The Kubernetes Network Security Effect
I’m a firm believer that network security must be a layer in an overall security strategy. As cloud evolves, it’s hard not to notice the
network security challenges in this domain.
TL;DR: Kubernetes (K8s) has a built-in object (sort of) for managing network security (NetworkPolicy). While it allows the user to define the relationship between pods with ingress and egress policies, it’s still quite basic and requires very precise IP mapping for a solution that’s constantly changing, so most users I’ve talked to are not using it.
Users need a simplified solution that protects their K8s networks – a solution that makes network security in K8s achievable with the highest security levels possible: mutual TLS between microservices and real zero-trust deployment. And no, not a sidecar solution.
Still Stuck Behind a Firewall?
Back in the day, a network security policy was defined with IP addresses and subnets. You would define the source and destination, then the destination port, action and track options. Over the years, the firewall evolved and became application-aware with added capabilities for advanced malware prevention and more. It is no longer a firewall, but a full network security solution.
However, most network security solutions, even today, use IP addresses and ranges as the source and destination. This was the first challenge when these devices moved to the cloud. How can you define source/destination IP in such a rapidly changing environment? In the cloud, IP addresses change all the time: one minute, an IP is assigned to a database workload and the next minute it is assigned to the web workload. In addition, if you want to understand the cloud and see the connections prior to network address translation, you must be inside the application – in K8s, in most cases, when a pod connects to an external resource, it goes through network address translation; meaning that the destination sees the source IP as the worker node address and not the pod.




For infrastructure-as-a-service (IaaS) cloud deployments, most companies can solve this challenge by installing their network security solution with a proxy on a virtual machine (VM). But when it comes to Kubernetes – it is just not working. Why not? There are a few major reasons:
- A normal pod in K8s is just a few megabytes – in other words, you cannot deploy a full network security solution in a pod. Placing it outside of K8s solves the north-south (traffic in and out of the network) hygiene issue, to some extent, but not the east-west (traffic within the network and in-cluster connectivity) issue.
- K8s is the cloud on steroids – pods scale up and down rapidly. IP assignments change, and the rules cannot be bound to IP addresses and subnets.
- A full network security solution is not required. For example, there is no requirement to do deep packet inspection inside K8s. Most companies are looking for east-west micro-segmentation – basically, firewalling.
Lucky for us, K8s was created with the NetworkPolicy object. This object treats each pod as a permitter on its own, and you can define ingress policy and egress policy. Both policies can leverage IP addresses, subnets (CIDR) and labels. Unfortunately, K8s does not support fully qualified domain name (FQDN) in native security policy. This means that it’s impossible to create a policy that limits the access to S3 or Twitter (for example).
Network security is enforced by the network layer (note: this topic is not in the scope of this blog), the most common of which are Calico, Flannel and Cilium. By design, the K8s network is flat. One microservice from one namespace can connect to another microservice, even if it is in another namespace.
Struggling to Build a K8s Network Policy That Works
Logically, you would expect users to use network policies, but most are not.
Creating a network policy is an iterative task:
- Map communication between different elements, the resources that access the application, the resources the application connects to, the ports and the protocols.
- Create a policy.
- Run the application and monitor to see if everything works.
- Find and fix the issues you missed.
- Repeat every time your network or an application changes.
The catch is that, in K8s, your application, which is composed of pods (microservices), can change on a daily basis! And there’s no way you can really keep up with the pace of your development team – updating the network policy every single time they push changes to an application.
Imagine you map all the communication patterns, create a network policy accordingly and everything works. A few hours later, a developer pushes a new version of a microservice that uses an API from a different pod. This stops communication with the existing pod and with an external website. Since you forgot to update the network policy, your new microservice stops working. You cannot debug what is wrong because there are no network logs in K8s. Not only that, but even if you do succeed in fixing the issue, you might still prefer to keep the old policy that allows the new pod to communicate with the pod it stopped communicating with – making the network policy incorrect and missing the micro-segmentation goals.
Finally, K8s does not have a built-in capability for visualizing network traffic, so if you break a connection between two microservices – good luck debugging it!
K8s network policy is configured by allowing rather than blocking. This means that if you want to block individual objects from a specific destination – you need to choose a different solution.
The most annoying part is that the K8s network policy is set in such a way that if pod A and B need to communicate, you need to define egress traffic for pod A and ingress traffic for pod B. This is prone to errors, and is incredibly challenging to debug.

