
Scraping Attacks: Compromising Web Security, Impacting Business Continuity
We often see businesses devising ingenious ways to pull ahead of competitors in the hyper-competitive online business industry. From tiny startups to business giants such as Amazon and Walmart, companies today have dedicated teams to track competitors’ pricing strategy and product catalogs. Many online businesses either employ an in-house team or leverage the expertise of professional web scrapers to gain competitive intelligence.
These attacks are planned in various stages to evade the vulnerabilities of existing security systems such as web application firewalls (WAFs), intrusion detection systems/intrusion prevention systems (IPS/IDS) and other in-house measures that lack the historical look-back, deep learning capabilities and the ability to sniff automated behavior in syntactically correct HTTP requests.
Scrapers use exploit kits that comprise a combination of tools (such as proxy IPs, multiple UAs and programmatic/sequential requests) to intrude into web applications, mobile apps and APIs. Website security and business continuity can be grossly undermined due to such attacks. For instance, an attack that we monitored on a popular e-commerce portal involved multiple stages to bypass prevailing security measures.
Let’s take a closer look at what happened during this attack:
A popular e-commerce portal was inundated with scraping attacks and faced hundreds of thousands of hits on its category and product pages during a 15-day period. Attackers deployed a purpose-built scraper engine to execute attacks and used an “exploit kit” with different ready-to-use combinations of hardware and software to bypass web defense systems. The attack was executed in three stages: (1) fake account creation (2) scraping of product categories, and (3) scraping of product categories.
Stages of the Attack
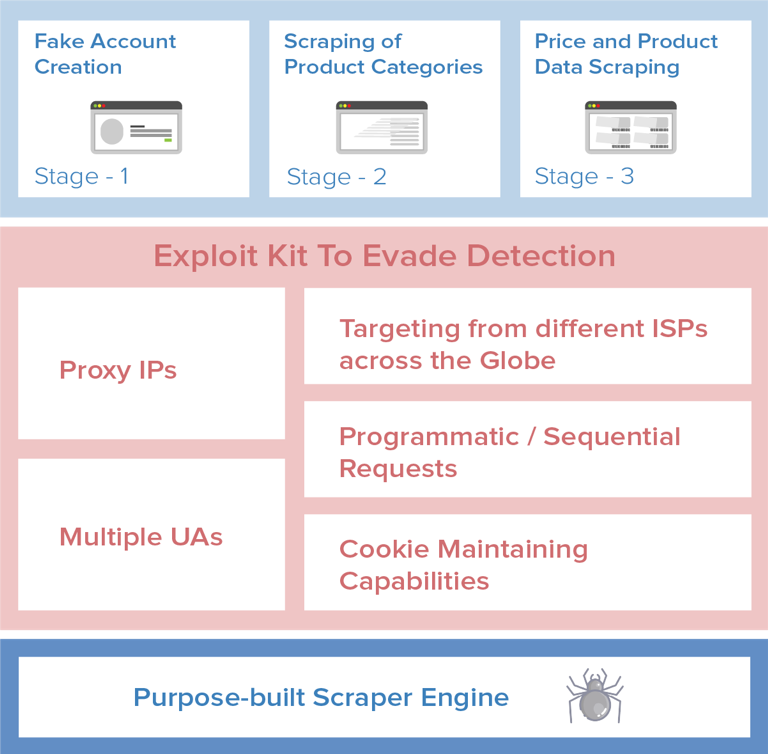
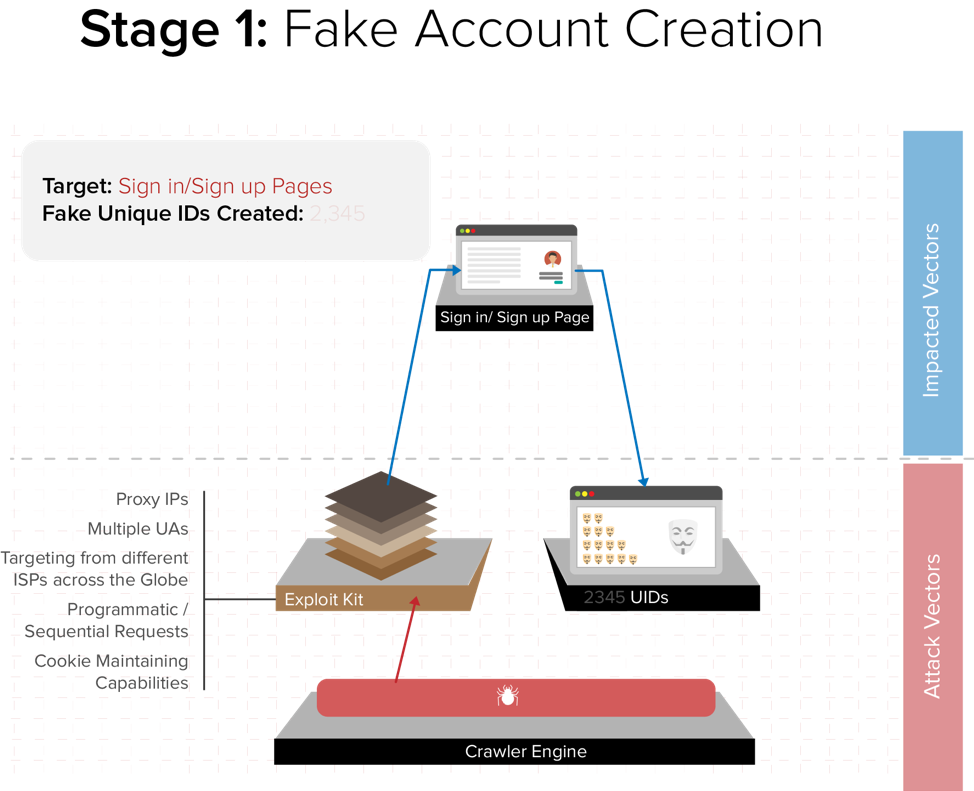
Fake Account Creation
Attackers targeted the sign-up page using different attack vectors. They created multiple fake UIDs (User IDs) to register bots as legitimate users on the website. They then used these fake accounts in combination with different device IDs, cookies and UAs to masquerade as genuine users and generate perfectly valid HTTP requests to easily circumvent rule-based conventional security measures.
 Scraping of Product Categories
Scraping of Product Categories
Using the fake UIDs, attackers logged into the website and made hundreds of thousands of hits on category pages to scrape content from category results.
 Price and Product Information Scraping
Price and Product Information Scraping
After scraping the category pages, attackers carried out hundreds of thousands of hits on specific product pages and managed to store the prices and product details of targeted products in their own database.
The attackers maintained a real-time repository of the entire product catalog on the e-commerce portal. They also regularly tracked the price changes to keep their database updated with the latest pricing information.
