

Protecting Software Against Exploitation with DARPA’s CFAR
Today, we’re going to talk about a hard problem that we are working on as part of DARPA’s Cyber Fault-Tolerant Attack Recovery (CFAR) program: automatically protecting software from 0-day exploits, memory corruption, and many currently undiscovered bugs. You might be thinking: “Why bother? Can’t I just compile my code with exploit mitigations like stack guard, CFG, or CFI?” These mitigations are wonderful, but require source code and modifications to the build process. In many situations it is impossible or impractical to change the build process or alter program source code. That’s why our solution for CFAR protects binary installations for which source isn’t available or editable.
CFAR is very intuitive and deceptively simple. The system runs multiple versions, or ‘variants,’ of the software in parallel, and uses comparisons between these variants to identify when one or more have diverged from the others in behavior. The idea is akin to an intrusion detection system that compares program behavior against variants of itself running on identical input, instead of against a model of past behavior. When the system detects behavioral divergence, it can infer that something unusual, and possibly malicious, has happened.
Like all DARPA programs, CFAR is a large and difficult research problem. We are only working on a small piece of it. We have coordinated this blog post with our teammates – Galois, Immunant, and UCI – each of whom has more details about their respective contributions to the CFAR project.
We are excited to talk about CFAR not just because it’s a hard and relevant problem, but because one of our tools, McSema, is a part of our team’s versatile LLVM-based solution. As a part of this post, we get to show examples of lesser-known McSema features, and explain why they were developed. Perhaps most exciting of all, we’re going to show how to use McSema and the UCI multicompiler to harden off-the-shelf binaries against exploitation.
Our CFAR Team
The overall goal of CFAR is to detect and recover from faults in existing software without impacting core functionality. Our team’s responsibility was to produce an optimal set of variants to mitigate and detect fault-inducing inputs. The other teams were responsible for the specialized execution environment, for red-teaming, and so on. Galois’s blog post on CFAR describes the program in greater detail.
The variants must behave identically to each other and to the original application, and present compelling proof that behavior will remain identical for all valid inputs. Our teammates have developed transformations and provided equivalence guarantees for programs with available source code. The team has devised a multicompiler-based solution for variant generation using the Clang/LLVM toolchain.
McSema’s Role
We have been working on generating program variants of binary-only software, because source code may be unavailable for proprietary or older applications. Our team’s source code based toolchain works at the LLVM intermediate representation (IR) level. Transforming and hardening programs at the IR level allows us to manipulate program structure without altering the program’s source code. Using McSema, we could translate binary-only programs to LLVM IR, and re-use the same components for both source-level and binary-only variant generation.
Accurately translating programs for CFAR required us to bridge the gap between machine-level semantics and program-level semantics. Machine-level semantics are the changes to processor and memory state caused by individual instructions. Program-level semantics (e.g., functions, variables, exceptions, and try/catch blocks) are more abstract concepts that represent program behavior. McSema was designed to be a translator for machine level semantics (the name “McSema” derives from “machine code semantics”). However, to accurately transform the variants required for CFAR, McSema would have to recover program semantics as well.
We are actively working to recover more and more program semantics, and many common use-cases are already supported. In the following section we’ll discuss how we handle two particularly important semantics: stack variables and global variables.
Stack Variables
The compiler can place the data backing function variables in one of several locations. The most common location for program variables is the stack, a region of memory specifically made for storing temporary information and easily accessible to the calling function. Variables that the compiler stores on the stack are called… stack variables!
int sum_of_squares(int a, int b) {
int a2 = a * a;
int b2 = b * b;
return a2+b2;
}
|
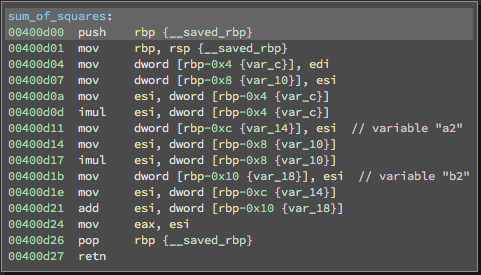 |
| Figure 1: Stack variables for a simple function shown both at the source code level, and at the binary level. At the binary level, there is no concept of individual variables, just bytes in a large block of memory. | |
When attackers turn bugs into exploits, they often rely on stack variables being in a specific order. The multicompiler can mitigate this class of exploits by generating program variants, where no two variants have stack variables in the same order. We wanted to enable this stack variable shuffling for binaries, but there was a problem: there is no concept of stack variables at the machine code level (Figure 1). Instead, the stack is just a large contiguous block of memory. McSema faithfully models this behavior and treats the program stack as an indivisible blob. This, of course, makes it impossible to shuffle stack variables.
Stack Variable Recovery
The process of converting a block of memory that represents the stack into individual variables is called stack variable recovery. McSema implements stack variable recovery as a three-step process.
