

Generating a Tiny Corpus with Greedy Set Cover Minimization
Generating a Tiny Corpus with Greedy Set Cover Minimization
·
Fuzzing from a starting corpus of test cases is a common practice. For example, in order to fuzz a JSON parser, one can provide a corpus of various JSON files to accelerate the discovery of new interesting test cases. This corpus often consists of both valid and invalid inputs that explore different parts of the program control flow graph. Sometimes two or more test cases, although different in content, can have the exact same execution trace. Therefore, by keeping only one of them in the corpus, the same parts of the program are exercised. At the same time, the fuzzer has less files to go through and execute which saves a significant amount of time. As a result, fuzzing is more efficient and security defects can be discovered more quickly.
Fuzzing tools like AFL, LLVM’s libFuzzer and Honggfuzz provide corpus minimization functionality. Usually a large input corpus is specified and the tool produces a minimized output corpus which contains a subset of the test cases. This subset of files preserves the same coverage on the target program as the large initial corpus. In this article we are going to focus on the minimization algorithm of libFuzzer and then present an alternative minimization algorithm that we contributed to libFuzzer which is part of the LLVM project. This algorithm is able to produce smaller corpora.


The Challenge of Minimization
Before diving into technical stuff, let’s consider the problem of corpus minimization. The desired result is obtaining a significantly smaller corpus, compared to the initial corpus, with the same coverage as the initial corpus. We can think of each test case of a corpus as a file associated with a set of features. The term feature is used in libFuzzer to describe code coverage. For example edge coverage, edge counters, value profiles, indirect caller/callee pairs can all be considered features. To simplify things, we can think of the feature set of a test case as the set of edges that are covered when the target program is run with that particular test case.
When choosing which test cases are going to be included in the minimized corpus, it seems reasonable to prefer test cases with many features and hence large coverage. At the same time other things need to be taken into account too. For example file size and execution time. The target program will probably spend more time in a large file due to IO rather than a small file.
libFuzzer’s Corpus Minimization
The algorithm behind corpus minimization in libFuzzer is very straight forward. A pass over the initial corpus files, gathers unique features for each file; when gathering features for a file, only features that are not yet encountered in other files are added. Then, these files along with their disjoint feature sets are sorted first on their file size and then on their number of unique features. Finally, another pass is performed over the sorted corpus. In this pass, a test case is included in the minimized corpus only if it adds new features.
def minimize(initial_corpus) -> List[Testcase]:
minimized_corpus = [ ]
all_features = [ ]
sort(initial_corpus, key=(file.size, file.features.size()))
for file in initial_corpus:
if not file.features.subset_of(all_features):
minimized_corpus += file
all_features += file.features
return minimized_corpus
Due to the ordering mentioned earlier, smaller files are preferred for the minimized corpus and among files with the same size, the file with the largest number of unique features is selected. It is easy to see that the minimized corpus covers exactly the same features as the initial corpus.
Set Cover Minimization
The problem of corpus minimization can be reduced without much effort to a known problem in computer science. It’s called the set cover problem. The problem statement is the following:
given a set U (the universe) and a collection S of subsets of U, what is the smallest sub-collection of S whose union equals U
We can reduce corpus minimization to this problem if we consider the universe U as the union of the features of all the files in the initial corpus. Then, each element of S is a feature set of a corpus file. Clearly their union equals U. With that in mind, the solution to the set cover problem is the smallest set of files that covers all the features!
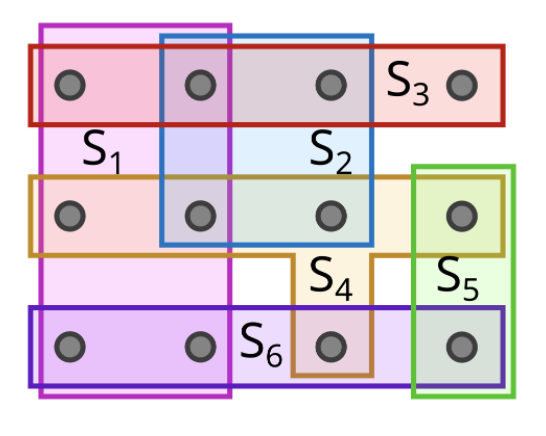
For example, in the above figure, each dot represents a feature (e.g. an edge of the control flow graph). Each colored region S is an execution path that corresponds to a single test case file from the initial corpus. The set of all dots is the set of all the features in the initial corpus. A candidate solution would be {S3, S4, S6} because it covers all the dots.
