

Attribute Based Access Control in Databases
Introduction
Databases are one of the most security-sensitive components of the modern day information infrastructure of any organization. This is because they are the custodians of the most crucial asset of any organization―data. Every database needs flexible access control mechanisms to prevent unauthorized access to data and unauthorized changes to data. Doing this requires a) authenticating users (most commonly implemented using passwords), and b) authorizing each data access attempt.
While the commonly available approaches for user authentication in databases are less than ideal, and data breaches are often the result of abuse of privileged credentials, this post focuses on the authorization problem. The authorization problem can be simply stated thus: “given the (verified) identity of a user and the operation that the user is trying to perform, should the operation be permitted?” For example, should Joe be permitted to access employee salary records (perhaps yes if Joe works on the accounting or compensation team, but no if he’s in any other department)? Access Control Policies implemented by a database system allow a database administrator to specify the answer to precisely this type of question, and enforce these rules at the database level.
Access Control Policies in Databases
Access control policies, in general, are based on the notions on subjects, objects, operations, and privileges. A subject is an actor that is trying to perform an action on an object. An object is a resource that needs to be protected from unauthorized use. An operation is any action a subject might carry out on an object, and different operations may be relevant on different kinds of objects. A privilege is the permission for a user to perform a certain operation on a specified object.
In the context of databases, subjects can be users or applications. Resources can be of different types and with varying granularity such as databases, tables, columns, and so on. In the context of these resources, the relevant operations correspond to familiar database actions such as create, modify, update, and read. In addition, databases often support administrative actions such as shutting down or backing up the database.
Many databases started out by supporting the specification of privileges on a per user basis—this is similar to the idea of access control lists.

For example, if Joe does indeed work in the accounting department, he would need to be given permission to access the database table containing employee salary records. Similarly Fred, a developer, may be given access to test databases but no access to production ones.
Maintaining the access control lists on a per-user basis quickly grows unmanageable for more than a handful of users. This is where Role Based Access Control (RBAC) comes in. Simply defined, a role is just a collection of privileges. Now, instead of defining privileges for each individual user, a few roles can be defined, and users can be assigned to roles. This is useful because, in practice, users can be classified into groups (based on their functional roles in the organization) with similar data access requirements for all users in a group.