First, McSema identifies stack variable bounds during disassembly, via the disassembler’s (e.g., IDA Pro’s) heuristics and, where present, DWARF-based debugging information. There is prior research on identifying stack variable bounds without such hints, which we plan to utilize in the future. Second, McSema attempts to identify which instructions in the program reference which stack variable. Every reference must be accurately identified, or the resulting program will not function. Finally, McSema creates an LLVM-level variable for each recovered stack variable and rewrites instructions to reference these LLVM-level variables instead of the prior monolithic stack block.
Stack variable recovery works for many functions, but it isn’t perfect. McSema will default to the classic behavior of treating the stack as a monolithic block when it encounters functions with the following characteristics:
- Varargs functions. Functions that use a variable number of arguments (like the common printf family of functions) have a variable sized stack frame. This variance makes it difficult to determine which instruction references which stack variable.
- Indirect stack references. Compilers also rely on a predetermined layout of stack variables, and will generate code that accesses a variable via the address of an unrelated variable.
- No stack-frame pointer. As an optimization, the stack-frame pointer can serve as a general purpose register. This optimization makes it difficult for us to detect possible indirect stack references.
Stack variable recovery is a part of the CFG recovery process, and is currently implemented in the IDAPython CFG recovery code (in collect_variable.py). It can be invoked via the --recover-stack-vars argument to mcsema-disass. For an example, see the code accompanying this blog post, which is described more in the Lifting and Diversifying a Binary section.
Global Variables
Global variables can be accessed by all functions in a program. Since these variables are not tied to a specific function, they are typically placed in a special section of the program binary (Figure 2). As with stack variables, the specific ordering of global variables can be exploited by attackers.
bool is_admin = false;
int set_admin(int uid) {
is_admin = 0 == uid;
}
|
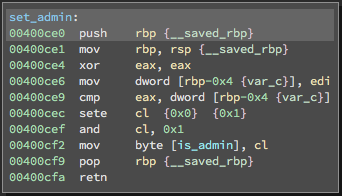  |
| Figure 2: Global variables as seen at source code level and at the machine code level. Global variables are typically placed into a special section in the program (in this case, into .bss). | |
Like the stack, McSema treats each data section as a large block of memory. One major difference between stack and global variables is that McSema knows where global variables start, because they are referenced directly from multiple locations. Unfortunately that is not enough information to shuffle around the global variable layout. McSema also needs to know where every variable ends, which is harder. Currently we rely on DWARF debug information to identify global variable sizes, but look forward to implementing approaches that would work on binaries without DWARF information.
Currently, global variable recovery is implemented separately from normal CFG recovery (in var_recovery.py). That script creates an “empty” CFG, filled with only global variable definitions. The normal CFG recovery process will further populate the file with the real control flow graph, referencing the pre-populated global variables. We will show an example of using global variable recovery later.
Lifting and Diversifying A Binary
In the remainder of this blog post, we’ll refer to the process of generating new program variants via the multicompiler as ‘diversification.’ For this specific example, we will lift and diversify a simple C++ application that uses exception handling (including a catch-all clause) and global variables. While this is just a simple example, program semantics recovery is meant to work on large, real applications: our standard test program is the Apache2 web server.
First, let’s familiarize ourselves with the standard McSema workflow (i.e. without any diversification), which is to lift the example binary to LLVM IR, then compile that IR back down into a runnable program. To get started, please build and install McSema. We provide detailed instructions in the official McSema README.
Next, build and lift the program using the provided script (lift.sh). The script will need to be edited to match your McSema installation.
After running lift.sh, you should have two programs: example and example-lift, along with some intermediate files.
The example program squares two numbers and passes the result to the set_admin function. If both the numbers are 5, then the program throws the std::runtime_error exception. If the numbers are 0, then the global variable is_admin is set to true. Finally, if two numbers are not supplied to the program, then it throws std::out_of_range.
The four different cases can be demonstrated via the following program invocations:
$ ./example |
We can see that example-lifted, the same program as lifted and re-created by McSema, behaves identically:
$ ./example-lifted |
Now, lets diversify the lifted example program. To start, install the multicompiler. Next, edit the lift.sh script to specify a path to your multicompiler installation.