Unfortunately, the above problem is NP-Complete, which means that there is no polynomial time algorithm that solves it. In our setting, the corpus can contain from hundreds to a few million of test cases, each having hundreds of features. Therefore, our next best option is an approximation algorithm that will find a sub-optimal solution (the size of the approximate minimized corpus will be larger than the size of the optimal minimized corpus). Luckily, there is a very famous greedy approximation algorithm for set cover which also guarantees that the approximate solution is at most ln(Opt) times larger than the optimal solution Opt. This approximation ratio seemed very promising, compared to libFuzzer’s algorithm on which we have no guarantees on the quality of the solution.
The algorithm itself, although a bit more complex than the single-pass algorithm described earlier, is very intuitive. A set of covered features is maintained, initially empty. At each iteration we select the test case that covers the most features that are not yet covered. Of course, when two files have the same number of previously uncovered features, the smaller one is picked. The algorithm terminates when all features are covered.
def set_cover_minimize(initial_corpus) -> List[Testcase]:
covered = { }
minimized_corpus = [ ]
while covered != all_features:
file = file_with_most_uncovered_features(initial_corpus)
covered += file.features
minimized_corpus += file
initial_corpus -= file
return minimized_corpus
An optimization that improves the run time of minimization is the use of a bit vector to implement the covered set containing the already covered edges instead of std::set. Features are represented by simple 32-bit integers within libFuzzer. In fact, libFuzzer uses a 26KB (2^21 bits) bit-vector to track edge coverage during fuzzing. The same idea is used for minimization in order to speed things up. A feature with value f is covered if covered[f % covered.size] is set to 1. But what about collisions?
Collisions are ignored. This means that the minimized corpus may not cover some features that the initial corpus had. For example, if the initial corpus contains the features 0 and 2^21 in two different files, then it is possible that 2^21 will be falsely considered covered and the associated file will not get picked. This is very rare though in reality.
Comparing Results
The set cover implementation of corpus minimization can be used with the -set_cover_merge=1 flag, which is similar to the existing -merge=1 flag that libFuzzer uses for minimizing and merging multiple corpora into one. We compared the two different algorithms for several targets:
- JQ: we’ve seen a harness of this target in a previous blog post. Here we get some really interesting results.
- rapidjson: another json parsing library.
- sqlite: This target is harnessed in the fuzzer-test-suite repository.
First lets see how we can obtain the minimized corpus with the standard libFuzzer minimization. You can also experiment with the docker image of the testing environment containing the initial corpus and the libFuzzer target.
root@da1a2c981a4d:/src/harness# ls initial-corpus/ | wc -l
101633
root@dd166043164c:/src/harness# mkdir minimized-corpus
root@dd166043164c:/src/harness# ./fuzzer_jq -merge=1 minimized-corpus initial-corpus
...
MERGE-OUTER: the control file has 5419469 bytes
MERGE-OUTER: consumed 8Mb (80Mb rss) to parse the control file
MERGE-OUTER: 679 new files with 6683 new features added;
...
root@dd166043164c:/src/harness# find minimized-corpus -ls | awk '{sum += $7; n++;} END {print sum/n;}'
922.415
root@dd166043164c:/src/harness# du -sh minimized-corpus
3.0M minimized-corpus
Initially, the corpus has a little over 100,000 test cases (line 1). An empty corpus is created (line 3) and the fuzzer is run with the -merge=1 flag, in order to minimize initial-corpus into minimized-corpus. The lines starting with MERGE-OUTER are libFuzzer output. Line 8 computes the average file size (in bytes) in the minimized corpus and line 10 computes the total size of the minimized corpus. By repeating the same workflow with the -set_cover_merge=1 flag, we can compare the two minimization techniques.
