

Everyone Is Buying AI Guardrails. But Agents Have the Keys to the Car.
The first wave of AI security looked a lot like a WAF for LLMs: inspect the prompt, filter the output, block the obvious bad patterns.
That was useful. It still is.
But it was built for systems that mostly talked.
Agents are different. They use tools, call APIs, access data, and change things.
The confusion I keep seeing is simple: many teams think securing the model means securing the agent. It does not.
AI security protects the conversation. Agentic security protects the consequence.
The market has been using “AI security” as a bucket for almost everything: prompt injection, jailbreaks, unsafe outputs, model access, AI usage policy, LLM gateways, basic DLP, and model governance. Those are real problems. But they are not the whole problem.
A chatbot talks. An agent acts. A bad chatbot response is a problem, but a bad agent action can become an incident. That is the line the industry is still learning to draw.
A chatbot can hallucinate, leak something in a response, or be manipulated into saying something unsafe. An agent can do all of that, but it can also call a tool, retrieve customer data, issue a refund, update a ticket, change a configuration, trigger a workflow, or touch a system that actually runs the business.
The model is no longer just having a conversation. It is becoming part of an execution path.
The agent is not one thing. It is a body.
The easiest way to explain an agent is with the human body. The LLM is the brain. It reasons, interprets intent, and decides what to do next. The prompt is the ears. It receives the request. The response is the mouth. It communicates the result back. The tools and MCP servers are the hands. They give the agent capabilities. The APIs are the buttons. They are how the agent touches the business. The systems behind those APIs are what the buttons control.
Most AI security conversations focus on the ears, the brain, and the mouth. Was the prompt malicious? Was the response safe? Did the model say something it should not say? Important questions. But incomplete.
Because the hands may still be holding the keys.
You can put a helmet on the brain, install a filter in the ears, and watch what the mouth says. But if the hands can still press the refund button, export the customer list, update the account, or call an internal API with weak authorization, you still have a serious problem.
You secured the conversation. You did not secure the action.
The prompt can look clean while the path is dangerous.
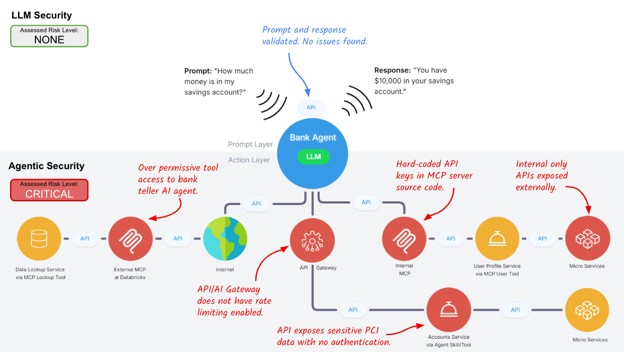
Imagine a customer support agent. A customer asks, “I was charged twice. Can you help?” The prompt looks normal. The model decides to help. The agent calls a billing tool. The billing tool calls an internal API. The API returns account data. The agent issues a credit. The final response looks harmless: “I reviewed your account and issued a credit.”
From the model layer, everything may look fine. No obvious jailbreak. No toxic output. No sensitive data in the final answer. But the path in between may tell a very different story.
Maybe the billing tool was over-permissive. Maybe the MCP server had a hard-coded API key. Maybe the API had no rate limit. Maybe the refund API was never designed for autonomous access.
Now imagine this happening at machine speed 100s of thousands of times before anyone noticed.
The model did not say anything dangerous. The agent took action and impacted revenue.
That is the gap. The risk is not only in the prompt or the response. It is in the execution path between them.
Visibility, governance, and runtime protection are not the same thing.
Agentic security has three jobs: visibility, governance, and runtime protection. Visibility tells you what exists, governance tells you what should be allowed, and runtime protection tells you what is actually happening when the agent is live.
Visibility can tell you which agents exist, where they run, which tools they use, and which APIs they can reach. Governance can tell you which tools are enabled, which identities are used, which policies are missing, and which actions are over-permissive. Runtime protection answers the live question: Is the agent doing something unsafe right now?
A dashboard is not runtime protection. An inventory is not runtime protection. A policy document is not runtime protection. They are necessary, but they are not the same as watching the hands as they move.
Agents need visibility. Agents need governance. But agents also need brakes.
Code tells you what was built. Configuration tells you how it is governed. Runtime tells you what happened.
To understand agentic risk, you need three sources of truth.
Code shows what was built: hard-coded secrets, unsafe tools, missing authorization checks, risky API patterns.
Configuration shows how it is governed: which tools are enabled, which identities are used, which policies apply, who owns it, and which APIs are reachable.
Runtime shows what happened: which prompt led to which tool call, which tool called which API, what data came back, and what action was taken.
This matters because not every agent lives inside a clean managed AI platform. The easy case is a known control plane where you can pull configuration and build a useful dashboard. Useful? Yes. Enough? No.
The harder case is an agent that looks like software: an LLM running in EC2 or Kubernetes, using a custom MCP server, calling internal APIs behind an F5 load balancer, and reaching older systems never designed for autonomous access.
That is not a neat AI product. It is a production application.
And like any production application, you need the full path: prompt to model, model to tool, tool to API, API to data, and back.
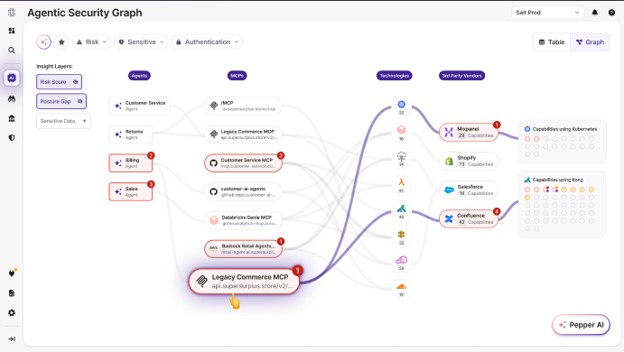
That is the agentic graph: what was built, how it was governed, and what actually happened.
The question should change.
“Do you secure AI?” is now a weak and insufficient question. In fact, almost everyone can say yes.
The better question is: where does your visibility stop? Do you see the model, or also the tools and APIs? Do you provide visibility, governance, and runtime protection, or just one of them? Can you follow the path from prompt to tool to API to downstream action? Can you protect an agent running as a normal workload in EC2, Kubernetes, containers, VMs, or on prem? Can you connect code, configuration, and runtime into one picture?
And maybe most importantly: where does your answer become, “We do not see that part”?
Every security control has a boundary. Good vendors know where that boundary is. Great security teams ask for it directly.
The agents still have the keys to the car.
The first wave of AI security was necessary. It gave us guardrails for prompts, models, and outputs. But agents changed the security question.
It is no longer enough to ask, “What did the model say?” We have to ask what the agent did, which tool it used, which API it called, what data came back, which action was taken, whether it was expected, whether it was allowed, and whether it was safe.
That is the line between AI security and agentic security.
And right now, many enterprises have guarded the model while the agents still have the keys to the car.
Ready to see your Agentic Security Graph? Salt Security is offering a complimentary agentic security assessment so you can map your full agentic attack surface in minutes, not months. Get your free assessment at salt.security/agentic-assessment
The post Everyone Is Buying AI Guardrails. But Agents Have the Keys to the Car. appeared first on Salt Security blog.
*** This is a Security Bloggers Network syndicated blog from Salt Security blog authored by Roey Eliyahu. Read the original post at: https://salt.security/blog/everyone-is-buying-ai-guardrails-but-agents-have-the-keys-to-the-car
