

Developers Versus Automation Engineers: How We Ended the Fighting with the Right CI Process
Hey developers and DevOps professionals: what if I told you that how you wrap and execute your automation tests could be the key to making your development process faster, more professional and stable, and stop the bickering between your developers and automation teams?
This post will describe how we, the Automation team, created a new Continuous Integration (CI) process that enabled us to verify one of our group’s most common processes and keep ourselves sane while dealing with painful recoshets, improvement suggestions, remarks and comments from our many developer teams.
You’ll witness the conflicts we had — along with, to be fair, the developer teams’ pain points. You’ll also hear about the power of pipeline jobs, and hopefully pick up a few tips on how to smooth Automation-Developer team interactions.
Our old approach had an improvement process that was time-consuming for both parties. It was also nearly impossible to debug and caused huge tension throughout the R&D teams.
What is the Configuration Update Procedure?
All over the world, Automation engineers are developing tests and executing them automatically via jobs using Jenkins, Teamcity, TFS, and other Automation services.
In the security world in which Imperva operates, there’s a constant need — especially for security teams — to keep our products’ codebases updated with the latest attacks. This is why a big portion of these teams’ daily work is to update configurations in production environments.
Now, you surely can’t expect this new data not to be verified before going to production, right?
This is why we’ve combined several steps into a single test that insures our main points of failure are still green on a staging environment — and that we’re good to go to production.
The Problem with Constant Redesigns
Our motivation for improving the old test mechanism was that this small but useful test had turned into a battlefield, with many teams involved all trying to make it better. Many stakeholders wanted to add more steps and features for their own needs, or they asked to be notified via well-defined e-mails. All of these requests, combined with the less-than-stable production environment, caused our test results to be flakier and less accurate. This created a lot of tension, with arguments flaring up between teams almost every day.
Instead of developing patches along the way, we decided to allocate time for refactoring and rethinking which steps should be done and when, so we could improve our notification process (integrating Slack was one such improvement). Basically, we recreated the test and refactored it to make it more stable and bug-free.
Was that the end of the drama?
After launching this new, improved test, we discovered that each failure forced us to become a “router” between teams, searching for that one developer who could fix the problem. As a small Automation team which covers our codebase using hundreds of tests, this test wasn’t our main priority. We became a useless bottleneck for the developer teams. So we decided to perform another final redesign.
Our winning approach
After another brainstorm, we decided to integrate a Continuous Integration (CI) process into this test for the first time.
What’s CI? A development practice where developers integrate code into a shared repository frequently — preferably several times a day. Each integration can then be verified by an automated build and automated tests.
If you’re eager to learn about the core advantages of integrating CI in your company, be sure to read this blog post.
When we first started this new and exciting journey, our test had 20+ steps. The first one updated our staging environment with the new configurations. All of the other steps were solely to examine our servers and ensure they behaved the same.
In the new modular approach, each step is executed only if the prior test is passed. It’s much more efficient and stable.
 Meet Groovy
Meet Groovy
You could develop Jenkins pipelines without any idea what Groovy actually is.
But if you want that killer pipeline with all your personal configurations, learning a little bit about Jenkins (here’s a good resource) could be very beneficial.
Using Groovy, there’s a lot you can define:
- Which agents to run
- Disable concurrent builds (including blocking every attempt to run simultaneously and possibly ruin both executions)
- Which branch to execute the job
- Which team / person will be notified and for which stage
- And much more…
Also, you can insert beautiful scripts inside that basically perform everything you’ll ever need.
Wait, Who’s the Owner?
Up until now, we knew more or less which dev team is somehow related to almost every failure. But that’s not enough… if you want your pipeline to notify relevant owners, you should divide it into small blocks and assign each team to its relevant ones.
Your notification plan should also take into account that many failures will actually be because some developer changed a file. Let’s assume this file changes the logic of your validation and messes with it. You shouldn’t notify this block’s owner, but the committer(s). So what you should do is to search whether anyone committed anything since last time it passed, and notify him/her. If there’s more than one committer, send them all messages.
This is exactly what we’ve done — tracked every SVN commit and notified its owner.
