

Avoid Alert Fatigue: Web Application Firewall Installation, Configuration and Best Practices
Alert fatigue – introducing false positives in WAF
All WAF experts know what it’s like handling massive amounts of alerts. They’re also very likely wasting a lot of time fishing false positives out of all these alerts. The WAF’s purpose is to block attacks and let legitimate traffic through. False positive events clutter the alerts feed and – worse – block legitimate traffic.
Some false positive events are caused by bugs or a bad practice used in your application. Other events can happen because of a WAF rule that’s either too generic or doesn’t suit the way your site works.
For example, sending a JavaScript code in an HTTP request parameter looks suspicious. It’ll probably be detected by a JavaScript-related WAF rule like cross-site scripting. Yet, a JavaScript code in an HTTP parameter might be perfectly legitimate in a JavaScript teaching site.
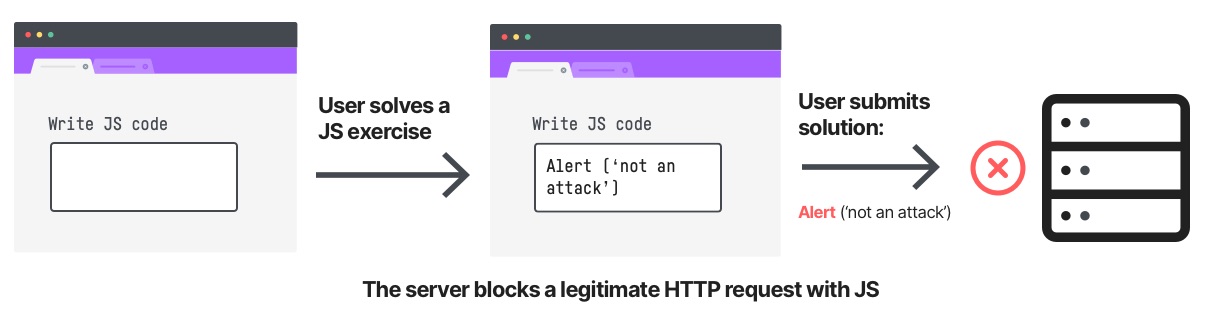
One way of eliminating these false positives is a tiresome tweaking of the WAF rules – sometimes even disabling some of your security rules and risking your servers. The trade-off here is clear – the tightest security means blocking 100% of your traffic. This is obviously a bad solution, so something else is required.
This post describes a new approach, investigated by Imperva’s research team. It shows another way to tackle this problem, using more advanced techniques that can significantly reduce the man hours invested in the process.
New Approach to Avoid WAF False Positives and Misconfiguration
Cyber Security Attack Analytics
Attack Analytics is an Imperva solution, aimed at crushing the maddening pace of alerts received by security teams. Attack Analytics condenses thousands upon thousands of alerts into a handful of relevant, investigable incidents which give a new context to the WAF alerts. WAF alerts normally have data relating to a single HTTP request such as source IP, target URL, HTTP parameters and so on. An Attack Analytics incident has some extra context about the attack, however, such as:
- How many sources participated in the attack
- All the URLs targeted by these sources
- The different client tools used in the attack (browsers, bots, etc.…)
Looking at attacks in the context of a complete security incident, and not only a single request or a session, helps us solve the false positive issue.
False Positives in Cyber Security Attack Analytics
Let’s go back to the false positive example above. Consider a site that teaches JavaScript. In one of the exercises on the site, the end user is given a task – write a JavaScript code that prints a message in a pop-up window. The URL in this exercise sends the JavaScript written by the end user in an HTTP request parameter. Since this is the way the site functions, many end users will use that URL and send JavaScript to the application.
But, although the JavaScript looks suspicious and might trigger a WAF rule, this JavaScript is legitimate and produces a false positive alert. So what will an Attack Analytics incident of this false positive alert look like?
This ‘attack’ has these attributes:
- Many source IPs, as many of the site’s users that do this exercise
- It targets a single HTTP parameter in a specific URL
- All source IPs use a browser
Detecting False Positives in Cyber Security Attack Analytics
Using the new perspective Attack Analytics incidents give us, we can use a statistical approach to find false positives.
