

Refactoring a Live SaaS Environment
We decided to refactor and re-implement almost all of our back-end and UI. This is how we went through the design and implementation. You can experience the new design by trying ShiftLeft code analysis product here

ShiftLeft NextGen Static Analysis (NG SAST) is a software-as-a-service static analysis solution that allows developers to scan every pull request for security issues. Earlier this year we released Secrets, Security Insights, and a v4 API. Secrets and Security Insights are two new types of results we extract from code analysis, and the V4 API is a brand new RESTful JSON API with an OpenAPI/Swagger specification that you can use to access all of your results. Read more about these features in our announcement post.
NG SAST was initially designed only for vulnerabilities. In order to implement Secrets and Security Insights, we either had to retrofit these new result types into our existing implementation or significantly refactor our back-end to support their unique characteristics. Even though it would take longer and be more difficult to implement, we decided to do the latter. We rewrote almost all of the storage used for storing code analysis results while maintaining backwards compatibility and without any outages. The analogy is that it’s like changing the engine on an airplane in flight without the passengers noticing.
We could’ve saved a lot of time by hacking things together and making it work, but instead chose to take a step back and use this opportunity to redesign, clean up some technical debt, and establish a solid foundation for future work. It wasn’t easy: in addition to re-implementing large parts of our back-end, the UI was also significantly refactored to move to a new API. It took several weeks of intense collaboration, designing, iterative implementation, and testing in production.
Design
With any big project, it’s impossible to jump into writing code. The Product team’s user stories paint a rough picture of what new features will ideally look like, but it’s the Engineering team’s job to take those requirements and translate them into implementation details. This requires a lot of back-and-forth, figuring out how all of the pieces fit together, what the edge cases are, and what’s possible or not possible to do within a given time frame.
Process
As software engineers our job is not to produce code per se, but rather to solve problems. Unstructured text, like in the form of a design doc, may be the better tool for solving problems early in a project lifecycle, as it may be more concise and easier to comprehend, and communicates the problems and solutions at a higher level than code.
https://www.industrialempathy.com/posts/design-docs-at-google/
Every big engineering project at ShiftLeft starts as a design doc. These are Google Drive documents that describe what we want to implement and the implementation plan. This allows us to collaborate and iterate on a design with a large audience so everyone has an idea of and (a say in) what’s about to be implemented.
Even though only a handful of people were responsible for the implementation, the whole team participated in the review and refinement through design docs. One of the major objectives was to avoid any major surprises during implementation. A lot of time was spent on the design doc and API spec for this project, and as a result we ended up making lots of changes in the design in the beginning and had no major surprises.
Data model
We introduced two fundamental types: scans and findings. With findings we now have a generic data type to represent any kind of result we can get from code analysis. Vulnerabilities, Secrets, and Security Insights are now just different types of findings. Introducing scans allowed us to have an explicit data type representing each code analysis scan. This seems obvious to have, but it was implicit in the previous design: a scan was bits and pieces of information scattered around in different tables in our databases. Now we have tables literally called scans and findings!
The right data model makes everything else easier.
With the new data model, a lot of things became much easier. The mapping to database tables is more obvious, so database queries became much clearer, and in some cases, faster. It was much easier to implement certain features like tags, customizable severities, and scan comparison. Finally, when the data model is simpler you end up with fewer bugs.
