Lesson 3: once deployed, everything changes
Start small
Once a model reaches high levels of performance, it’s tempting to mark it as done and ship it out, but this might not be the best move. No matter how many tests you run, a model that performs well in the lab might crash and burn when deployed in a production. Once it’s deployed you’ll suddenly have to deal with new use cases you hadn’t thought about, and solving problems in production isn’t something you want to do. We solved this problem by performing a gradual rollout. At first the model only suggested a security policy and our experts had to manually approve it. By tracking the suggestions that were accepted and rejected we gradually gained confidence in the model. Once we reached a good ratio between rejections and approvals, we moved it to a fully-automated mode.
Think about explaining and presenting your model
Classic metrics for regression models, such as mean squared error or explained variance accurately represent the model’s performance, but aren’t easily explainable and tend to be confusing, especially to non technical audience or anyone that’s unfamiliar with the data. It became a true challenge to represent the model’s accuracy and its risk of getting a prediction completely wrong in a single, human-readable metric.
We decided to use an alternative evaluation method. Instead of measuring the error between the prediction and target, we simply checked whether the prediction was close enough to the target, allowing us to use classification metrics to better present and understand our results. We defined what was considered to be close enough by creating a tolerance scale. Simply put, the tolerance scale allowed the prediction to be up to X% above target, or Y% below target. The values you choose for X and Y determine the tolerance for each type of mistake. In our case, setting a security policy too low can lead to false positives, and so we set a higher tolerance for predictions above target than for predictions below target. This ended up being a very useful regression metric that was both easily explainable and accurately reflective of the error’s magnitude. This alternative method was meant for humans only; we still used the classic metrics for the training phase.
Implement failsafes and learn from every mistake
Even highly accurate models can make mistakes, and no one likes having to deal with a crisis at 2am. With classification models it’s common practice to choose a single threshold that distinguishes between a yes and no answer. To avoid false positives, it’s easy to add an additional threshold that says “maybe” and send these results for further examination. In regressions models the confidence interval can be used to determine cases where the model isn’t confident about the predictions. However, both of these solutions rely on the data the model is already relying on. This might be a problem if the model encounters special cases that aren’t reflected in the current features it uses. For example, a model that predicts an item’s price based on its shape and components, will set a very low price for collector items because it ignores the item’s history. We solved this problem by using an additional data source – the item’s previous price, or in our case – the previous security policy. We started comparing every prediction the model made to the previous security policy. Policies that changed too much were marked “risky” and sent for manual approval, effectively preventing any impact on our customers, and allowing us to investigate new special cases and patch up the model accordingly.
Conclusions
As tempting as it might be, don’t rush to trust your data. It’s extremely important to not only explore the data thoroughly, but also think about who created it, how it was acquired, which biases could affect it, and how you can fix it.
While you’re working on your model, take some time to think about the model once it leaves your lab. Ask yourself the following questions:
I hope you’ll find these lessons useful for your supervised learning project, especially if the labels are man-made.
The post Lessons learned building supervised machine learning into DDoS Protection appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Johnathan Azaria. Read the original post at: https://www.imperva.com/blog/lessons-learned-building-supervised-machine-learning-into-ddos-protection/