We can build a supervised machine learning model that will classify an Attack Analytics incident as false positive.
The features of the model can be the attributes of the incident, e.g.:
- The amount of source IPs
- The amount of browsers
- The amount of targeted URLs
- Incident duration
- And many more…
Our team built the model by labeling different examples of real alerts and false positives. Using these diverse examples, the model learned to identify the statistical properties of a false positive incident.
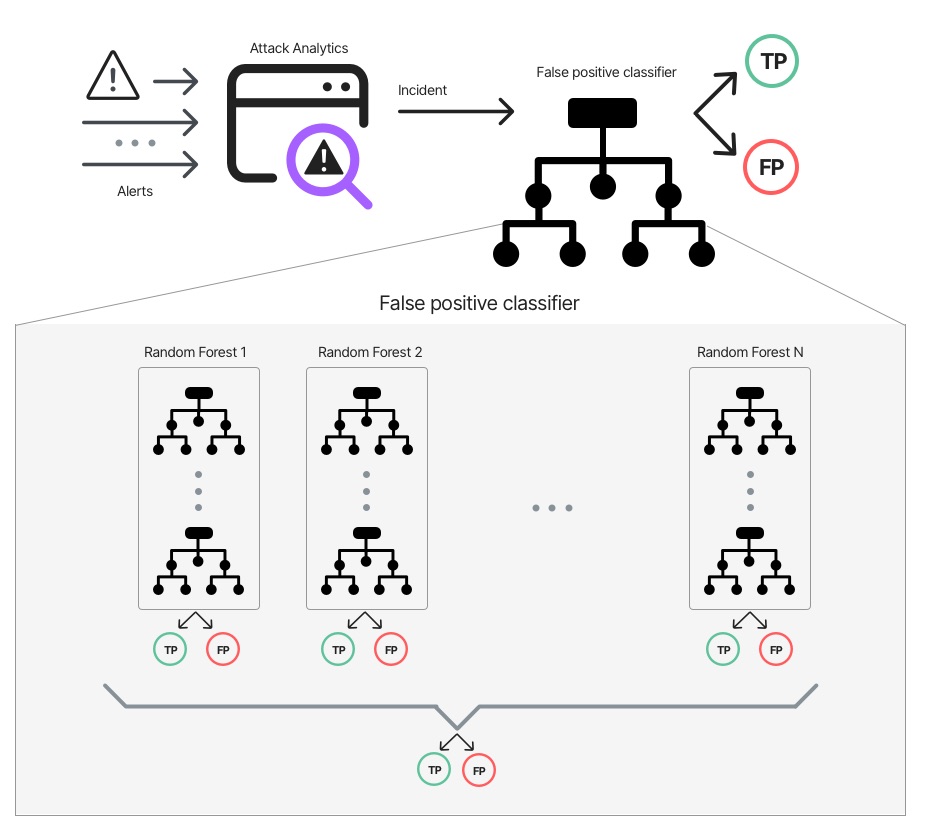
Attack Classification using Random Forest Classifier model
Cyber Attack Data Collection and Classification
The labeling task was done mostly manually – we went through our customers’ incidents and labeled them. Some true alerts can be found automatically, when the attack is very obvious.
To try and imitate the ‘real world’ scenario, we divided Imperva incidents data into significant attack types subsets like SQLi, XSS, and Remote Code Execution. Then, for each attack type subset, we labeled each incident as False or True incident so that the overall labels distribution for each attack type will approximately meet our ‘real word’ false positive distribution assumptions at Imperva. For example, based on our domain knowledge assumptions, XSS attacks are more prone to false positives than other types of attacks and therefore more false alerts of this kind were sampled and labled.