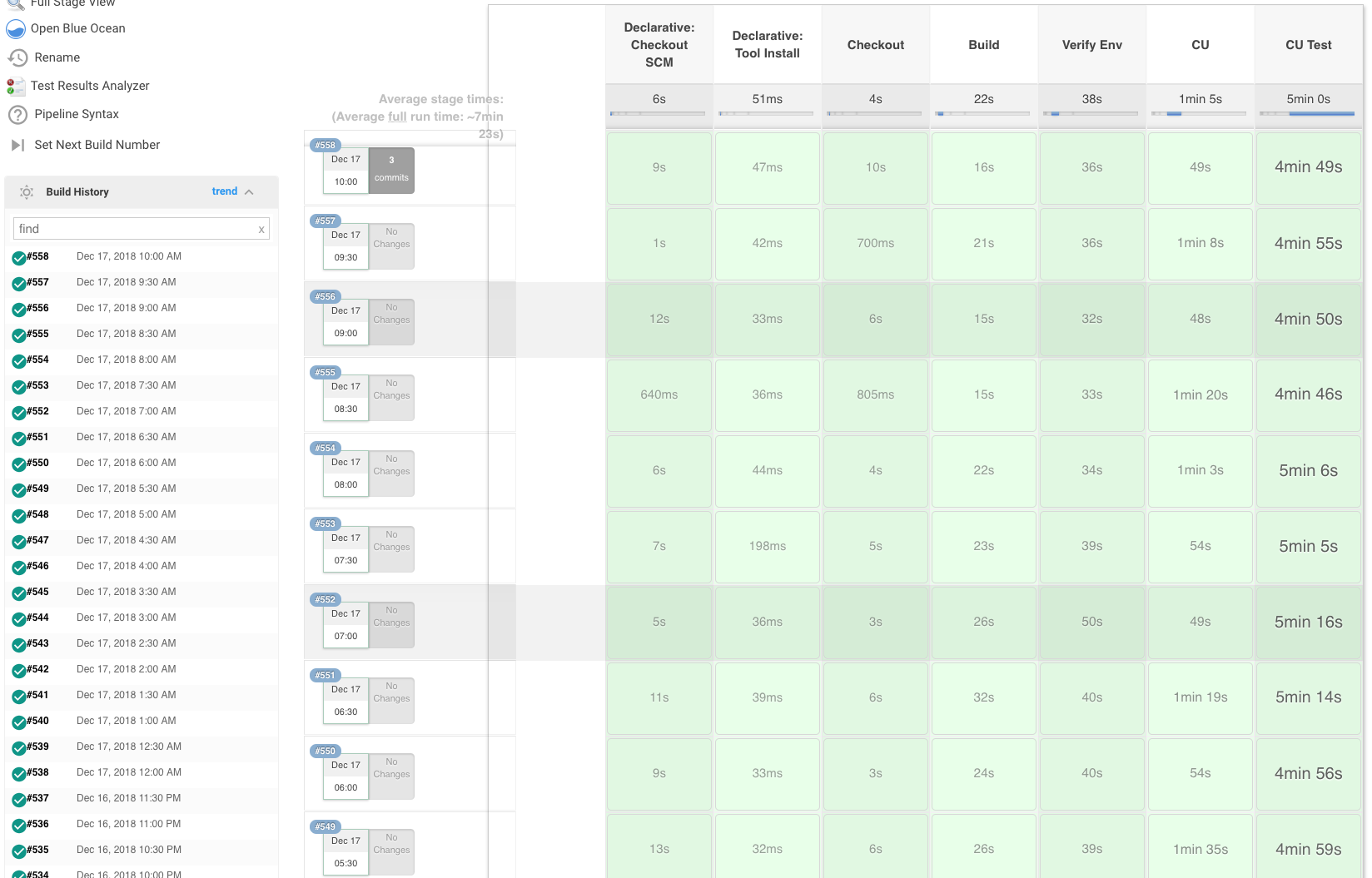 Yep, it’s green alright.
Yep, it’s green alright.
What We’ve Gained?
In one word? Respect.
Three words? Stability And Trust.
We’ve defined a complete flow which goes into action whenever this pipeline fails and someone is being notified. That person should fix the issue in hand, execute the pipeline again, and be responsible to reply once it passes. If another owner joins (either due to commit(s) they’ve done or because their team is related to it), the original owner remains responsible for orchestrating the fix.
The pipeline is much more stable than the prior test. We’ve focused only on the necessary steps and built a defense mechanism which executes them only after many predefined steps pass. That means there’s a safety net which guards our test and prevents it from running when it doesn’t need to.
This new flow also improved the Automation-Dev relationship. We took the initiative and went all the way, and it’s highly appreciated by our colleagues.
So… What’s Next?
There’s still a lot we can do. Fine Tuning the pipeline steps. Intentionally blocking “bad” commits. Adding more notification options, optimizing execution time, etc.
However, keep in mind that we’re now operating at a much higher level. We’re not struggling and “clogging holes”. This process works for us. As the first Automation CI we’d ever done, we started this adventure without knowing what would result. All in all, it was definitely worth the risk.
The post Developers Versus Automation Engineers: How We Ended the Fighting with the Right CI Process appeared first on Blog.
*** This is a Security Bloggers Network syndicated blog from Blog authored by Nir Bilgory. Read the original post at: https://www.imperva.com/blog/developers-versus-automation-engineers-how-we-ended-the-fighting-with-the-right-ci-process/
