

Revisiting 2000 cuts using Binary Ninja’s new decompiler
It’s been four years since my blog post “2000 cuts with Binary Ninja.” Back then, Binary Ninja was in a private beta and the blog post response surprised its developers at Vector35. Over the past few years I’ve largely preferred to use IDA and HexRays for reversing, and then use Binary Ninja for any scripting. My main reason for sticking with HexRays? Well, it’s an interactive decompiler, and Binary Ninja didn’t have a decompiler…until today!
Today, Vector35 released their decompiler to their development branch, so I thought it’d be fun to revisit the 2000 cuts challenges using the new decompiler APIs.
Enter High Level IL
The decompiler is built on yet another IL, the High Level IL. High Level IL (HLIL) further abstracts the existing ILs: Low Level IL, Medium Level IL, and five others largely used for scripts. HLIL has aggressive dead code elimination, constant folding, switch recovery, and all the other things you’d expect from a decompiler, with one exception: Binary Ninja’s decompiler doesn’t target C. Instead, they’re focusing on readability, and I think that’s a good thing, because C is full of many idiosyncrasies and implicit operations/conversions, which makes it very difficult to understand.
Using one of our 2000 cuts challenges, let’s compare Binary Ninja’s decompiler to its IL abstractions.
First, the original disassembly:
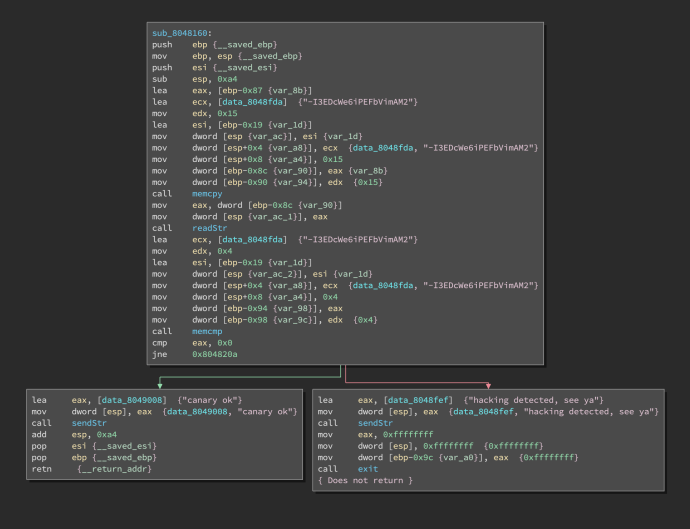
ASM (interactive version)
The ASM disassembly has 43 instructions, of which three are arithmetic, 27 memory operations (loads, stores), four transfers, one comparison, and eight control flow instructions. Of these instructions, we care mainly about the control flow instructions and a small slice of memory operations.
Next, Low Level IL (LLIL):
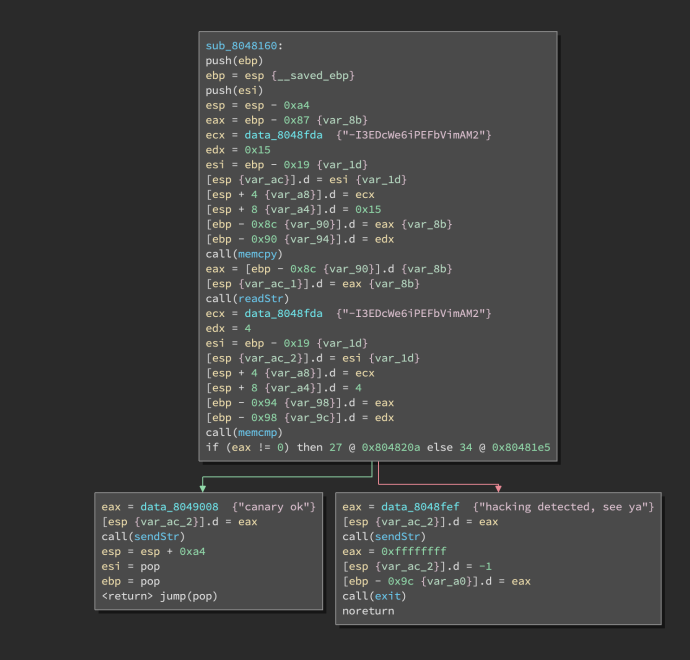
LLIL (interactive version)
LLIL mode doesn’t remove any instructions; it simply provides us a consistent interface to write scripts against, regardless of architecture being disassembled.