We ended up labeling the data at 1:10 ratio – meaning that for every false positive incident that we sampled and labeled in the real world we labeled 10 other true incidents. Recall that this ratio artificially and implicitly derived by the different attack types false positive distributions. It also matches our assumption that false positives incidents constitute only a small portion of the alerts in the system. In fact, there are probably much less than 10% of false positives in the real world. Yet, we still want to have sufficient number of false alerts examples for the model to learn well, so we found this tradeoff as optimal for our task.
The labeling process resulted in a couple of hundred labeled incidents – a small dataset, likely to have high variance. However, labeling is a difficult and time-consuming task, so instead of labeling more data, we overcame the small dataset difficulties when constructing the model.
Building The Model for Machine Learning Web Application Firewall
At first, the model we used was a Random Forest. It didn’t work well. We trained several Random Forests over different train-test splits, and occasionally, a model with horrible results was created. That was a strong indication that the dataset is too small. Having little labeled data made our train and test distribution different from one another.
At this point, we noticed something interesting. For each sample, most of the models we tested on it gave the right prediction. That gave us the idea to use an ensemble of Random Forests, each of which was trained on a subset of samples from the training data. The Forests with the best score were used in the final model and the final prediction is the average of their overall predictions.
When optimizing the results, the most important metric in this case is precision. As much as we want to filter out false positives, we want to miss as few real alerts as possible.
Result
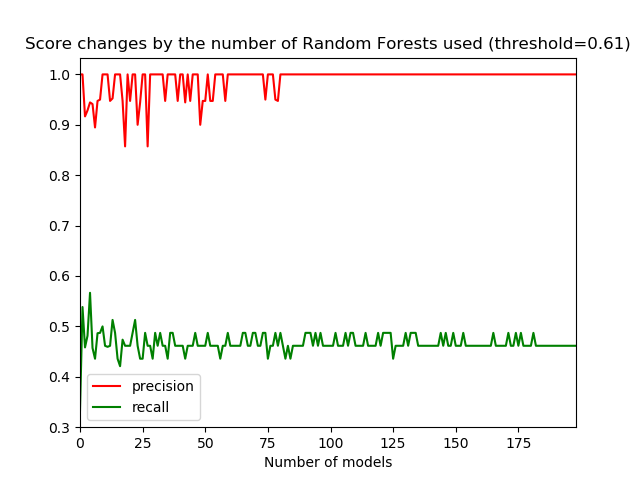
With precision as our most important metric, we reached the high precision score of one. However, that was at the expense of the recall, which was significantly lower – slightly less than 0.5. The results show the model didn’t identify true alerts as false alerts. But many false alerts were not identified as such by the model.
The graph below shows the influence of the number of Random Forests in the ensemble on the model’s score. During the training, 200 Random Forests were trained. The red line shows that the precision stabilizes as the size of the ensemble grows. It also shows that an ensemble of around 80 Random Forests should be enough to get a high precision. The recall score takes longer to stabilize and will require an ensemble of almost 180 Random Forests.
Another interesting thing to know is how many alerts this model classifies as false positive alerts on real data. We ran the model over several of our customers’ incidents. About 70% of the customers had a small fraction of a percentage of false positive incidents on average. The rest had applications that are naturally prone to false positive incidents (e.g. a JavaScript teaching site) and therefore had slightly higher false positives. Usually the incident will be on a specific URL or a specific parameter that repeatedly produces similar incidents.
Life without false positives?
The results above show that the problem of false positives and WAF alerts can be partly mitigated, at least when using the context of an incident and not a single HTTP request.
Making the dataset richer, either by manually labeling more data or by customer automatic feedback, could improve this model greatly.
The model described in this post considers only the metadata of a group of alerts. It does not use the content of a single alert. So another approach should also be considered – a model that takes alerts as input rather than incidents and learns their content. For example, it can use the number of unprintable characters or the number of HTML tags as features. The combination of the content-aware approach and the incident-aware approach could give a full solution to false positives in WAF.
The post Avoid Alert Fatigue: Web Application Firewall Installation, Configuration and Best Practices appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Aiah Lerner. Read the original post at: https://www.imperva.com/blog/avoid-alert-fatigue-web-application-firewall-installation-configuration-and-best-practices/
