

From Data Chaos to Data Mastery How to Build and Scale Data Lakes with AWS Services

Architecting the Ideal Data Lake Framework
To build a scalable and robust data lake architecture with AWS services, follow these steps:
Define your data lake requirements
Identify the data sources, types of data, and analytics use cases. Determine the required data ingestion frequency and define data governance policies.
Configure Amazon S3
Make an S3 bucket to hold unprocessed data. For improved performance and cost-effectiveness, take into account splitting the data.
Use AWS Glue for data cataloguing
Create a data catalogue using AWS Glue to keep track of data assets, schemas, and metadata. This enables easy discovery and exploration of data within the data lake.
Implement data ingestion pipelines
Use AWS Glue or other ETL tools to build data ingestion pipelines. Extract data from various sources, transform it, and load it into the data lake. Schedule the pipelines to ensure regular updates.
Leverage AWS Glue DataBrew for data preparation
To visually clean, manipulate, and evaluate data, use DataBrew. For guaranteeing data consistency and quality, this step is essential.
Enable data querying with Amazon Athena
Create tables and define schemas in Athena to enable SQL-based querying on the data lake. Optimize query performance by partitioning data and using appropriate data formats.
Enhance analytics capabilities with Amazon Redshift
Use Redshift alongside the data lake to perform complex analytical queries and build data models for reporting and visualization.
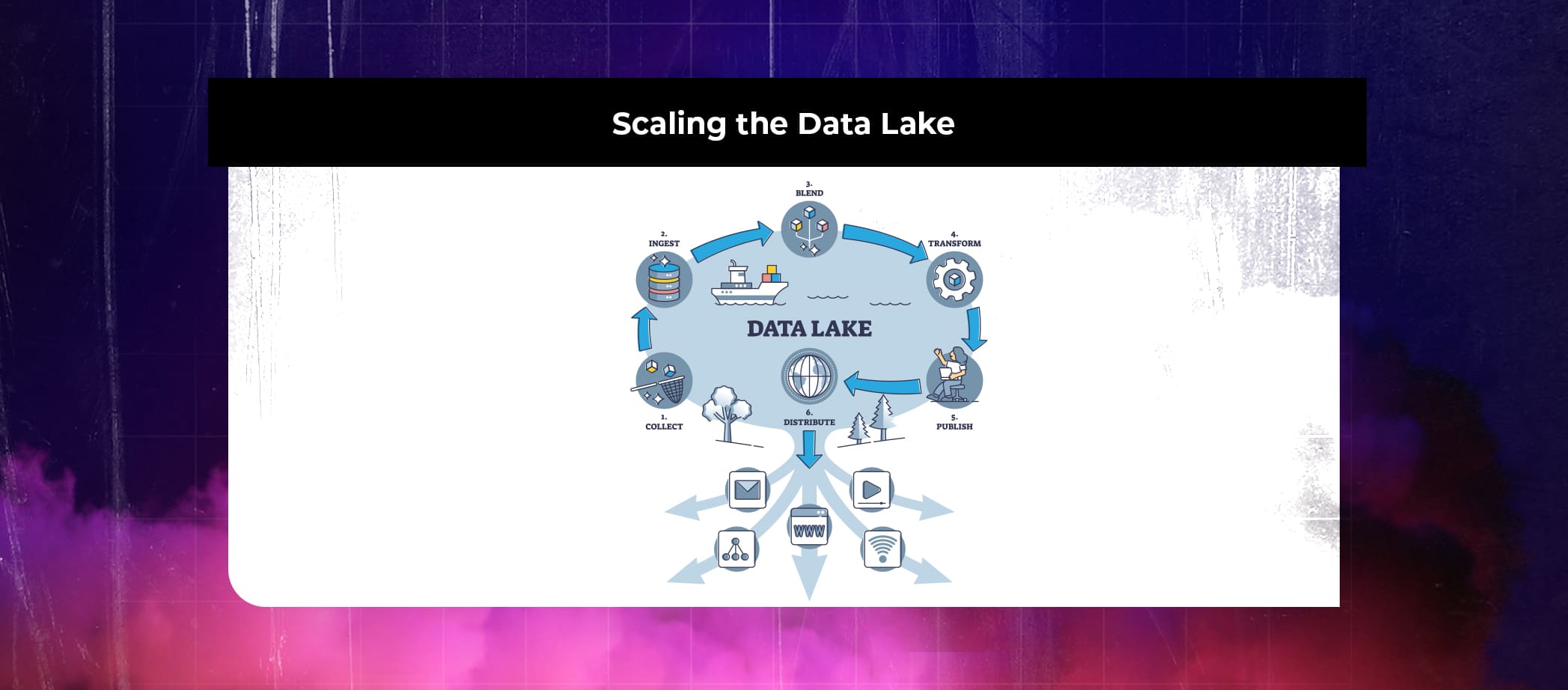
Scaling the Data Lake
As the volume and variety of data grow, it is important to scale the data lake architecture. AWS provides several options for scaling data lakes:
Partitioning and compression
Implement partitioning strategies to optimize query performance and reduce costs. Compress data to save storage space and enhance query speed.
Autoscaling and serverless computing
Utilize serverless services like AWS Glue and Athena to automatically scale resources based on demand. This ensures cost efficiency and reduces administrative overhead.
Data lake governance
Establish data governance practices to manage data access, security, and compliance. Use AWS Identity and Access Management (IAM) to control access to data lake resources.
Monitoring and optimization
Implement monitoring and logging solutions to track data lake performance and identify bottlenecks. Leverage AWS CloudWatch and AWS Glue DataBrew profiling to gain insights and optimize resource utilization.
Also Read: Who is responsible for protecting data in the Cloud?

Get in touch
Don’t forget to share it
The post From Data Chaos to Data Mastery How to Build and Scale Data Lakes with AWS Services appeared first on PeoplActive.
*** This is a Security Bloggers Network syndicated blog from PeoplActive authored by Dariel Marlow. Read the original post at: https://peoplactive.com/from-data-chaos-to-data-mastery-how-to-build-and-scale-data-lakes-with-aws-services/
