

New Chariot Module Nosey Parker Released: An Artificial Intelligence Based Secrets Scanner That Out Sniffs the Competition
Motivation
Sensitive information like passwords, API keys, access tokens, asymmetric private keys, client secrets and credentials are critical components of a secure internet. Virtually any programmatic task involving authentication or security requires developers to work with this kind of data. Unfortunately, this means that such secrets invariably find their way into source code, configuration files, log files, and the like, often in an unencrypted form. While this is typically unintentional, it can also happen deliberately when developers are in a hurry or under pressure to meet a deadline. Compounding the problem is the manner in which source code and associated configuration files are frequently stored: in version control systems, replicated across dozens or even hundreds of developers’ computers, and often on the public internet in places like GitHub. Even if code is kept private, secrets stored in plain text have a way of getting out—perhaps a repository is not scrubbed properly before being made public, an employee’s laptop is compromised, or string literals containing secrets get embedded inside binaries that get distributed.
A recent study [1] found over 100k repositories on GitHub that had sensitive data in them, and that thousands of new, unique secrets are being contributed to GitHub every day. The security engineers at Praetorian have found that the same is true of private customer repositories. We routinely come across all kinds of sensitive information when working with clients. All of this adds up to a security nightmare for companies and their customers alike. Having a tool to detect sensitive information in any form in which it might appear is essential.
At Praetorian, we’ve experimented with many public and proprietary secret scanners, and have found all of them lacking in one or more ways. The techniques these scanners use, which we review below, either fail to find many of the secrets we are interested in, or they produce so many false positives as to be practically unusable. It seemed to us that the problem was ideally suited to a solution using the methods of modern machine learning (ML). Having that expertise in-house, we set out to build a ML-powered secret scanner that wouldn’t suffer from the limitations of the current crop of scanners. This blog post reviews our solution, named Nosey Parker, and our ongoing efforts to make it the best secret scanner available.
Existing approaches
There are many existing tools, both open source and commercial, that automate the task of finding secrets in code. These include truffleHog, git-secrets, gitleaks, sshgit, gitrob, detect-secrets, and GitGuardian, among others. These tools operate by a variety of mechanisms. We review a few of these here before discussing our approach.
Pattern matching
The most common approach to detecting secrets in code is pattern matching with regular expressions (regexes). Regular expressions can be extremely precise in what types of things they match, and pattern matching with them is both fast and powerful. For secret scanning, pattern matching works best when the secrets to be detected follow a very distinct and identifiable pattern. For example, AWS API keys such as AKIAIOSFODNN7EXAMPLE, which start with a known prefix and have a fixed length, can be matched with the pattern (AKIA|AGPA|AIDA|AROA|AIPA|ANPA|ANVA|ASIA)[A-Z0-9]{16}. For any pattern, there is a natural tradeoff between desire to maximize true positives (the real secrets that are found) and the desire to minimize false positives (those matches that are not really secret). One might, for example, choose to include word boundary markers at the beginning or end of a pattern. This will exclude certain classes of false positives, but may result in a loss of true positives as well. Different tools and authors make different choices regarding these tradeoffs. As more and more patterns get added to a scanner, and as the patterns get more complicated, it can be difficult to balance these tradeoffs in a disciplined way.
Pattern matching works less well at finding secrets when there is no identifiable pattern for the given type of secret. User-chosen passwords, for example, can be free-form strings of any length. One might attempt to find them with a pattern like password.?=.* but this will generate a hopelessly large number of false positives (in addition to missing an equally large number of true positives). The best one can do in this situation is to write several overly permissive patterns like the above and then rely heavily on false positive reduction (see below) to eliminate the unwanted matches.
In general, pattern matching is a viable technique for finding secrets in source code, but it requires constant maintenance to keep up with the rapidly evolving world of API keys, tokens, secrets, and credentials. In addition, if one wishes to find as many different kinds of secrets as possible, pattern matching alone is unlikely to get the job done—there simply isn’t a way to write a complete set of patterns precise enough to be usable.