It’s time to build the diversified version. Run the script with the diversify argument (./lift.sh diversify) to generate a diversified binary. The diversified example looks different at the binary level than the original (Figure 3), but has the same functionality:
$ ./example-diverse |
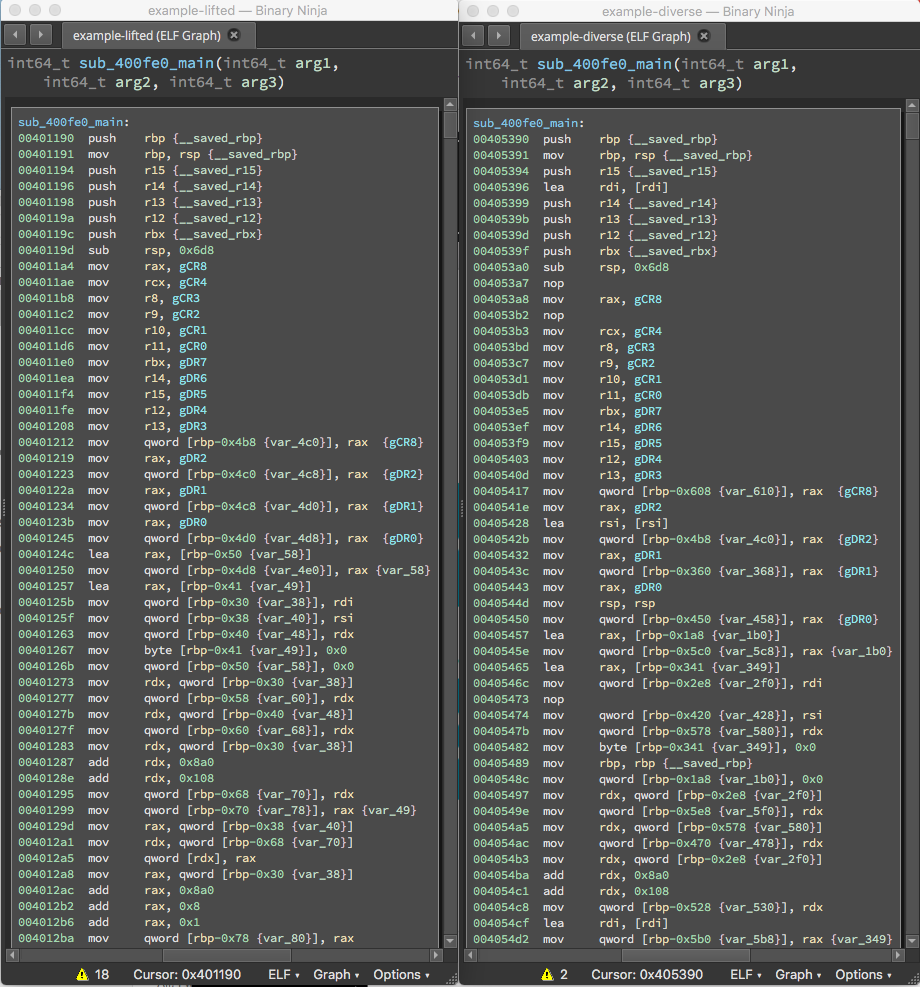 |
| Figure 3: The normal lifted binary (left) and its diversified equivalent (right). Both binaries are functionally identical, but look different at the binary level. Binary diversification protects software by preventing certain classes of bugs from turning into exploits. |
Open example-lifted and example-diversified in your favorite disassembler. Your binaries may not be identical to the ones in the screenshot, but they should be different from each other.
Let’s review what we did. It’s really quite amazing. We started by building a simple C++ program that used exceptions and global variables. Then we translated the program into LLVM bitcode, identified stack and global variables, and preserved exception-based control flow. We then transformed it using the multicompiler, and created a new, diversified binary with the same functionality as the original program.
While this was just a small example, this approach scales to much larger applications, and provides a means to rapidly create diversified programs, whether starting with source code or with a previous program binary.
Conclusion
We would first like to thank DARPA, without whom this work would not be possible, for providing ongoing funding for CFAR and other great research programs. We would also like to thank our teammates — Galois, Immunant and UCI — for their hard work creating the multicompiler, transformations, providing equivalence guarantees for variants, and for making everything work together.
We are actively working to improve stack and global variable recovery in McSema. Not only will these higher-level semantics create more diversification and transformation opportunities, but they will also allow for smaller, leaner bitcode, faster re-compiled binaries, and more thorough analyses.
We believe there is a bright future for CFAR and similar technologies: the number of available cores per machine continues to increase, as does the need for secure computing. Many software packages can’t utilize these cores for performance, so it is only natural to use the spare cores for security. McSema, the multicompiler, and other CFAR technologies show how we can put these extra cores in service to stronger security guarantees.
If you think some of these technologies can be applied to your software, please contact us. We’d love to hear from you. To learn more about CFAR, the multicompiler, and other technologies developed under this program, please read our teammates’ blog posts at the Galois blog and the Immunant blog.
Disclaimer
The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
*** This is a Security Bloggers Network syndicated blog from Trail of Bits Blog authored by Artem Dinaburg. Read the original post at: https://blog.trailofbits.com/2018/09/10/protecting-software-against-exploitation-with-darpas-cfar/
