

ReDoS in Go
Go Programming Language (also known as Golang) is an open source programming language created by Google. Go is compiled, is statically typed as in C (with garbage collection), with limited structural typing, memory safety features and CSP-style concurrent features.
In this blog post, we will recap Go’s security posture facing Regular Expression Denial of Service (ReDoS) attacks. But first, let’s start by explaining the concept of ReDoS and how such attacks can be exploited and mitigated. This blog post includes a set of practical examples using different programming languages, aiming to show how Go implementation avoids ReDoS.
The topic of this report was motivated from ongoing research on the topic of Go security, where we aim to discover vulnerabilities lurking in Go packages.
func sqli() {
username := r.Form.Get(“username”)
sql := “SELECT * FROM user WHERE username=’” + username + “‘” row_fullname := db.QueryRow(sql)
fmt.Printf(“Welcome, %sn”, row_fullname)
}
Listing 1: Golang SQLi example
Regular Expression Denial of Service (ReDoS) is an algorithmic complexity attack that provokes a Denial of Service (DoS). ReDos attacks are caused by a regular expression that takes very long time to be evaluated, exponentially related with the input size. This exceptionally long time in the evaluation process is due to the implementation of the regular expression in use, for example, recursive backtracking ones.
Regular Expressions
A regular expression, better known as a ‘regex’, is a sequence of characters that defines a search pattern, used to search for one or more characters within a string. One of the useful usages of a regex is information validation, i.e., ensuring that only properly formed data is being submitted.
For example, let’s pretend that we want to apply a regular expression over the username input of listing. Thus, a simple regex could be:
/^[a-zA-Z0-9_-]{3,10}$/
Listing 2: Regex example 1
The regular expression is contained between the slash characters and in the pattern 2 regex; we start by telling the parser to find the beginning of the string (ˆ), followed by any lowercase letter (a-z), uppercase letter (A-Z), number (0-9), an underscore, or a hyphen. The 3,10 section makes sure that the entered string has a length between three and ten characters. Finally, the $ represents the end of the string. For this regex, if the input ”checkmarx” was used it would match the pattern:
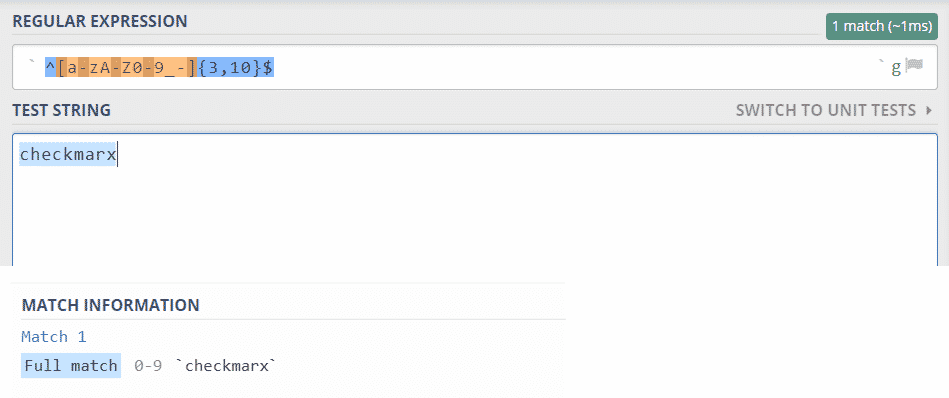
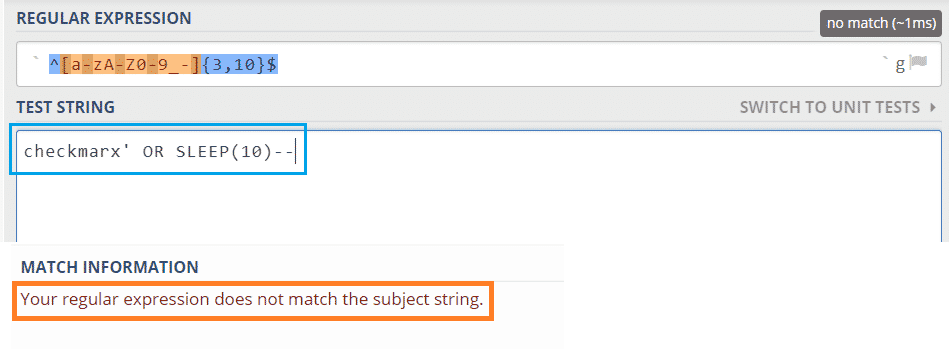
On the other hand, if a string like ”checkmarx’ OR SLEEP(10)–” was to be used, it would not match the pattern.