Entropy
Some tools (especially truffleHog and its derivatives) attempt to go beyond regular expression matching by searching for all strings with high entropy. The entropy of a string is a measure of the “effective” number of distinct characters in the string (more specifically, the logarithm of said number).[1] The more distinct characters, and the more uniformly they are represented, the higher the entropy. Alternatively, the entropy of a string can be thought of as a very crude estimate of the “randomness” of the string. Randomly generated strings tend to have higher entropy than natural language ones.
The idea here is that good secrets are generally long and randomly generated, and therefore have high entropy, while ordinary code and text strings tend to have lower entropy. Unfortunately, these are heuristics that are frequently wrong. There are many non-sensitive, high entropy strings that appear in source code, such as SHA-1 hashes identifying Git commits. On the flip-side, not every secret has high entropy. Developers are not immune to using weak passwords like abc123abc123 and then embedding these passwords in code. An entropy based scanner is very unlikely to find these.
In practice (as we will demonstrate below), entropy-based scanners generate far, far too many false positives to be useful without some kind of intelligent filtering. Even with excellent filtering, these scanners will generally miss secrets which are short and/or repetitive.
Filtering
Whatever method of detecting secrets is used, it is inevitable that there will be false positives—strings that look like secrets but aren’t, or at least aren’t sensitive. The more false positives a scanner reports the less useful the tool is. It is therefore not uncommon to add some kind of post-identification filtering to remove as many of these false positives as possible. Some methods of doing this include:
- blacklists of words, phrases, or regex patterns that are unlikely to occur in real secrets (e.g. “EXAMPLE”),
- entropy-based filtering (to remove low entropy candidates),
- machine learning (ML) models trained specifically for this purpose.
Prior work [2] has examined using classical ML techniques (e.g. logistic regression, support vector machines, naive Bayes, or ensembles of such models) to reduce false positives. It is worth noting that a classical ML model for false positive reduction requires handcrafted features to use as inputs. These will typically include things like file names and types, entropy, string length and character set, context words, whether or not the candidate matches one or more patterns, etc. Therefore a classical ML model is simply a more sophisticated way of doing these other kinds of filtering. Finally, we should note that it is not always possible to determine whether or not a given candidate secret is truly sensitive or not, even for a human reviewer. Some number of false positives are expected no matter how sophisticated the secret scanner.
Our multi-phase solution
Unsatisfied with the limitations of regex and entropy-based methods for finding hard-coded secrets, we set out to build a completely ML-powered solution. In order to do this we needed a dataset of source code files together with the locations of the secrets within them. Initially, it made sense to start with an existing regex-based scanner and manually review its findings to determine which ones were really sensitive. Again we found these tools to be deficient and/or difficult to modify to suit our purpose. In the process, however, we realized that we could easily write an improved regex-based scanner custom crafted to suit our purpose.
Nosey Parker
The first tool in our secret scanning arsenal is a best-in-class regex-based scanner, which we’ve named Nosey Parker. Some of its notable features are:
- an extensive and carefully curated list of secret patterns,
- the ability to scan the entire history of a git repository, including blobs not reachable from any commit (unlike many tools, the scanning is done intelligently so that each blob is scanned exactly once, no matter how many commits it is reachable from),
- speed, being up to 100x faster than common alternatives,
- patterns that can match secrets spanning multiple lines (useful for matching PEM-encoded private keys like RSA keys),
- deduplication of findings, so that any given logical secret is presented as a single finding, even if it occurs thousands of times in various forms and files.
In order to evaluate our scanner and to build a dataset for our ML-based approaches we curated a list of roughly 7,300 public repositories from GitHub comprising nearly 16 million distinct blobs (roughly 450 GiB of data) using methods similar to those in [1], and scanned each of them in turn. This generated a set of ~15k findings corresponding to ~200k distinct matches. We then manually (and laboriously!) reviewed each of the findings, classifying each as sensitive or not. The end result was ~12k truly sensitive findings, giving our scanner a precision of about 82% (i.e. more than 4 out of 5 findings reported the regex-only version Nosey Parker were true secrets)!
