Last summer the BBC technology program “
Click” came to visit the lab for a special called “
Can Technology Solve the Opioid Crisis?” One of the points we stressed with
@NickKwek was that when we report opiods and fentanyl-related posts to Facebook the objective is not to take down THAT POST, but rather to help Facebook’s automated tools update their models of what offensive drug sales content looks like.
Last week we had an opportunity to see what that looks like in action as Facebook released their transparency report for Q3 2019. Facebook’s Transparency report is divided into two major sections which each have two subsections. “Enforcement of our Standards” covers “Community Standards Enforcement” and “Intellectual Property Infringement.” The other major section, “Legal Requests” is divided into “Government Requests for User Data” and “Content Restrictions Based on Local Law.”
The November 2019 transparency report for Community Standards looks at ten categories of content on Facebook and four categories of content on Instagram.
In this post, we’ll look primarily at the statistics for “Regulated Goods: Drugs and Firearms” but the other categories on Facebook are:
- Adult Nudity and Sexual Activity
- Bullying and Harassment
- Child Nudity and Sexual Exploitation of Children
- Fake Accounts
- Hate Speech
- Spam
- Terrorist Propaganda
- Violent and Graphic Content
- Suicide and Self-injury
On Instagram, the other categories are:
- Child Nudity and Sexual Exploitation of Children
- Suicide and Self-injury
- Terrorist Propaganda
Facebook has shared previously about our work to reduce terrorist content on their platform. See their “Hard Questions” blog post — “
Are We Winning the War on Terrorism Online.” In this most recent report, they share that “Our proactive rate for detecting content related to al-Qaeda, ISIS and their affiliates remained above 99% in Q2 and Q3 2019, while our proactive rate for all terrorist organizations in Q2 and Q3 2019 is above 98%.”
What does that mean? It means that through the power of machine learning, when someone posts content trying to “express support or praise for groups, leaders, or individuals involved in terrorist activities” the content is removed automagically without the need for anyone to report it 98-99% of the time!
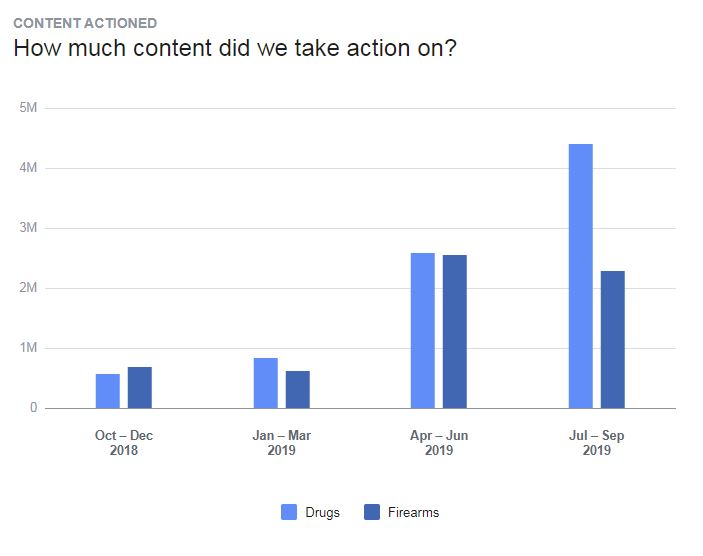
As Facebook has focused on identifying drug-related content, the number of detections has risen. That’s likely from two reasons — one, they are now discovering content that previously would have remained unreported in the past; but also two, frustrated users are attempting to post their drug sales information in more ways trying to get past the blocks — and largely failing to do so.
Drug related posts actioned:
- 572,400 posts in Q4 2018
- 841,200 posts in Q1 2019
- 2,600,000 posts in Q2 2019
- 4,400,000 posts in Q3 2019
When I attended Facebook’s Faculty Summit all the way back in 2016 they had me hooked from the very beginning of the day when Facebook’s Engineering Director Joaquin Quinonero Candela gave his opening keynote. All of this amazing machine learning technology that people like Dr. Candela had created to help improve online ad delivery were ALSO being used to make the platform as safe as possible against a wide variety of threats. I was especially excited to learn about the work of Wendy Mu. At the time Wendy’s bio said “Wendy is an engineering manager on Care Machine Learning, which leverages machine learning to remove abusive content from the site. Over the last three years at Facebook, she has also worked on Site Integrity, Product Infrastructure, and Privacy.” Wendy and her team are inventing and patenting new ways of applying machine learning to this problem space. Nektarios Leontiadis “a research scientist on the Threats Infrastructure Team” with a PhD in online crime modeling and prevention from Carnegie Mellon and Jen Weedon, previously at FireEye, were some of the other folks I met there that made such a profound impression on me! Since then, the UAB Computer Forensics Research Lab has partnered with Facebook on many projects, but quite a few have taken the form of “what would a human expert label as offending content in this threat space?”
