

A case against automatic query rewriting for Data Cloud Security
Companies that are investing in Data Cloud, are often very concerned about preventing malicious access to their databases. Some common concerns we hear are:
- “I’m worried about full table scans of my databases with customer information.”
- “I’m worried about rogue applications masquerading as ETL jobs to read sensitive data.”
- “I’m worried about my data analysts in North America accidentally accessing driver’s licenses in Europe.”
To protect themselves from this threat, organizations (including our own!) are taking several approaches. In this blog post, we evaluate the technical merits of a tempting one – that of automatic query rewriting.
Why databases automatically rewrite queries
Let’s say we have a set of tables containing a large amount of data. If we have to compute a join between these tables, the computation would be very expensive and time-consuming, and it could take minutes or even hours to execute. A common approach used to optimize query processing is the use of automatic query rewriting.
The idea behind query rewriting for optimization is to automatically transform it into a different query, producing the same results but executing with better performance. Let’s have a look at an example where we have a company, with more than 20 years of history, and we want to list all the orders from 2020 and their respective customers. The query would require a join between the orders table and the customers table, as can be seen below.
| Original query |
| SELECT * FROM customers c JOIN orders o ON c.cust_id = o.cust_id WHERE o.order_dt > ‘01/01/2020’; |
| Rewritten query |
| SELECT * FROM customers c JOIN (SELECT * FROM orders WHERE order_dt > ‘01/01/2020’) o ON c.cust_id = o.cust_id; |
Since the orders table contains data from the last 20 years, the original query would end up being slow. In order to optimize the query, databases transparently rewrite it, now joining only a subset of the orders table (only orders from 2020) with the customers table, which results in an execution time considerably shorter than the one for the original query. This approach uses predicate pushdown to rewrite the query.
Another approach for rewriting queries to optimize performance is the use of materialized views. Let’s say that now, we want to list only the active orders from 2020. A query to perform this task would be similar to the previous one, just adding another filter to only select orders where order_status = ‘active’. As the previous one, this query can end up being quite slow. A way to optimize it is to create a materialized view for the active orders. This means that we will create a new database object and store all the active orders. Now, when we try to execute the query, the database will automatically rewrite the query to select the users from the materialized view, instead of performing a join between the orders and customers tables.
| Materialized view |
| CREATE MATERIALIZED VIEW active_orders AS SELECT * FROM customers c JOIN orders o ON c.cust_id = o.cust_id WHERE o.order_status = ‘active’; |
| Original query |
| SELECT * FROM customers c JOIN orders o ON c.cust_id = o.cust_id WHERE o.order_dt > ‘01/01/2020’ AND o.order_status = ‘active’; |
| Rewritten query |
| SELECT * FROM active_orders WHERE o.order_dt > ‘01/01/2020’; |
Both approaches we showed use a rule-based strategy to transform the query. In brief, this strategy applies rules to change the query when a certain pattern is identified. Other strategies can be used for query rewriting, such as a cost-based approach that applies rules to the query considering the costs involved (based on statistics of the tables being queried) or a machine-learning based strategy that takes into account the historical performance of similar queries to learn rules that can help optimize the current query. For more information about the different query rewrite strategies, please take a look at this other post.
Rewriting queries outside the database
When we talk about automatic query rewriting, we usually think about the database transparently rewriting complex queries to optimize performance, as we showed in the examples above. However, it is also possible to perform such transformations outside the database, and it’s possible to use these transformations for more than just performance.
One possibility is the use of automatic query rewriting for differential privacy. The idea of differential privacy is to minimize the chances of revealing the private information of an individual in the results of a specific query, while allowing general statistical analysis of the data. For that, a query is rewritten in order to add some “noise” to the result, based on the overall data, such that it is not possible to identify the information for a specific individual.
As an example, we can go back to the data from the company we used in the previous examples. Let’s say we want to get the age of their employees. In a regular query, we would be able to get, for each employee, its age, represented as an integer. However, if we apply a differential privacy algorithm to the query, it might be rewritten in such a way that, instead of returning the proper age, it will return the age cohort, represented by an array of integers. That way, we will not be able to identify, for each employee, the exact age, only its range.
