

Not just for Processing: How Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance

The Apache Kafka Streams library is used by enterprises around the world to perform distributed stream processing on top of Apache Kafka. One aspect of this framework that is less talked about is its ability to store local state, derived from stream processing.
In this blog post we describe how we took advantage of this ability in Imperva’s Cloud Application Security product. Using Kafka Streams, we built shared state microservices that serve as fault-tolerant, highly-available Single Sources of Truth about the state of objects in the system, which is a step up both in terms of reliability and ease of maintenance.
If you’re looking for an alternative approach to relying on a single central database to maintain the formal state of your objects, read on…
Why we felt it was time for a change for our shared state scenarios
At Imperva, we need to maintain the state of various objects based on the reports of agents (for example: is a site under attack?). Prior to introducing Kafka Streams, we relied in many cases on a single central database (+ Service API) for state management. This approach comes with its downsides: in data-intensive scenarios, maintaining consistency and synchronization becomes a challenge, and the database can become a bottleneck or be prone to race conditions and unpredictability.
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 1: typical shared state scenario before we started using Kafka and Kafka Streams: agents report their views via API, works with single central database to calculate updated state
Illustration 1: typical shared state scenario before we started using Kafka and Kafka Streams: agents report their views via API, works with single central database to calculate updated state
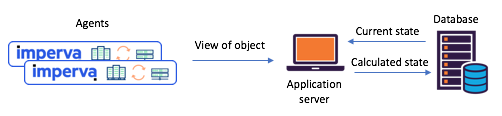 Illustration 1:
Illustration 1:Enter Kafka Streams – shared state microservices creation made easy
About a year ago, we decided to give our shared state scenarios an overhaul that would address these concerns. Kafka Streams immediately came to mind, being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) that we needed – not to mention Kafka being a reliable and mature messaging system.
At the core of each shared state microservice we built was a Kafka Streams instance with a rather simple topology. It consisted of 1) a source, 2) a processor with a persistent key-value store, and 3) a sink:
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 2: default topology for our shared state scenario microservices’ streams instances, Note there’s also a store used for persisting scheduling metadata, which will be discussed in a future post
Illustration 2: default topology for our shared state scenario microservices’ streams instances, Note there’s also a store used for persisting scheduling metadata, which will be discussed in a future post
 Illustration 2
Illustration 2In this new approach, agents produce messages to the source topic, and consumers, e.g. a mail notification service, consume the calculated shared state via the sink topic.
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 3: new flow example for shared state scenario: 1) agent produces message to source topic in Kafka; 2) shared state microservice (using Kafka Streams) processes it and writes calculated state to sink topic in Kafka; and 3) consumers consume new state
Illustration 3: new flow example for shared state scenario: 1) agent produces message to source topic in Kafka; 2) shared state microservice (using Kafka Streams) processes it and writes calculated state to sink topic in Kafka; and 3) consumers consume new state
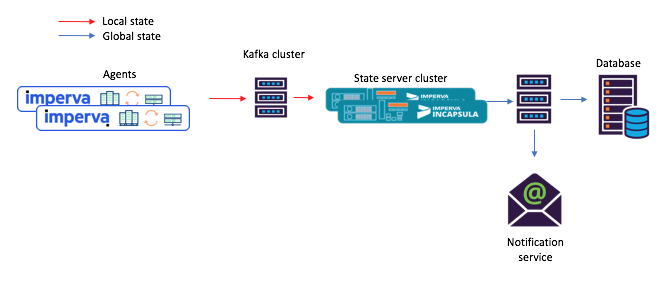 Illustration 3:
Illustration 3:Hey, that built-in key-value store is quite useful!
As mentioned above, our shared state scenario’s topology includes a key-value store. We found several uses for it, and two of these are described below.
Use case #1: using the key-value store in calculations
Our first use for the key-value store was to store auxiliary data that we needed for calculations. For example, in some cases our shared state is calculated based on a majority vote. The store allowed us to persist all the agents’ latest reports about the state of some object. Then, upon receiving a new report from some agent, we could persist it, retrieve all the other agents’ reports from the store and re-run the calculation.
Illustration 4 below describes how we made the key-value store available to the process method of the processor, so we could use it when processing a new message.
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 4: making the key-value store available to the process method of the processor (each shared state scenario then needs to implement the doProcess method)
Illustration 4: making the key-value store available to the process method of the processor (each shared state scenario then needs to implement the doProcess method)
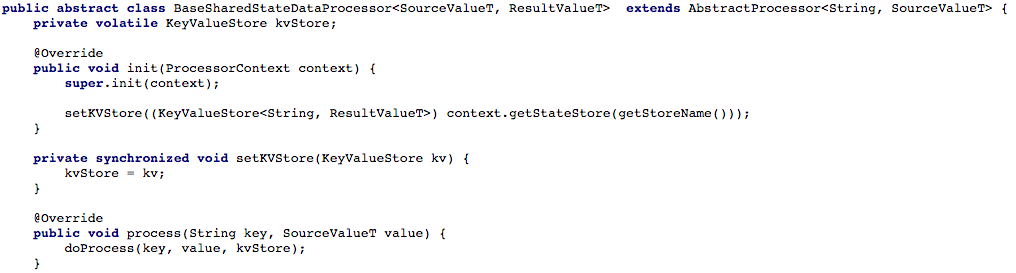 Illustration 4:
Illustration 4:Use case #2: creating a CRUD API on top of Kafka Streams
After our basic flow was in place, we sought to also provide a RESTful CRUD API in our shared state microservices. We wanted to allow retrieving the state of some/all objects, as well as setting/purging the state of an object (useful for backend maintenance).