This is where “supervised machine learning” comes into play.
The simplest version of Supervised Machine Learning is the “I am not a Robot” testing that Google uses to label the world. You may be old enough to remember when Google perfected their Google Books project by asking us to human label all of the unreadable words that their scanner lifted from old books, but which were not properly recognized by their OCR algorithm. Then we were asked to label the address numbers found on buildings and mailboxes and then later to choose cars, bicycles, traffic lights, and more recently cross walks as it seems we are not teaching future self-driving cars how to not drive over pedestrians.
This works well for “general knowledge” types of supervised learning. Anyone over the age of three can fairly reliably tell the difference between a Cat and a Dog. When people talk about supervised machine learning, that is the most common example, which comes from the concept of “Convolutional Neural Networks”. Do a search on “machine learning cat dog” and you’ll find ten thousand example articles, such as this image from Booz Allen Hamilton.
We’re working on something slightly different, in that the labeling requires more specialized knowledge than “Cat vs. not Cat”. Is this chemical formula a Fentanyl variant? Is the person in this picture the leader of a terrorist organization? What hashtags are opioid sellers using to communicate with one another once their 100 favorite search terms are being blocked by Facebook and Instagram?
In this chart, the data provided by UAB is primarily part of that “Data Gathering” section … by bringing forensic drug chemists into the lab, we’re able to provide a more sophisticated set of “labelers” than the general public. Part of our “Accuracy testing” then comes in on the other end. After the model built from our data (and the data from other reporters) is put into play, does it become more difficult for our experts to find such content online?
Looking at the Transparency Report’s Community Standards section, the results are looking really great!
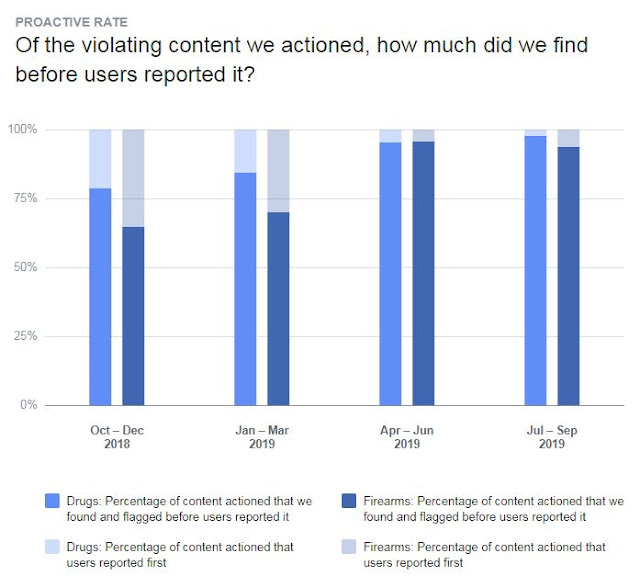
In the fourth quarter of 2018, only 78.6% of the offending drug content at Facebook was being removed by automation. 22% of it didn’t get deleted until a user reported it, by clicking through the content reporting buttons. By the 3rd Quarter of 2019, 97.6% of offending drug content was removed at Facebook by applying automation!
In Q4 2018, 122,493 pieces of drug content were “manually reported” while 449,906 pieces were “machine identified.”
In Q3 2019, 105,600 pieces of drug content were “manually reported”, but now about 4.3 million pieces were “machine identified.”
Terror Data
Twitter also produces a
Transparency report and also shares information about content violations, but in most categories lags far behind Facebook on automation. Twitter’s latest transparency report says that “more than 50% of Tweets we take action on for abuse are now being surfaced using technology. This compares to just 20% a year ago.” The one category where they seem to be doing much better than that is terrorism. Their last report covered the period January to June 2019. Twitter does not share statistics about drug sales content, but does have Terrorism information. During this period, 115,861 accounts were suspended for violations related to the promotion of terrorism. 87% of those accounts were identified through internal tools.
Facebook doesn’t share these numbers by unique accounts, but rather by the POSTS that have been actioned. In the Q3 2019 data, Twitter actioned 5.2 million pieces of terror content. 98.5% of those posts were machine identified.