False positive reduction with deep learning
While 82% is an excellent precision for a secret-scanner we knew we could do much better. Before moving on to a full-blown ML-based scanner, we decided to implement a ML-based denoiser for our regex-based scanner that would learn to discard the “obvious” false positives while retaining the vast majority of the true secrets. Unlike some other ML-based denoisers which are based on static, hand-crafted features, we implemented a deep learning model using state-of-the-art techniques from the field of natural language processing (NLP). While natural language is very different from source code in many aspects, a great deal of recent research has shown that, with some modifications, NLP techniques transfer extremely well to the source code domain. Similar to nearly all current NLP models, ours is a transformer-based architecture pre-trained on a large corpus of source code from a variety of languages.
There are many advantages to using a deep learning model to detect secrets:
- it avoids the need for hand-crafted features which are time consuming to write and maintain, and are rarely universally applicable,
- deep models learn rich representations that are ideally suited to understanding the structure of code,
- deep models can effectively understand the context in which a candidate secret appears and can pick up on subtle clues that indicate an otherwise sensitive looking candidate is really not (e.g. it may be a SHA-1 hash, a placeholder, an example, or an encrypted secret),
- since deep models are often trained in an auto-regressive fashion (i.e. they learn to predict the next token in a stream) they have an excellent sense of whether a given sequence of tokens is predictable or not—an essential skill in detecting secrets (since truly sensitive secrets ought to be difficult or impossible to predict from the surrounding context).
Experimental results for our ML-based denoiser are presented in the following section.
A standalone ML secret scanner
Having a ML enhanced, regex secret scanner is fantastic, but what we really set out to build was a pure ML-based scanner capable of detecting any type of sensitive data in code, not just the variety that match a predefined set of regex patterns. The dataset we built using our custom regex-based scanner has the obvious limitation that the only secrets it contains are those that match the built-in patterns. Models built on such a dataset will only learn to detect secrets matching those patterns. Our solution is two-fold:
- Have a team of cybersecurity engineers manually review the files in our dataset to identify any secrets missed by our regex scanner using any heuristic techniques at their disposal,
- Use the initial dataset to bootstrap an iterative cycle of model building and relabeling: we build a model on the most recent dataset and then manually review the top predictions currently labeled as non-sensitive in order to identify those that are actually sensitive; we then relabel these examples and repeat the process.
At the time of writing, our pure ML-based scanner is very much in a state of development. We have made it through one round of model building and relabeling, and are continuing to iterate and improve the process. The initial results, however, are very encouraging. Some of these are presented in the following section.
Evaluation and discussion
On public repositories
The natural place to begin evaluating our ML-based denoiser is on a portion of the dataset we referred to in the previous section, curated from 7,300 public repositories on GitHub. In keeping with standard ML practices, we partitioned this dataset into three subsets: a training set used to build our model, a validation set used for selecting model hyperparameters, and a testing set used for model evaluation. We report the performance of our model on this test set here.
This test set includes all the candidate secrets found in 553 of the 7,300 repositories by the regex-only version of Nosey Parker—a total of 1404 findings of which 1199 (85.4%) were labeled as actually secret and 205 (14.6%) as not secret. A perfect denoiser would eliminate these 205 false positives while retaining all 1199 real secrets.
Like most ML models, our model is a probabilistic one that assigns a real-valued probability (between 0 and 1) to each candidate secret. This value can be interpreted as the model’s estimate of the probability that the given secret is real. We are free to choose an arbitrary “threshold” between 0 and 1 (say 0.5) and declare every candidate with a score below this threshold as “fake” and eliminate it.
Setting the threshold to 0.5 (a natural choice) in our ML denoiser, we find that the model retains 1169 of the 1199 real secrets while keeping only 24 of the 205 fake secrets. At this threshold, the denoiser has a remarkable precision of 98.0% while still retaining 97.5% of the real secrets found by the regex scanner. By contrast, the scanner without denoising has a precision of “merely” 85.4%.
