

When Bandwidth Doesn’t Last
Introduction
Imperva’s Cloud WAF networking team went through a major transition from an operation team to a development team during the SDN era. We saw new products emerging for our network infrastructure – moving from manual operation to automatic. But, while the change of mindset from being an operation team to a development team wasn’t easy, we’re starting to reap the benefits, and which SDNOC is just one.
Imperva’s DDoS protection cloud solution receives a very large volume of traffic – for example, one DDoS attack we recently mitigated reached 700Gbps:
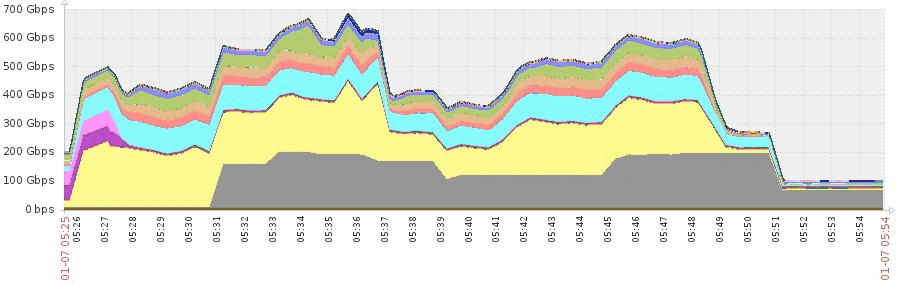
These attacks put a lot of pressure on our network infrastructure – particularly on our internet connections, not all of which are designed for DDoS protection. Some are designed to improve our CDN performance, for example, while others, such as Internet Exchange, are designed to lower costs.
Furthermore, some POPs are designed to handle larger volumes of traffic than others.
So, when an attack is congesting an internet connection, we need to divert that attack toward our DDoS internet connections.
Today
Our network is designed in such a way that DDoS attacks should reach the internet connection with the most bandwidth. Sometimes, though, the attacks reach smaller internet connections.Until today we handled those events manually, using SNMP to monitor our internet connection.
But the manual process is slow. SNMP monitoring systems poll the device metrics every 30 seconds, and NOC engineers receive an alert about congested internet connection five minutes after the congestion starts. When they receive that alert, they start investigating which IP range is causing the congestion, and need to stop the advertisement of the IP range from the internet connection.
Around 10 minutes of congested internet connection is a long time – it can have an impact on sessions that pass through it. Lowering the time it takes to handle congested internet connections will therefore minimize the impact of such events for our customers.
Humans make mistakes – they can bypass the wrong IP range, make the wrong internet connection, fail to notice congestion, or forget to remove the bypass when an attack is over, resulting in degraded performance for any customers using the attacked range.
SDNOC – Software Defined NOC