Evil Regular Expressions
Even though the benefits of using regexs for input validations are great, depending on the way they are written and the engine used, a malicious user can leverage it and make the application or service unavailable. Thus, evil regexs are the root cause of the ReDoS issue. They are considered evil or malicious if they can stuck on crafted input. To understand this better, let’s consider the following regular expression:
/A(B|C+)+D/
Listing 3: Evil Regex example 1
In this case scenario, this regex pattern starts by searching for the character ’A’. Then, the following string must either be the character ’B’ or one or more ’C’s, (B|C+). The next + indicates that it can search for one or more occurrences of the previous string. Finally, the ’D’ ensures that the string is terminated by the character ’D’. To match this regular expression, any input of the following type would be accepted:
ABCD
ABCBD
ACD
ACBD
Listing 4: Valid input for Evil regex 1
To show the differences between the implementations used by different languages, we created simple programs in four different languages: Python, JavaScript, PHP and Go. All created programs use the regex from example 3. This benchmark was done incrementing passed inputs, allowing us to visually understand the different behaviors of the program depending on the variations of the inputs.
In the example code from listing 5, we show a simple Python implementation to evaluate the evil regex. We start by testing the valid inputs from listing 4. Then, we send malicious inputs to try to stuck to the program.
regex = r”A(B|C+)+D”
test_str = raw_input(“Enter the string: “)
matches = re.finditer(regex, test_str) (…)
print (“It took: %s seconds” % elapsedTime)
Listing 5: Python Regex compiler
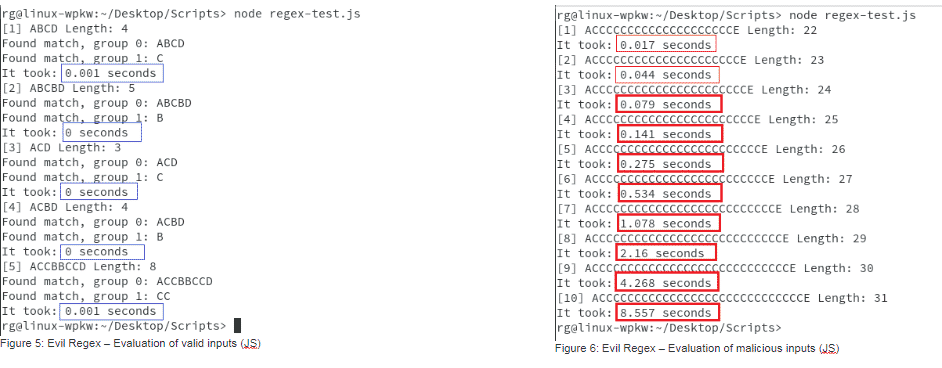
To craft malicious inputs, we started by incrementing valid and invalid inputs, and tweaking it according to the time differences between them. At some point, some relevant discrepancies were found. In figure 4, we show the attempted malicious payloads and the matching elapsed time for evaluation. We see that when a malicious input payload of type AC+E, where + represents one or more occurrences of the character C, is sent with more than 20 Cs, the elapsed time starts to double for each new C.