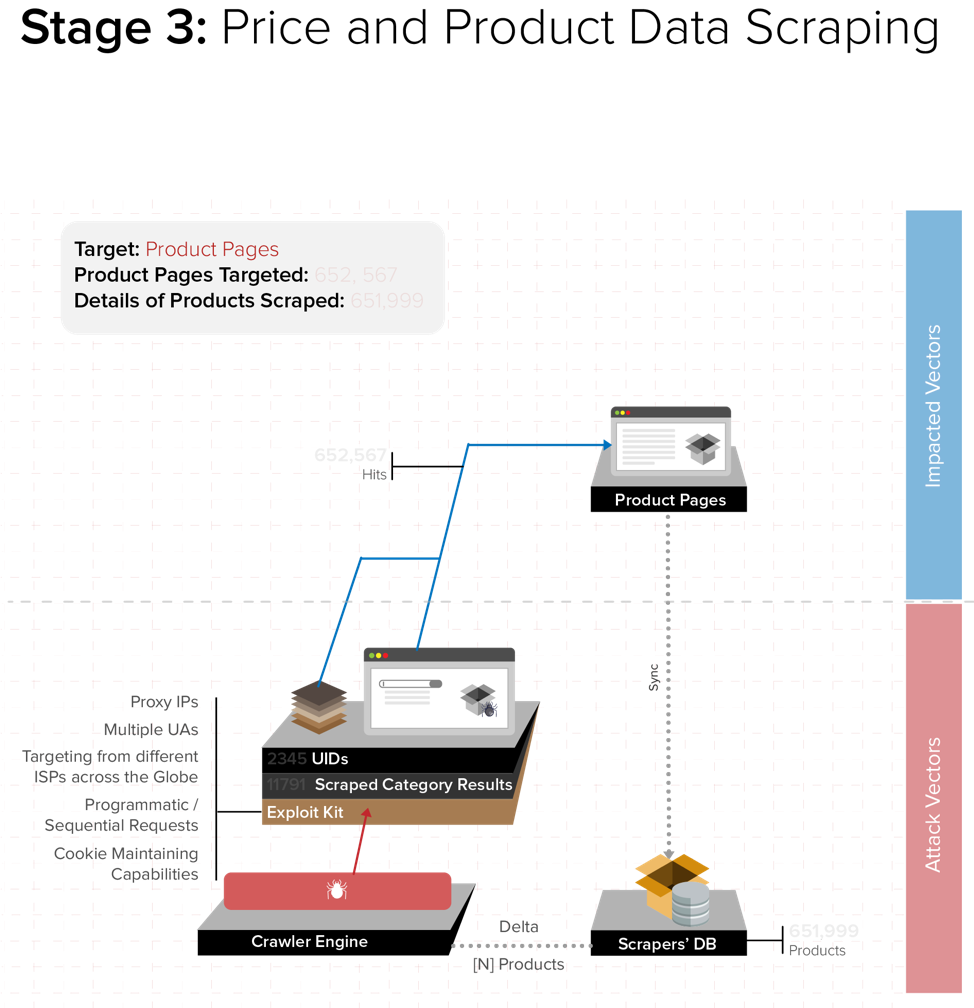
Topology of The Attack: How Three Stages Work in Unison
All the three stages were part of a single, large-scale scraping attack and worked in unison to perform real-time monitoring of product pages.

During the attack, we observed that rule-based systems were incapable of stopping exploitation on the application layer. Other automated attacks such as account takeover, API abuse, application DDoS and carding are also performed on the application layer and failure in detecting such sophisticated attacks can heavily impact the business continuity.
Measures to Combat Scraping
All large e-commerce platforms have sophisticated bot activity on their website, mobile apps and APIs that can expose them to scraping and loss of gross merchandise value (GMV). E-tailers must be diligent in their approach to find and mitigate malicious sources of bot activity.
Spot highly active new or existing user accounts that don’t buy: E-commerce portals must track old or newly created accounts that are highly active on the platform but haven’t made any purchases in a long time. Such accounts may be handled by bots, which mimic real users to scrape product details and pricing information.
Don’t overlook unusual traffic on selected product pages: E-tailers should monitor unusual spikes in page views of certain products. These spikes can be periodic in nature. A sudden surge in engagement on selected product pages can be a symptom of non-human activity on your website.
Watch out for competitive price tracking and monitoring: Many e-commerce firms deploy bots or hire professionals to scrape product details and pricing information from their rival portals. You must regularly track competitors for signs of price and product catalog matching.
Build capabilities to identify automated activity in seemingly legitimate user behaviors: Sophisticated bots simulate mouse movements, perform random clicks and navigate pages in a human-like manner. Preventing such attacks require deep behavioral models, device/browser fingerprinting and closed-loop feedback systems to ensure that you don’t block genuine users. Purpose-built bot mitigation solutions can identify such sophisticated automated activities and can help you take action against them. In comparison, traditional solutions such as WAFs are limited to tracking spoofed cookies, user agents, and IP reputation.