To overcome these challenges, we designed an automatic system to handle our internet connection congestion. The system will detect when an internet connection is congested, and which IP address is congesting, and will divert the IP prefix to another internet connection.
The system is built from four pieces:
- Data collector
- Controller
- Kafka
- Enforcer
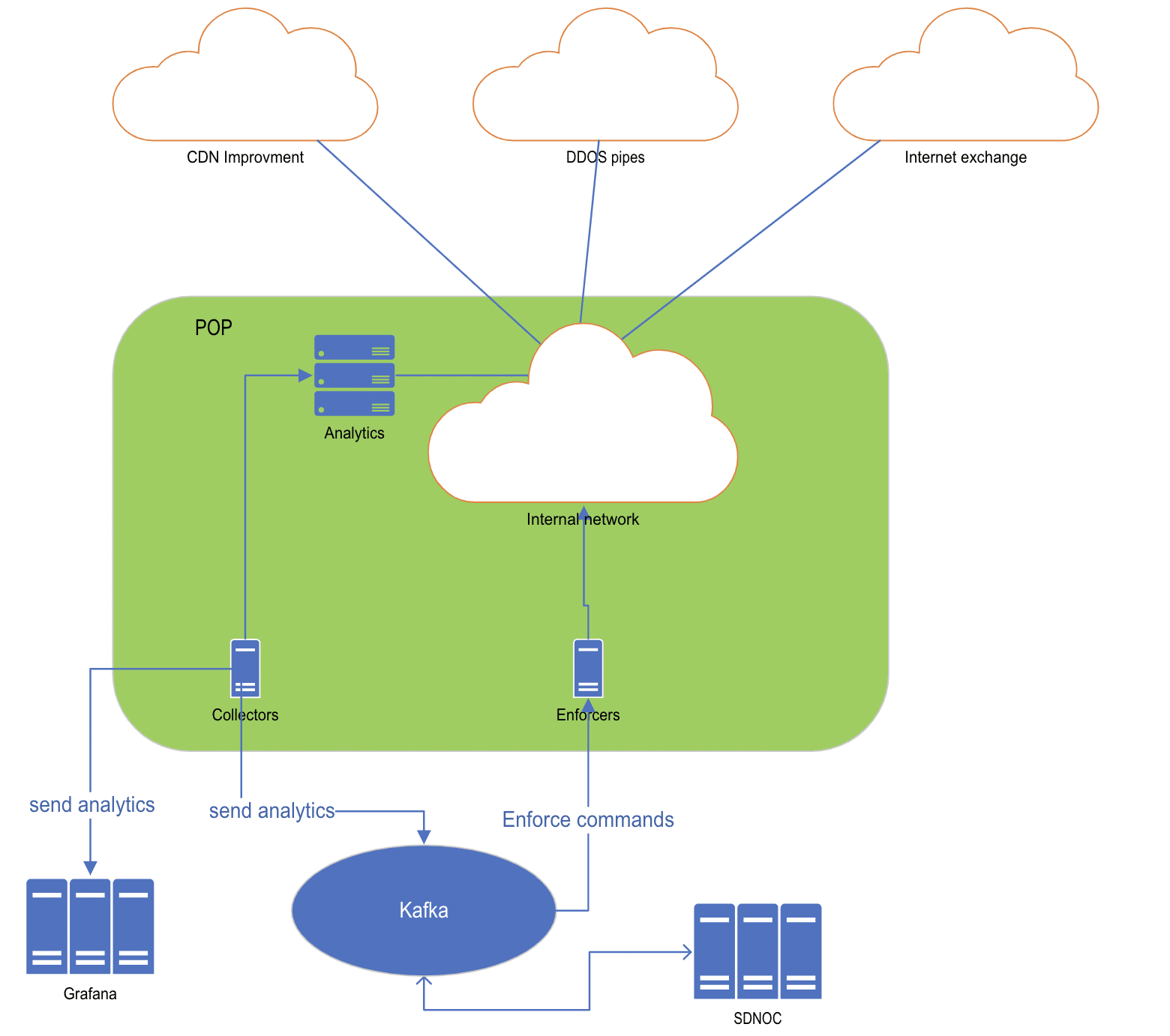
The SDNOC system checks the internet connection utilization. When an internet connection is over-utilized, it sends a message through Kafka (you can learn more about our Kafka usage here), to SDNOC servers which then send a message instructing SDNOC enforcers to mitigate the congestion.
Collector
The collector’s role is to gather data on internet connection bandwidth utilization and, when a connection is overwhelmed, notify the SDNOC server, providing it with information on which IP prefixes generate the most traffic.
When we first started to evaluate how to collect this data, we began by testing SNMP – the collector polled the network devices by SNMP to gather utilization metrics. We performed the following experiments in our labs:
Starting test.. time: 09:56:45
09:56:48 – 0.0 mbits/sec
09:56:52 – 193.85 mbits/sec
09:56:55 – 0.0 mbits/sec
09:56:58 – 122.93 mbits/sec
09:57:01 – 0.0 mbits/sec
09:57:05 – 194.14 mbits/sec
09:57:08 – 0.0 mbits/sec
09:57:11 – 147.98 mbits/sec
09:57:14 – 0.0 mbits/sec
09:57:17 – 185.25 mbits/sec
Source code
As you can see, we pulled the SNMP statistics every three seconds, although the device counter doesn’t get updated that fast – every second pull is missing.
We also evaluated NETCONF – the collector connected using REST-API (NETCONF) and used it to pull interface statistics
Here are the results of the Netconf test:
11:11:12 – 626.78 mbits/sec
11:11:14 – 627.7 mbits/sec
11:11:17 – 628.43 mbits/sec
11:11:19 – 627.58 mbits/sec
11:11:21 – 628.65 mbits/sec
11:11:24 – 626.7 mbits/sec
11:11:26 – 626.68 mbits/sec
11:11:28 – 626.68 mbits/sec
11:11:30 – 627.1 mbits/sec
11:11:33 – 627.1 mbits/sec
As you can see, sometimes the counter didn’t get updated, while sometime we got two internet connections over a single interface separated by VLAN. As a result, when there was a congestion event, we didn’t know which internet-connection was causing the impact.
We also considered using streaming-telemetry, but it isn’t mature enough yet.