Rather than picking a fixed threshold, it is useful to evaluate the performance of a model by considering all possible thresholds simultaneously. If, for each possible threshold between 0 and 1, we calculate the true positive rate (the percentage of real secrets retained) and the false positive rate (the percentage of fake secrets retained) we obtain a curve called (for historical reasons) the receiver operator characteristic (ROC) curve. The performance of the model can be measured by calculating the area under this curve (AUC). The greater the AUC the better the model. The AUC can be interpreted as the probability that a randomly chosen positive example will be scored higher than a randomly chosen negative example. A perfect model would have an AUC of 1.0, and a random model (that does no better than chance) would have an AUC of 0.5.
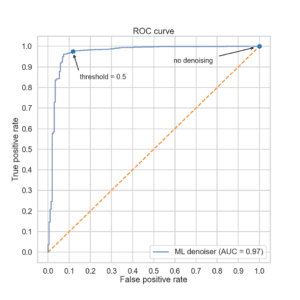
Figure 1: ROC curve for the ML denoiser on the test set
Figure 1 shows the ROC curve for our ML-based denoiser (the dashed orange line, shown for reference, is the ROC curve of a random model). The AUC of our denoiser is 0.97, meaning that the model will score a randomly chosen real secret higher than a randomly chosen fake secret 97% of the time. The extreme flatness of the curve at the top of the graph indicates that our model is capable of eliminating over 50% of the false positives with virtually no loss of real secrets.
On client data
Praetorian’s cybersecurity team recently started experimenting with the ML-enhanced version of Nosey Parker on their client engagements. In one such engagement, a client provided us with over 100 git repositories comprising roughly 80k commits and 3 GiB of data.
We scanned these repositories with Nosey Parker (with and without the ML denoiser) as well as truffleHog3 (a more actively maintained fork of the truffleHog secrets scanner). Client confidentiality prevents us from sharing specific details of this analysis but the summary statistics are given in Table 1.
| Nosey Parker | Nosey Parker
(with ML denoiser) |
truffleHog3
(regex only) |
truffleHog3 (with entropy) |
||
| total findings | 290 | 270 | 266 | 52,749 | |
| true positives | 268 | 266 | 197 | 210 | |
| false positives | 22 | 4 | 69 | 52,539 | |
| precision | 92.4% | 98.5% | 74.1% | 0.4% |
Table 1: Findings summary for Nosey Parker and truffleHog3 on real-world data
Nosey Parker scanned the repositories in their entirety in 4 minutes using a single core of a 6-core MacBook Pro, producing 290 distinct findings. Running the ML denoiser took an additional 6 minutes using all 6 cores.[2] In comparison, truffleHog3 took 44 minutes to scan the same repositories using all 6 cores, producing 266 findings after deduplication. When run with entropy checks enabled, truffleHog3 took 110 minutes to scan and produced 53k findings after deduplication.
To evaluate the quality of the scanners, we manually reviewed the findings from each scanner classifying each as secret (a true positive) or not (a false positive). Due to the large number of findings from the truffleHog3 scanner w/ entropy, we were only able to review a selection of these findings. The results for this scanner are, thus, approximate. The results, given in Table 1 above, show that Nosey Parker found more real secrets than truffleHog3 even when the latter was run with the extremely noisy entropy checker. More notably, it did this while maintaining a significantly higher precision (i.e. the percentage of findings which are real): 92.4% without ML and an impressive 98.5% with ML filtering! In contrast, the extremely low precision (0.4%) of truffleHog3 with entropy checks enabled (its default configuration) renders this scanner practically unusable.
We should note that the ML denoiser did suppress a few real secrets. Inspection of the four suppressed secrets revealed a particular category of secrets that were inconsistently labeled in our training set. We believe that with additional training data and corrected labels, the ML denoiser will very rarely misclassify a real secret.