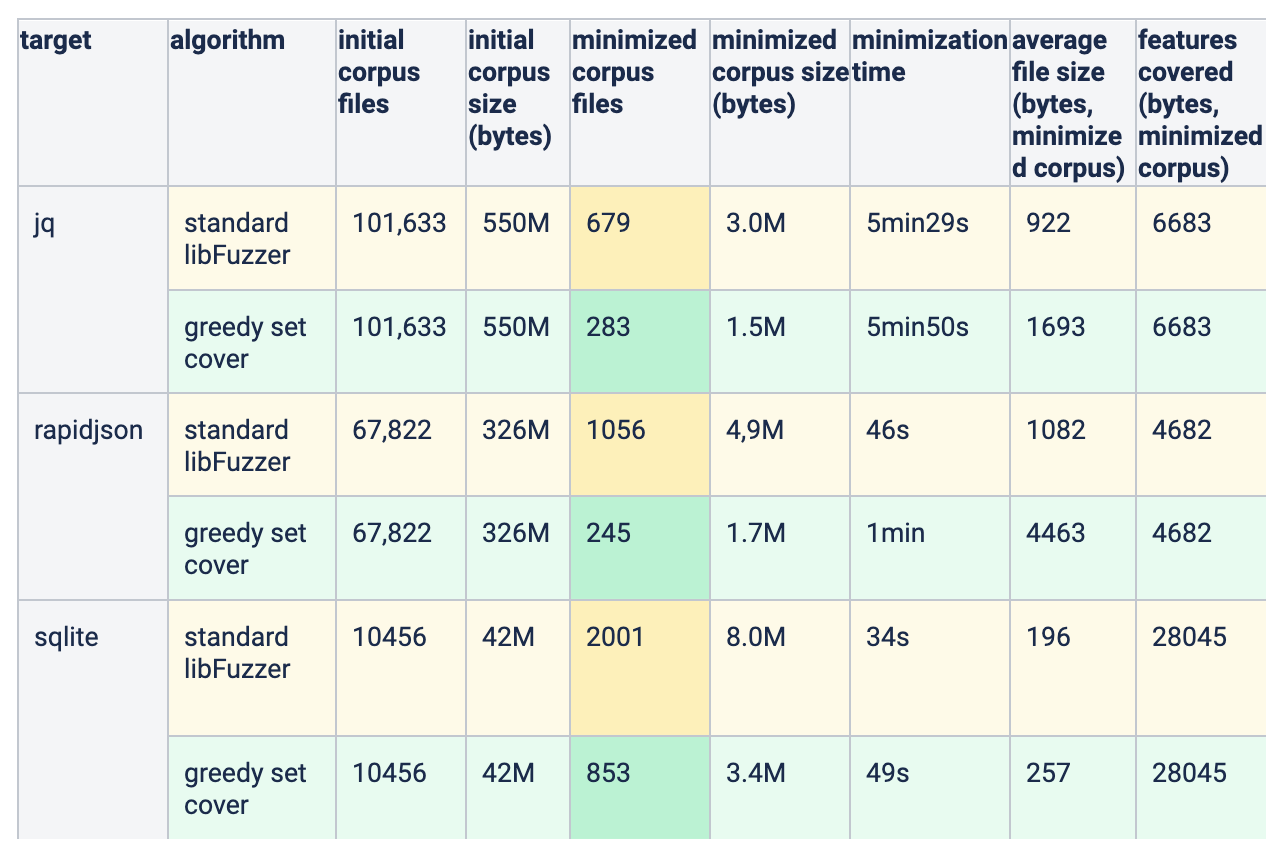
Focusing on the JQ target, the main result is the fact that the minimized corpus using the greedy set cover approach contains significantly less files, roughly 60% less. Of course the trade-off here is the execution time. From 5min29s, the time increased to 5min50s, a rather small change which is worth the dramatic decrease in corpus size. Another interesting result is the comparison on the average file size in the minimized corpus. Because the standard libFuzzer minimization prefers smaller files, it is expected that the average test case size is going to be small. Indeed, for greedy set cover the average size is 1.8 times larger. At a first glance this seems worrying because larger file size means more bytes for the target to read and therefore slow fuzzing. But looking at the total size of the minimized corpus we see that it is approximately 50% smaller in bytes, since it contains far less files.