To support the Get State APIs, whenever we calculate a state during processing, we persist it to the built-in key-value store. It then becomes quite easy to implement such an API using the Kafka Streams instance, as can be seen in the snippet below:
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 5: using built-in key-value store to quickly obtain previously-calculated state of object
Illustration 5: using built-in key-value store to quickly obtain previously-calculated state of object
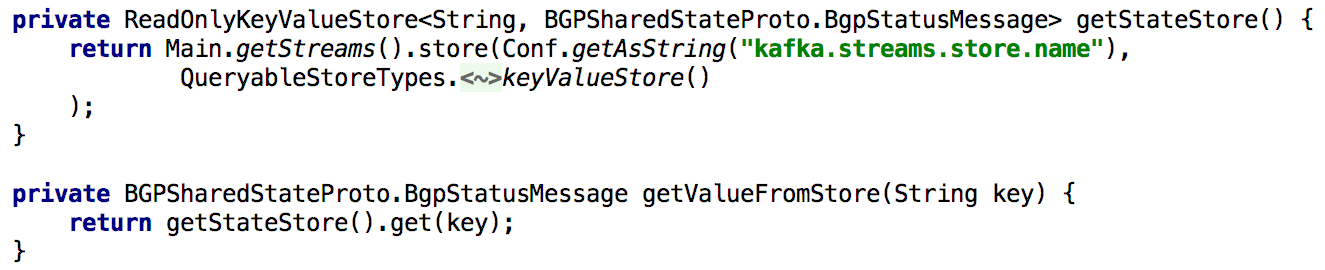 Illustration 5
Illustration 5Updating the state of an object via the API was also not difficult to implement. It basically involved creating a Kafka producer, and producing a record consisting of the new state. This ensured that messages generated by the API were treated in exactly the same way as those coming from other producers (e.g. agents).
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 6: setting state of an object can be done using Kafka producer
Illustration 6: setting state of an object can be done using Kafka producer
 Illustration 6:
Illustration 6:Slight complication: multiple Kafka partitions
Next, we wanted to distribute the processing load and improve availability by having a cluster of shared state microservices per scenario. Set-up was a breeze: after configuring all instances to use the same application ID (and the same bootstrap servers), everything pretty much happened automatically. We also defined that each source topic would consist of several partitions, with the aim that each instance would be assigned a subset of these.
A word about preserving the state store, e.g. in case of failover to another instance, is in order here. Kafka Streams creates a replicated changelog Kafka topic (in which it tracks local updates) for each state store. This means that the state store is constantly backed up in Kafka. So if some Kafka Streams instance goes down, its state store can quickly be made available to the instance that takes over its partitions. Our tests showed that this happens in a matter of seconds, even for a store with millions of entries.
Moving from one shared state microservice to a cluster of microservices made it less trivial to implement the Get State API. Now, each microservice’s state store held only part of the world (the objects whose key was mapped to a specific partition). We had to determine which instance held the specified object’s state and did this using the streams metadata, as can be seen below:
![Not just for Processing: how Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance]() Illustration 7: we use streams metadata to determine which instance to query for specified object’s state – similar approach was taken for GET ALL API
Illustration 7: we use streams metadata to determine which instance to query for specified object’s state – similar approach was taken for GET ALL API
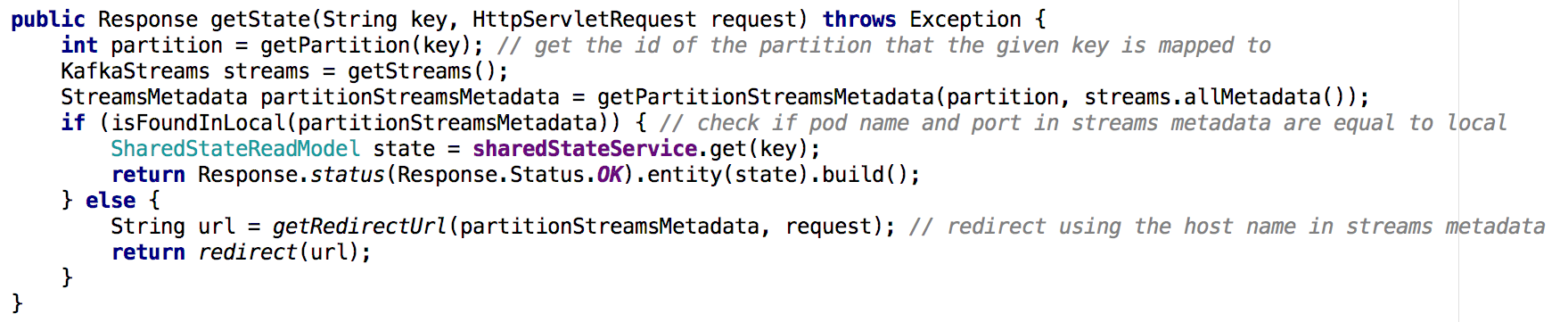 Illustration 7:
Illustration 7:Main takeaways
- Kafka Streams’ state stores can serve as a de facto distributed database, constantly replicated to Kafka
- CRUD API can easily be built on top of it
- Multiple partitions require a bit of extra handling
- It’s also possible to add one or more state stores to a streams topology for the purpose of storing auxiliary data. It can be used to:
- persist data that is needed for state calculation during stream processing
- persist data that can be used during next init of the streams instance
- much more…
These and other benefits make Kafka Streams a strong candidate for maintaining global state of a distributed system like ours. It has proven to be quite robust in our production environment (practically no lost messages since its deployment), and we look forward to expanding on its potential further!
The post Not just for Processing: How Kafka Streams as a Distributed Database Boosted our Reliability and Reduced Maintenance appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Nitzan Gilkis. Read the original post at: https://www.imperva.com/blog/not-just-for-processing-how-kafka-streams-as-a-distributed-database-boosted-our-reliability-and-reduced-maintenance/