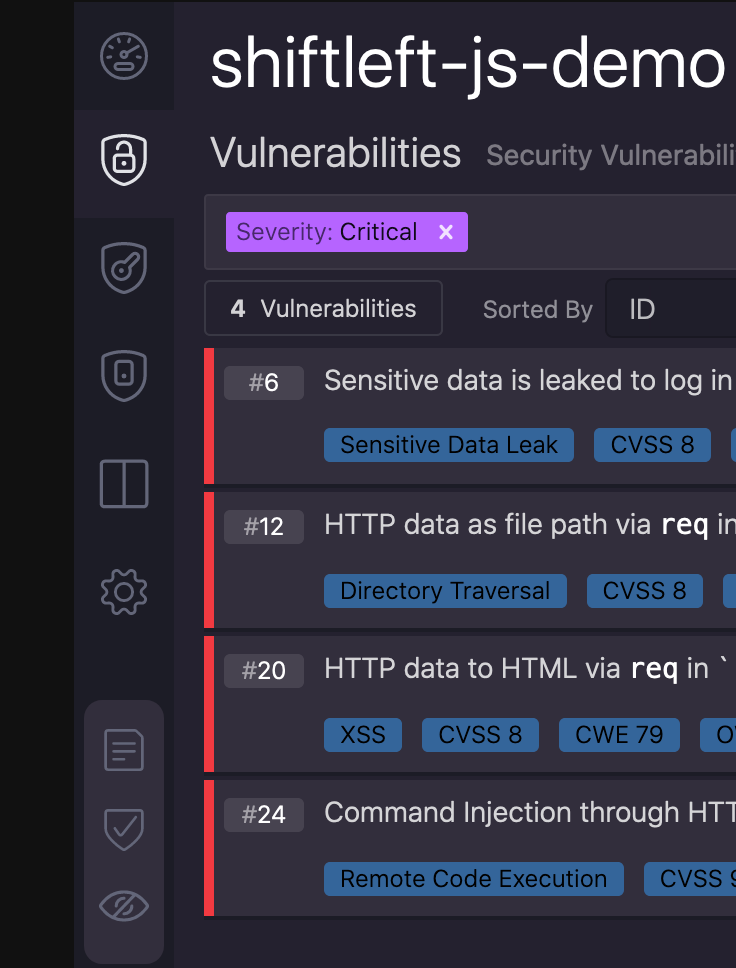
We were also able to implement user-friendly IDs for scans and findings. Instead of identifying them with long IDs or hashes, scans and findings now have GitHub-style incrementing numeric IDs. The first scan and finding of each project starts at ID 1, the second has ID 2, and so on. This was a feature that was requested by customers for a long time, and we finally had a easy way of implementing it with this refactor.
Some other features that depend on the new design:
- User-friendly API
- User-friendly IDs for scans and findings
- Expanded language support via ShiftLeft Scan
- Better build rules that use the v4 API
- Compare scans
- Customizable severities and tags
Unified API
The new v4 API that we implemented is a single API that is used by our UI and customers for their own scripts or integrations. Before there were two different APIs, v2 and v3, that are completely different. They had two different implementations and the one available to customers was very limited compared to what was used by the UI. With a single unified v4 API, we’re able to provide customers with all of the capabilities available through the UI for their own tools. From the back-end perspective, we only have a single API implementation to satisfy both use cases.
Old and New
Working with a live environment, we couldn’t just implement the new API and back-end and turn off the old one. First, there was a lot of data in the old format that we needed to migrate. In fact, it was also in a different database so we couldn’t just run a simple schema migration. Second, the UI needed to be rewritten for the new API too, and it was done in two phases so we needed to maintain support for the old API.