With Medium Level IL (MLIL), things start to get better:
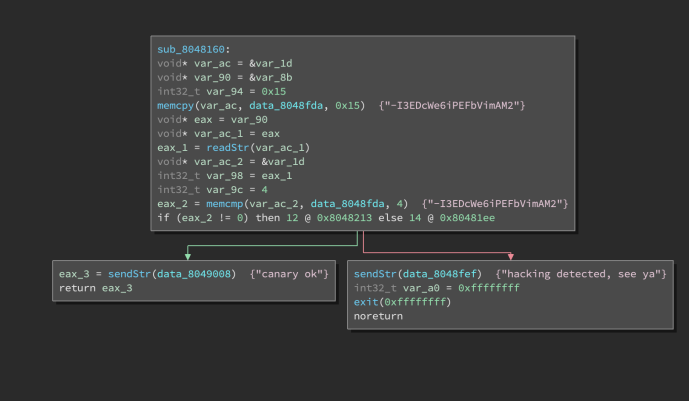
MLIL (interactive version)
In MLIL, stack variables are identified, dead stores are eliminated, constants are propagated, and calls have parameters. And we’re down to 17 instructions (39% of the original). Since MLIL understands the stack frame, all the arithmetic operations are removed and all the “push” and “pop” instructions are eliminated.
Now, in the decompiler, we’re down to only six instructions (or eight, if you count the variable declarations):
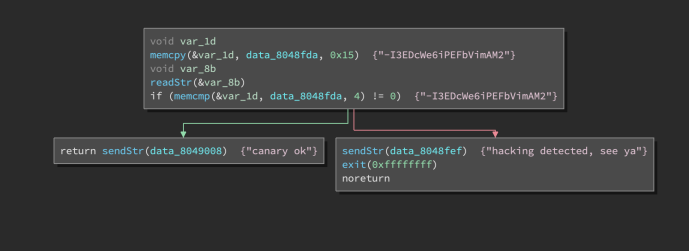
HLIL
Also available in linear view:
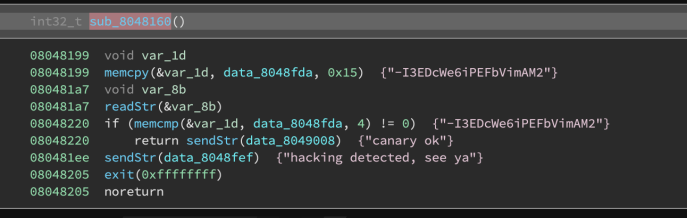
HLIL Linear View
Using the new decompiler API to solve 2000 cuts
For the original challenge, we had to extract hard-coded stack canaries out of hundreds of nearly identical executables. I was able to do this with very little difficulty using the LLIL API, but I had to trace some values around and it was a bit unergonomic.
Let’s try it again, but with the HLIL API1:
Running the script produces the desired result:

We quickly process 1000 cuts
Conclusion
The HLIL solution is a bit more concise than our original, and easier to write. Overall, I’m enjoying the Binary Ninja’s new decompiler and I’m pretty excited to throw it at architectures not supported by other decompilers, like MIPS, 68k, and 6502. Hopefully, this is the decade of the decompiler wars!
If you’re interested in learning more about Binary Ninja, check out our Automated Reverse Engineering with Binary Ninja training.
Footnotes
- For help writing Binary Ninja plugins that interact with the ILs, check out my bnil-graph plugin, which was recently updated to support HLIL.
*** This is a Security Bloggers Network syndicated blog from Trail of Bits Blog authored by Ryan Stortz. Read the original post at: https://blog.trailofbits.com/2020/04/17/revisiting-2000-cuts-using-binary-ninjas-new-decompiler/