Although it is still very much a work in progress, we ran our standalone ML scanner on the latest commit of each of these client repositories to see what additional secrets it might uncover. Despite the fact that we only ran it over a small fraction of the contained blobs, the ML scanner found over 2.5x more real secrets than the regex-only scanner: 707 vs 268! Figure 2 shows the result in comparison to truffleHog3. There were 838 findings in all, each of which we manually reviewed as before, giving a respectable precision of 84.4%. We aim to improve this precision with more and better training data. These results validate our assumption that an adequately trained ML scanner will always outperform a pure pattern-based scanner. As we improve our training set and model design, we expect this gap to only grow.
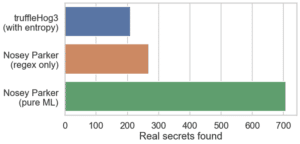
Figure 2: Real Secrets found by Nosey Parker and truffleHog3
Future work
We continue to work on and improve our standalone ML scanner. Many of the improvements to come will be obtained by improving the size and quality of our training set—by adding more, and more diverse, examples of files containing secrets (or non-sensitive strings that look like secrets), as well as by improving the labeling of our existing training set. As our model improves it will find more secrets within the existing training set which we can then add as examples to the next round of training. Besides just improving the training set, there are several improvements we can make to the model itself:
- increasing the number of lines of context we use when evaluating a candidate,
- looking at additional context like file or path names,
- preprocessing files to make them more amenable to scanning,
- increasing the number and types of files we can scan (e.g. various binary formats, PDFs, tarballs, container images, etc.),
- correlating the probabilities of candidate secrets within a file or repository to improve our estimates.
Note that some of these improvements will be applicable to the ML-based denoiser as well. Given the efficacy of the denoiser, another direction for improvement will be to relax some of the patterns in our regex-based scanner in order to capture more secrets, and then to rely on the denoiser to remove the false positives that will invariably come along for the ride.
Conclusion
Secret exposure in source code and configuration files is a pervasive and persistent problem. At Praetorian, we’ve developed Nosey Parker—a machine learning powered, multi-phase solution for detecting secrets in code. This scanner consists of a pure regex pattern matcher, a ML-based denoiser to eliminate false positives, and a powerful, standalone ML scanner not limited by any predefined set of patterns. The experiments discussed above clearly demonstrate the efficacy of this scanner. Even without machine learning, Nosey Parker has a significantly higher signal-to-noise ratio than many popular alternatives. With ML denoising, false positives are all but eliminated. Finally, our standalone ML-powered scanner has demonstrated the potential to find secrets that it is difficult or impossible to write precise patterns for. Such a scanner is essential in a rapidly evolving cybersecurity environment. New types of secrets, tokens, and API keys will proliferate much faster than our ability to write and adapt static patterns to detect them. We will continue to improve the performance and precision of this invaluable scanner.
References
- Meli, M. R. McNiece, and B. Reaves, “How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories,” Network and Distributed System Security Symposium, San Diego, CA, 2019. doi: 10.14722/ndss.2019.23418.
- Saha, T. Denning, V. Srikumar, and S. K. Kasera, “Secrets in Source Code: Reducing False Positives using Machine Learning,” International Conference on Communication Systems Networks (COMSNETS), 2020, pp. 168–175. doi: 10.1109/COMSNETS48256.2020.9027350.
[1] In information theory, one talks about the entropy of probability distributions, not strings. We can think of a string, however, as defining an empirical distribution over the characters of the underlying alphabet with the relative frequency of each character in the string serving as its probability. The entropy of the string is then the entropy of this empirical distribution.
[2] Running the ML denoiser on one or more GPU’s would have been significantly faster than running it on CPU’s. We did not, however, measure this since we were not particularly interested in speed for this experiment.
The post New Chariot Module Nosey Parker Released: An Artificial Intelligence Based Secrets Scanner That Out Sniffs the Competition appeared first on Praetorian.
*** This is a Security Bloggers Network syndicated blog from Blog - Praetorian authored by Nathan Sportsman. Read the original post at: https://www.praetorian.com/blog/nosey-parker-ai-secrets-scanner-release/