Many databases also allow users to be given multiple roles, and an active role can be assumed in any given database connection. Some databases allow hierarchical definitions of roles as well, where a one role can inherit all privileges from one or more other roles, and these inherited privileges are added to the privileges explicitly granted to that role.
As an example, roles corresponding to developers, accounts personnel, HR personnel, data analysts, and so on, may be defined with appropriate privileges granted to each such role. Users can then be granted one or more roles.
Why is RBAC not Enough?
While role based access control policies can specify data access policies to a reasonably granular level, it becomes very difficult to maintain these policies. Here are some difficulties in managing RBAC policies:
- The data of most organizations is held in multiple databases—on-prem and in cloud, of different types such as relational, noSQL, and data warehouses, each with its own flavor of access control policies.
- New applications are added and existing ones change all the time—leading to newer resources being created in databases all the time. It is very hard to ensure that the right policies are in place at all times.
- Databases do not support Security as Code — this makes it impossible to incorporate access control policies into deployment (CI/CD) pipelines.
- Fundamentally, an access control policy implemented with only a database’s native controls must make its decisions based on static information (primarily the user’s identity and the type of resource being accessed). This is insufficient in today’s world of Data Cloud and web workers, where perimeter security can no longer protect corporate resources. In this scenario, stolen or compromised user credentials can lead to massive data loss. To ensure data security in such an environment, it’s important to adopt the principles of the Zero Trust Architecture.
Attribute Based Access Control
In accordance with zero trust principles, Attribute Based Access Control (ABAC) uses various dynamic attributes to make policy decisions.
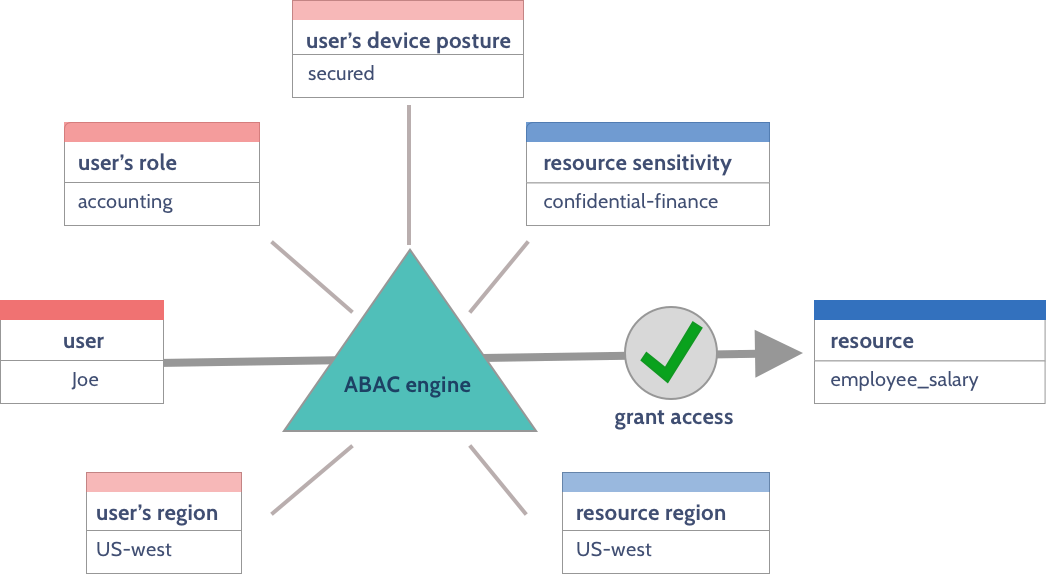
These attributes need not be limited to the user’s identity/role and database resource names. They can also include some or all of the following:
- User’s organizational groups, organizational unit, and other user data
- IP address and geographic location where the request originated
- Attributes of the requesting device (for example, whether the device is corporate-issued or user-owned device, and what is its current device security posture)
- (Dynamically determined) sensitivity of the data being accessed (for example, data that resembles email addresses, phone numbers, or credit card numbers would be considered to be highly sensitive)
- Past user behavior
Note that most of the attributes listed above go beyond the information available within the database itself. Specifically, this approach requires the data access layer to use federated authentication to integrate with the larger user- and device-management architecture of the organization, rather than relying solely on information residing within the database.
While challenging to implement, attribute based access control can potentially address use cases and security challenges that can’t be solved using the traditional RBAC based approach. Here are a few examples of attribute based policies:
- Personally Identifiable Information (PII) of employees can only be accessed by employees in the HR department using corporate devices with the latest security patches applied.
- Users who belong to the user group called analysts can access all data in a read-only mode but with sensitive data redacted.
- Reauthentication with an additional factor should be triggered when an attempt is made to access specific highly sensitive data.
- A trickle infiltration attempt should be flagged if a user is seen steadily accessing sensitive data (that he is otherwise authorized to access) in small chunks over a period of time.
Conclusions
The traditional ACL and RBAC based approaches to access control are insufficient to secure the all important data cloud in today’s scenario because:
- the number and variety of databases in use by the organization is increasing quickly; and
- most new databases are hosted in the cloud, but security teams need to apply policies consistently across on-prem and cloud databases.
Attribute access control brings the benefits of the zero trust architecture to the data cloud and integrates it with the organization’s overall security strategy in a holistic fashion. Using attribute based access control, teams can enforce access policies uniformly across a number of data stores and minimize the risks associated with shared credentials, stolen credentials, and insider attacks.
The post Attribute Based Access Control in Databases appeared first on Cyral.
*** This is a Security Bloggers Network syndicated blog from Blog – Cyral authored by Deepak Gupta. Read the original post at: https://cyral.com/blog/attribute-based-access-control-in-databases/