The same principle was applied to the other languages and the input cases were maintained in order to compare the results. The next example is for JavaScript. Listing 6 shows the JS code snippet:
const regex = /A(B|C+)+D/g; (…)
let m;
while ((m = regex.exec(str)) !== null) { (…)
} (…)
console.log(“It took: ” + seconds + ” seconds”);
Listing 6: JS Regex compiler
The obtained results for the JavaScript implementation are as follows:
The next example is PHP:
$re = ‘/A(B|C+)+D/’;
preg_match_all($re, $str, $matches, PREG_SET_ORDER, 0); (…)
echo $timediff.” seconds”;
Listing 7: PHP Regex compiler
Where the results from figures 7 and 8 were produced:

Finally, an example for Go. We created the following program:
func main() {
re := regexp.MustCompile(`A(B|C+)+D`) (…)
for i, match := range re.FindAllString(str, -1) { fmt.Println(match, “found at index”, i)
} (…)
fmt.Println(“It took:”, elapsed.Seconds(), “seconds”)
}
Listing 8: Go Regex compiler
And produced the following results:

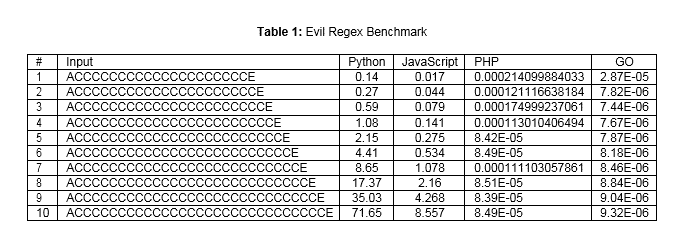
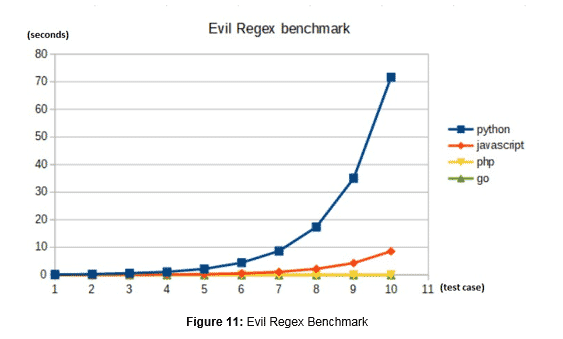
We can see that the results from PHP (8) and Go (10) implementations are much different from the Python (4) and JavaScript (6) results. The malicious inputs used in Python and JavaScript generated exponential time increments, versus the linear time responses for PHP and Go.
In the PHP regex implementation, we used the Perl Compatible Regular Expressions (PCRE) library 1, which uses
backreferences. The official regex package [2] implemented in Go uses the RE2 engine 2, which does not support backreferences, and guarantees a linear time execution while avoiding regex denial of service.
In table 1, we summarize the obtained results for each programming language, where it is displayed the elapsed time in seconds for each input that was tested. For the purpose of this post, we only tested ten inputs, starting with 20 ’C’ characters and incrementing one unit. This clarifies that for the Python and JavaScript implementations the time doubles when a new C is added.
Finally, in the chart seen in figure 11, it become visually clear what the discrepancies are between the results and places of the performances of PHP and Go side by side.
Behind the Curtains
The most commonly used algorithms to implement regular expression matching are:
- Perl-based
- NFA-based
So far, we have seen how the PHP implementation uses the PCRE, Perl-based, and Go uses the RE2. In any case, to accomplish the regular expression matching, the engine builds a Nondeterministic Finite Automaton (NFA), which is a finite state machine where for each pair of state and input symbol, there may be several possible next states. Hence, for each input symbol, the NFA will transit to a new state until all the input symbols have been consumed. This will try all paths of the NFA until an accepting state, i.e., where a match occurred or all the paths but with no match.
Considering the regex ˆ(a+)+$ and its correspondent NFA:
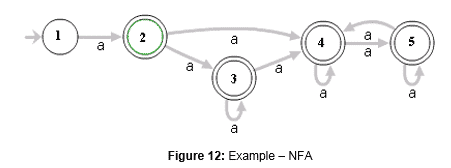
We can use the same methodology of inputting different sizes in order to understand the NFA behavior. To this, if the input aaaaX is chosen, 16 possible paths will exist in the graph from figure 12.