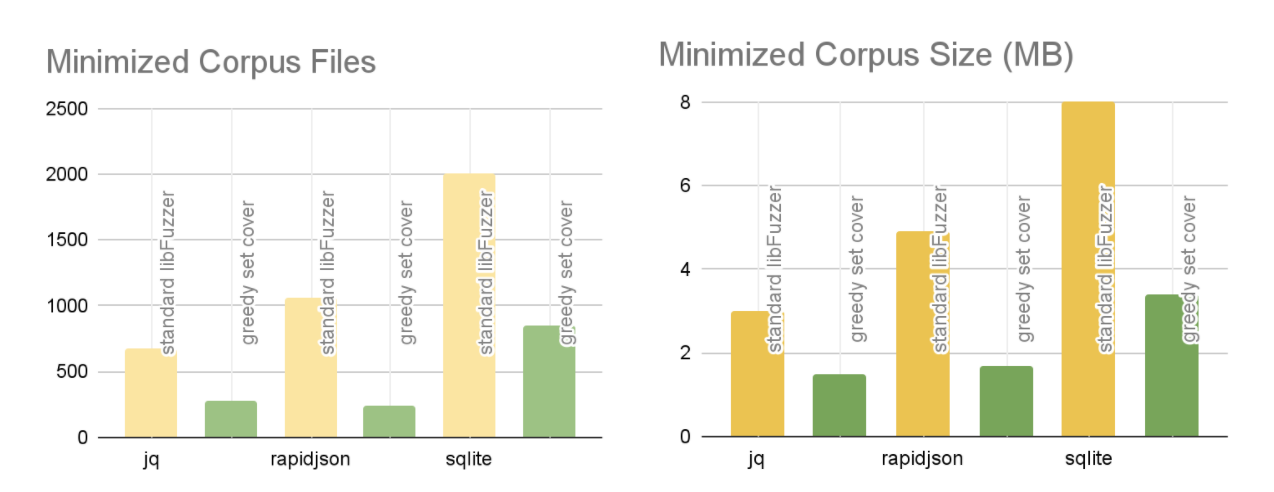
Looking at the rapidjson target the difference in the minimized corpus quality is more pronounced. The corpus has 4 times less files and the total size is 3 times smaller. It is important that the number of features in the minimized corpus remains the same across the two implementations. This shows that using the bit-vector optimization doesn’t have a negative impact on coverage for real-world targets and corpora.
We also see similar results for sqlite. This target was given a relatively small starting corpus of approximately 10,000 test cases.
Takeaways
This effort to improve corpus minimization for fuzzing shows that approximation algorithms can be really useful in solving certain hard combinatorial problems. The quality of the solution is much better and also there is a theoretical upper limit for the size of the minimized corpus, unlike a simple forward pass algorithm. Furthermore, we see that even though the proposed algorithm is not time efficient in terms of complexity (not linear), in practice it performs quite well if we apply simple optimizations (bit-vector) to the underlying implementation.
It would be interesting to see more people using this kind of minimization to fuzz their target applications. This would highlight what the effect of better minimization is during fuzzing. Set cover merge is now part of LLVM’s libFuzzer after contributing this work.
Stay Connected
Subscribe to Updates
By submitting this form, you agree to our
Terms of Use
and acknowledge our
Privacy Statement.
*** This is a Security Bloggers Network syndicated blog from Latest blog posts authored by Aristotelis Koutsouridis. Read the original post at: https://forallsecure.com/blog/efficient-corpus-minimization