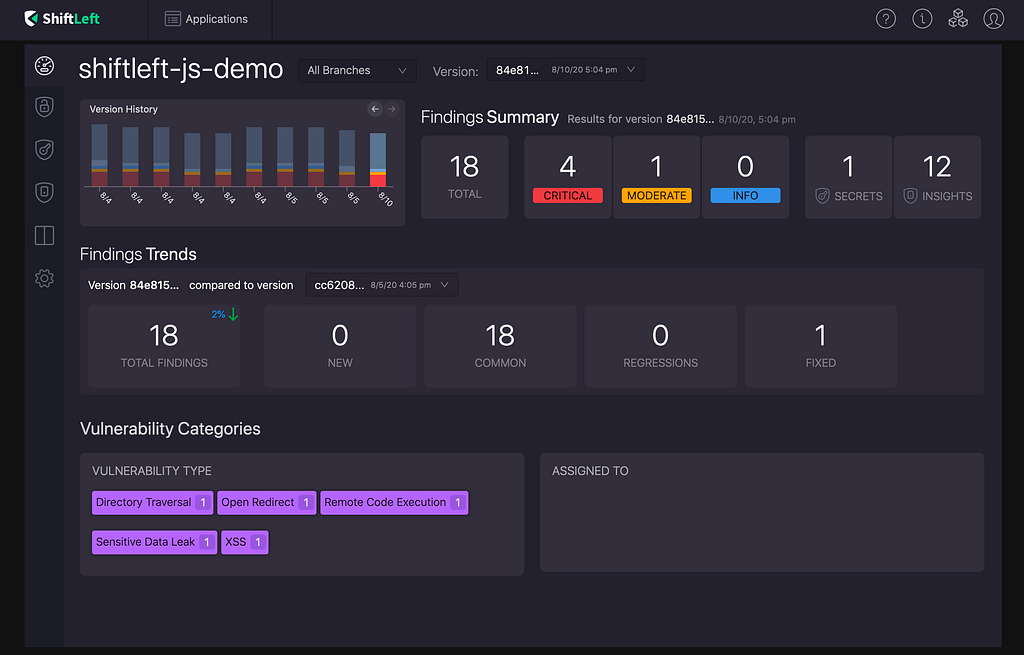
We started by writing data from new customer scans to the old and new systems in parallel. Secrets and Security Insights are new features, so there wasn’t any old data for them, so they could be served only from the new API. Vulnerabilities had to be served from the old API because historical data wasn’t available to the new API.
As the UI was implemented using the new API, we slowly made bug fixes and added anything we missed during the initial implementation. Eventually, the new API was done, the UI was using it for Secrets and Security Insights, and it was time to get the last part of the new API working: Vulnerabilities.
Data migration
We had thousands of scans of vulnerability data in the old API back-end to migrate to the new API. We created a vuln_migration_status table to keep track of all of the past scans we needed to migrate. The following shows the schema for that table. sp_id is our old internal ID for scans.
Column | Type | Nullable
-----------------+--------------------------+----------
sp_id | text | not null
organization_id | text | not null
project_id | text | not null
scan_id | bigint | not null
processed_time | timestamp with time zone |
Indexes:
"vuln_migration_status_pkey" PRIMARY KEY, btree (sp_id)
Next we created a small (<250 line) Go script to iterate through this table and migrate vulnerabilities one scan at a time. It runs the same functions as the live production service to create scans and findings records, except with a timestamp in the past instead of the current time.
After a few hours of carefully running the migration in batches, we managed to migrate several thousands of scans with 0 failures! Even if we had a failure, we could keep track of our progress with the vuln_migration_status table and possibly skip over or manually fix any problematic scans. In the worst case, because the new data was only in new tables, we could have wiped everything and started over without any consequences.
Feature flags
Working on a SaaS platform makes it easy for us to deploy new features hidden by feature flags. This allows to iterate fast and incrementally ship to production, and also verify against live customer data. After migrating all of the old data and re-implementing the UI to use the new API, we had to make sure the results from the new API are the same as the old.
Our UI uses feature flags toggled by URL parameters. To enable the new views that work with the new API and back-end, we simply had to add ?findings=enable to the URL. This allowed us to compare results side-by-side.
This was one of the biggest projects at ShiftLeft. We decided to make changes to things that have been a certain way since the beginning of the company. It wasn’t an easy project, but there were several things that made it easier: a culture of collaboration, processes like design docs, and tooling like migration scripts and feature flags. Not only did this project give us a foundation for other features, but it also provided a template for working on other big projects too.
Refactoring a Live SaaS Environment was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from ShiftLeft Blog - Medium authored by Preetam Jinka. Read the original post at: https://blog.shiftleft.io/refactoring-a-live-saas-environment-5d0911b8b281?source=rss----86a4f941c7da---4