If the input is modified to aaaaaaaaaaX, it will have 1024 steps. And if changed to aaaaaaaaaaaaaaaaX, 65536 possible paths will be generated. Each additional ”a” will double this number. This behavior is an extreme case and happens because the algorithm will go through all the possible paths until failing.
What happens behind the curtains is that any time a symbol is being tested by the engine and it fails to match the next one, it will backtrack and look for another way to compile the previous symbol. If this path gets too long, the number of backtracking steps will eventually become very large, resulting in catastrophic backtracking, leading to a possible denial of service.
If we take the example of the regular expression from listing 3, and with the help from the regex101 3 website, we can resume this behavior in a table, where displayed is the number of steps taken for a target input string.
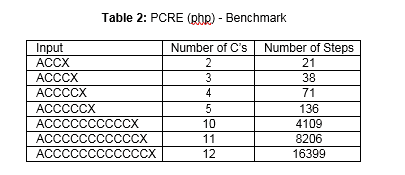
From table 2, it is clear that each time we incremented the number of C’s by one unit, the engine took twice the number of steps. Using this engine from the regex101 website, if more than 998 C’s are used, it will respond with a catastrophic backtracking message:

This is the turning point between the PHP and Go implementations. In example 2.2, we saw that for the input used, the results in terms of elapsed time were very similar, but we did not test for extremely large inputs, as seen in figure 13, crashes the PHP implementation. This is avoided in Go.
As a matter of fact, all programming language engines (from this website) will have disastrous behaviors with this input – except for Go. JavaScript will respond with a timeout and the Python with a catastrophic backtracking. As for Go, it will resolve the string input in approximately 218ms. These results can be consulted here.
2.3.1 Easter Egg
It is also important that websites testing regular expressions can properly detect catastrophic cases:
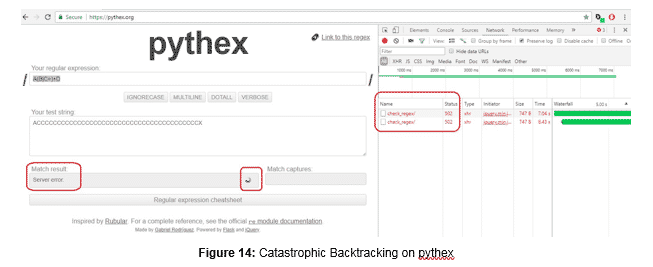
A malicious user could take advantage of the lack of validation in this website to provoke a denial of service. Another example happens in the https://www.debuggex.com/ website. When a vulnerable regular expression is used with a malicious input, it will hang the page.

In this blog post, we recapped what a regular expression is and how can it be leveraged to provoke a denial of service. We go through a set of examples where behaviors of different engines are shown. Specifically, we emphasize the Go behavior.
Despite possible recommendations and workarounds to avoid ReDoS, which revolve around the usual input sanitization, the best measure is to target the root cause, and so, focus on the implemented algorithm.
The implementation provided by the Go package (regexp) is guaranteed to run in time linear in the size of the input. A property that is not guaranteed by most open source implementations of regular expressions [3].
References
- ReDoS, available at https://www.owasp.org/index.php/Regular expression Denial of Service – ReDoS.
- Package regexp, available at https://golang.org/pkg/regexp/.
- Regular Expression Matching Can Be Simple And Fast , available at https://swtch.com/ rsc/regexp/regexp1.html.
Erez Yalon
Latest posts by Erez Yalon (see all)
- ReDoS in Go – May 7, 2018
- Decrypting JobCrypter – March 19, 2018
- The Top 5 Exfiltration Attacks on WebViews – January 22, 2018
*** This is a Security Bloggers Network syndicated blog from Blog – Checkmarx authored by Erez Yalon. Read the original post at: https://www.checkmarx.com/2018/05/07/redos-in-go/