Figure 1: Network Policy
In the above example, you’ll see a native K8s policy for a pod which is labeled “C.” The policy configures the objects so that pod C:
- Connects to pod A on port 443 and 80
- Initializes traffic to pod “B” on port 443 and 80
- Initializes traffic to 10.128.0.1/24
Most organizations just do north-south network security (outside of the cluster) and pray that nothing will break this security control.
By design, K8s security also suffers from the following issues:
- The identity problem – if pod A, with two containers, connects to pod B, pod B sees the incoming connection from pod A; however, it does not know which container created the connection. This means there is no way to implement security guardrails granularly enough at the pod level. As a result, if malicious software is running in my pod, it will be able to communicate with other pods.
- Clear connections – all the connections in K8s are based on the application’s/developer’s programming. Meaning that if the app uses protocols that aren’t encrypted, an attacker can intercept and decode the communication (as of today, most in-cluster communication is not encrypted).
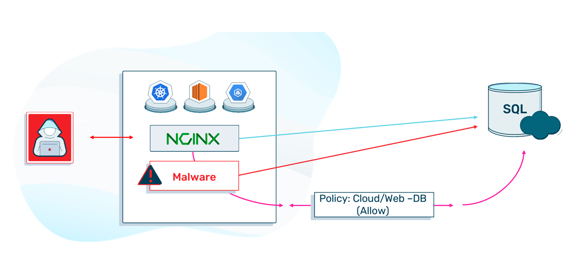
This figure demonstrates the intention versus the actual flow. The network administrator set the policy to allow web-to-database connections. His intent was to allow NGNIX, running in the web pod, to communicate with the SQL server. However, this also means that malware running in one of the web pods can communicate with the SQL server.
Service Mesh to the Rescue
A service mesh is one way to control how different parts of an application share data with one another. Unlike other systems for managing this communication, a service mesh is a dedicated infrastructure layer built right into an application. This visible infrastructure layer can document how well (or how poorly) different parts of an application interact, so it becomes easier to optimize communication and avoid downtime as an app grows.
Istio is, arguably the most popular open source service mesh solution available today, so we’ll use it in this example. To overcome the design issues we’ve discussed so far, Istio adds a sidecar container to identify individual workloads, and moves the east-west traffic to mTLS. Now, if pod A connects to pod B, pods A and B will communicate by first authenticating their certificates. Malicious attackers will have no way to intercept and decode the traffic.
This is great! But the fact is, most organizations are still not using Istio, or any service mesh, either! In fact, the last CNCF report from late 2020 indicates that only 30% of K8s users are using a service mesh (Istio or otherwise). This is probably because service mesh is very complex, and introduces performance penalties and latency.
Not only that, but it suffers from the same identity problem as described above; meaning that if a malicious actor enters pod A and creates a connection to pod B, it will still be allowed access, as long as the service mesh policy allows it.
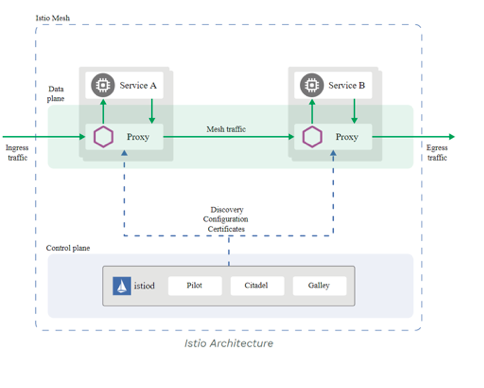
Figure 2: Istio 1.9
In the above diagram, each pod has an Envoy – a proxy that secures the communication from the original container by using a mutual TLS tunnel. The proxy (Envoy) does not care about the identity of the container. It can be a malicious container that communicates with other services and is awarded the identity that Istio/Envoy provides.
K8s Network Security Best Practices
While the challenges described above may seem daunting, there is still much that can be done. A K8s network security solution should follow these guidelines:
- Enforce zero-trust – Each microservice acts as its own permitter; as such, it is recommended that you follow the zero-trust model: do not trust and always verify! Each request must be authenticated and authorized before access is approved.
- Upgrade to Mutual TLS – Use mutual TLS to encrypt the communication between the different microservices. This will assure that even if an attacker is present on the host, he cannot intercept and decode the traffic.
- Provide network visibility – you cannot really protect something that you cannot see. Visibility is the key for understanding the communication patterns, not only of what is working, but also of what is not working, what gets dropped, etc.
- Apply robust policy to meet rapid changes – When it comes to policy language, use a language that handles the constant changes in microservices. In most cases, the change will be inside of the cluster. This means once you set the ingress/egress traffic to/from the cluster, most of the changes will happen in the communication between the microservices.