SELECT name, age FROM employees;
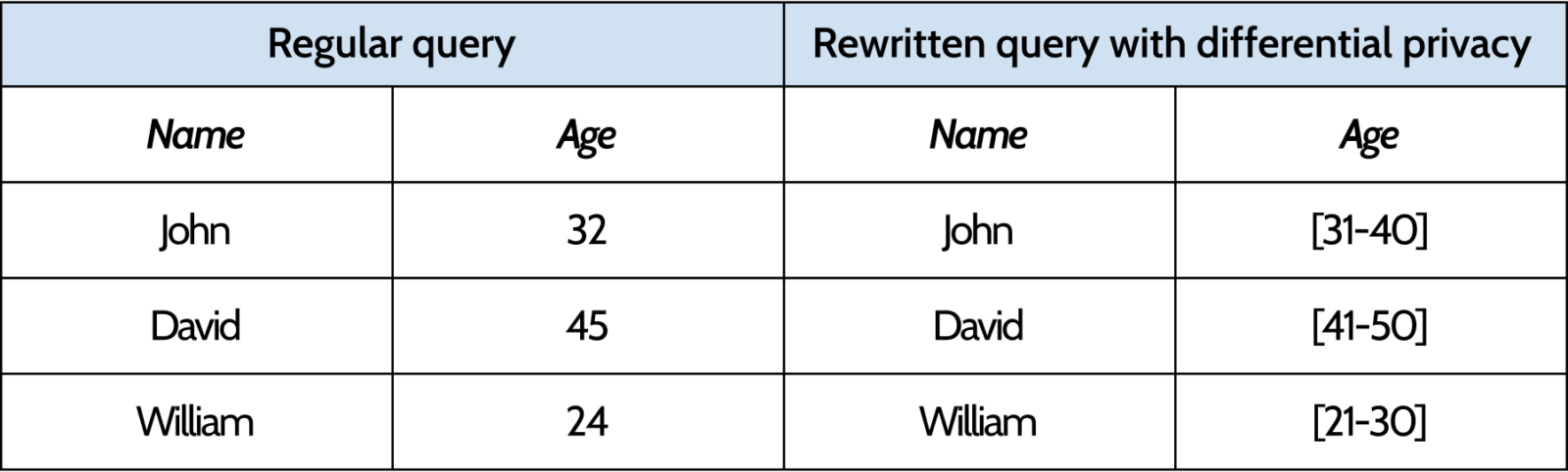
If we imagine that we have an application that ingest this data, this can be a problem. The application considers that the result of the query will be an integer. If instead, it returns a range, the application might break. This means that it is extremely important that any change to the query (and its response) be in sync with the database.
Applying differential privacy using automatic query rewriting can be useful when done correctly. However, it must be done very carefully. Otherwise, it may present serious problems, like in the previous example, that the query would be successfully executed but the application ingesting it would not handle the results as expected. It is also possible that the rewrite of a query will fail in the database. Let’s assume that we need to get the monthly salary of each employee of our company. To do this, we would need a simple query:
SELECT annual_salary/12 as monthly_salary FROM employees;The modification of the query, from a privacy perspective, would break it. That would happen because, as in the previous example, the annual salary would not be represented by an integer, but by a range representing the salary. So, when dividing this range by 12 to get the monthly salary, the query would break directly in the database. Any application using this would require proper error handling, yet it wouldn’t be clear why the query failed. Therefore, debugging this could end up being very difficult and time consuming.
Risks and challenges with this approach
Automatic query rewriting from outside the database is hard to do correctly. This approach can present different points of failure, as shown in the examples above, that might have major impacts in the applications using it.
Automatic query rewriting for differential privacy can, for example, make a valid query become incorrect. In our example for retrieving the monthly salary of all employees, a valid and simple query could end up being incorrect and failing to execute. Another risk, already mentioned, is the possibility of crashing the application when we apply automatic query rewriting for differential privacy. When something like this happens, it can be very difficult to debug and find the root cause of the problem, which might cause even more damage to the application and its maintainers.
Despite the issues and risks we’ve listed above, many organizations have successfully used automatic query rewriting to provide differential privacy. However, when we try to extend the use of query rewriting to achieve more general security goals, trouble can arise, as we’ll explore below.
Limitations of query rewriting for data security
Application security (AppSec) is one area where automatic query rewriting can be a poor fit. Let’s say we want to automatically rewrite a query based on the identity of a user, allowing him to only see his “own data”. This presents two problems: First, we’re allowing the application to send insecure queries and waiting for the rewrite system to intervene. Second, if any part of the application needs content that is not directly related to the user, such as seeing aggregate data, the query rewrite would effectively block the application from doing its actual work.
Finally, query rewriting fails to address vulnerabilities in the application itself. For example, even with the above query rewrite measure in place, if an adversary can gain access to multiple accounts, they would be able to exfiltrate data on a per-user basis.
Another limitation of using automatic query rewriting for security purposes is that it is not able to avoid insider threats. If, for example, we have a data analyst who requires access to several different data sources, an identity-based rewrite system would block him from doing his work. On the other hand, not applying the modifications to his queries would allow him to exfiltrate whatever data he wants.
When it is okay to do query rewriting outside the database
Although automatic query rewriting presents several risks and limitations, there are different situations in which query rewriting can be used successfully. Prominent among these is its use for optimization, where it’s proven very effective and has been used by databases for several years.
Query rewriting can also be successfully used for cardinality restriction or data segmentation, for example. A query can be rewritten in such a way that it limits what the user can see. Let’s say our company is located in the US and in Europe. We want users located in the US to be able to see only US-based orders and customers. If one of those users run a query such as:
SELECT * FROM customers;We would automatically rewrite that query would to ensure that the user will only see customers located in the US:
SELECT * FROM (SELECT * FROM customers WHERE country='US');It is important to notice that query modifications such as this one should be triggered manually and not automatically, since the latter can present the risks and challenges previously discussed, while, when triggered manually, the problems can be avoided, achieving the expected result.
Now what?
Automation is important for security to work and scale, but query rewriting is the wrong place to apply it, given the risk of breaking query correctness and the difficulty of troubleshooting. Companies seeking to protect their databases should invest in a Zero Trust architecture to prevent malicious access in the first place, and real time activity monitoring to make sure they get notified if something bad does happen. Contact us if you want to learn more about how Cyral can help you accomplish these goals.
The post A case against automatic query rewriting for Data Cloud Security appeared first on Cyral.
*** This is a Security Bloggers Network syndicated blog from Blog – Cyral authored by Pedro Las-Casas. Read the original post at: https://cyral.com/blog/case-against-automatic-query-rewriting/