Luckily, we’d already developed an analytics system for our customers’ dashboards that gathers data from our network switches using port mirroring, and decided to leverage the system in order to monitor the internet connection. The analytics collect the meta-data from the port-mirror, the collector connects to the analytics system and pulls the load on each internet connection and, when the collector notices that the internet-connection is overwhelmed, it notifies the SDNOC server via Kafka.
The controller
After we discover a congested pipe, the system needs to make decisions about which internet connections and which IP range are congested, and whether the congestion is caused by a DDoS attack or ordinary users’ traffic.
The first question to answer in order to solve these problems, is whether to centralize or decentralize.
Decentralize
When decentralizing, each POP makes a decision for each pipe independently from the other POPs. The advantage to this is that there’s no single point of failure. Managing it will be harder, however, and deciding to bypass more than one internet connection across POPs will require coordination across those POPs.
Centralize
When an internet connection is congested, the collector notifies the controller, and provides a list of IPs that are under attack. The controller then chooses which action to take, and how many internet connections to make the decision on. It can gather more information about the attacked range from other POPs, although the main problem is that POPs depend on the controller to take action – if the controller is lost, the system goes down.
After weighing up the various pros and cons, we decided to go with the centralized option, and to have more than one controller for redundancy.
Enforcement
After a decision is made on how to deal with a congested internet-connection, we need to enforce that decision, for which we had two methods:
BGP communities
The enforcer can establish a BGP peer with the POP routers and, when an action needs to be taken on an IP prefix, we can advertise the IP range with high local-preference and add a BGP community that will signal the router to enforce the decision.It’s a fast method, but what happens if the enforcer fails? This might impact production.
Configure the device
We can push configuration to the router and use BGP policy to influence the IP range advertisement. This is slower than the BGP communities, but there’s no dependency on a new component.
We decided to configure the device and avoid creating a high priority component.
Kafka
We needed a reliable way to pass messages between the components – we can’t afford for a message to get lost, or improperly handled. Furthermore, if we had more than one SDNOC server, we needed a way to perform load sharing between them.
We decided to use Kafka – it’s widely used in Imperva’s infrastructure so it was an easy decision.
Each collector is a Kafka producer. The collector sends messages to a Kafka topic called congested internet-connection.
The Kafka server assigns the message to a partition, one for each SDNOC server.
When a new SDNOC server joins the cluster the Kafka server automatically creates it a new partition and starts to assign messages to it.
The SDNOC uses Kafka streams which simplify all the Kafka auto-assignments, partitions and so on.
A congested internet connection message is received from Kafka, containing information on which IP is causing the congestion.
SDNOC then checks if other internet-connections are congested, and sends a message through Kafka to all collectors to report how much bandwidth each internet-connection has for the range.
SDNOC notifies Kafka that the message reporting the congestion has been handled.
The collector collects information for the IP range and sends it to SDNOC through Kafka. In order to make sure all the messages are handled by the same SDNOC server, the topic key for the message will be the IP range. This means that all the messages with the same key are assigned to the same partition.
The SDNOC server will now have a complete view of the IP range bandwidth for each internet connection. It can now decide which action to take, again using Kafka to send messages to all enforcers to divert the range from congested internet connections.
Rollout
There’s always a risk of having bugs, and bugs in SDNOC can cause a big impact. Imagine, for example, that the system decides to bypass a range from all internet connections, advertise a range when an attack isn’t over, or flap a route, causing it to be BGP-dampened.
For this reason, we decided to rollout slowly.
In the first step, the system suggested our NOC actions, and our NOC engineers provided feedback on whether those actions were correct or not.
Next, after the NOC engineer had approved the suggestion, the system would push the action to the network.
We later allowed the system to take action automatically, but only for the IP ranges that it served.
Summary
The system is built from four parts – a collector that collects metrics about the internet connections and reports when one is congested; a controller that makes the decisions; Kafka to pass messages; and an enforcer.
Now, when we have a congested pipe, the time to react is under two minutes. To illustrate this, here’s a graph for a 1G internet connection that became congested under attack, SDNOC migrated the attack under 16 seconds:

Side effects
We had problems monitoring a single port with two internet connections separated with VLANs when we used SNMP, as our network devices don’t support traffic counters for each VLAN assigned to the port.
We’re now benefiting from the collector, and pushing the metrics to grafana to see how much we utilize the different internet connections on the same port.
The post When Bandwidth Doesn’t Last appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Omer Shtivi. Read the original post at: https://www.imperva.com/blog/when-bandwidth-doesnt-last/
