

Do not meme to shame Twitter’s password leak incident
Twitter’s password security breach raised panic among social media users when they announced that they had discovered a bug that “inadvertently stored passwords unmasked in an internal log”.
We recently found a bug that stored passwords unmasked in an internal log. We fixed the bug and have no indication of a breach or misuse by anyone. As a precaution, consider changing your password on all services where you've used this password. https://t.co/RyEDvQOTaZ
The twitter verse and market was in an uproar after the announcement
Shares of Twitter fall nearly 3% after-hours; Reuters reports that the social network has recently reported a "password storage glitch" to regulators. https://t.co/dj2DfzDb2l
— @CNBCnow
and then, memes began to emerge
In light of the @Twitter password issue and folks creating new ones, this is a classic:
— @nvk
chief technology officer of twitter says the multi-million dollar company "twitter" of which the chief technology officer works for didn't have to tell the service user-base that their twitter account passwords were stored in plain-text for several months very good
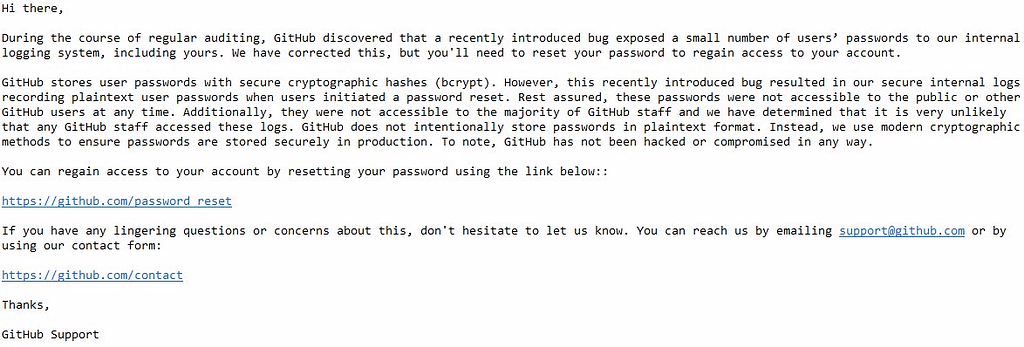
Before you tweet your meme to shame Twitter, let me remind you that GitHub faced somewhat of a similar issue not too long ago
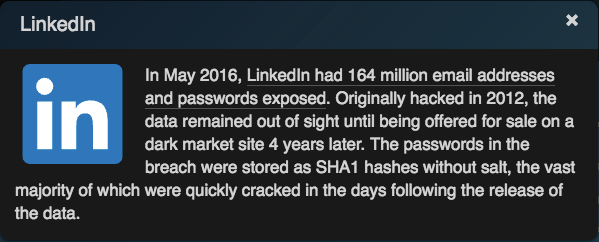
and in 2016, LinkedIn faced a data breach as a consequence of passwords stored as SHA-1 hashes without salting
Twitter, LinkedIn and GitHub are forward thinking organizations with very sound engineering and security principles. Let’s face it, most of us are guilty of either logging sensitive data or trading out security for new customer features.
A data breach is a consequence of either data exfiltration due to an attack , data leak caused by inadvertent programming errors or poor design decisions.
Programmers certainly have a lot on their plates and while security has been a burning issue in recent times, it hasn’t been their top priority. Although there may be some resistance to expanding their roles in securing software, most want to write secure code but many don’t know what that means. The awareness is restricted to some basic principles: input validation, encrypt data in transit and limit privileges. Many are not equipped to address advanced exploits. An application, after all, is composed of many parts (open source libraries, 3rd party SDKs, open source frameworks etc.) and one has to semantically examine this composition in it’s entirety in order to its weaknesses (attack surface).
Rather than make Twitter’s password incident an easy piñata to beat on, let us collectively take a moment to pause and reflect on the security posture of software that we have been authoring, sustaining or perhaps protecting.
In order to reason about data leaks, let’s apply first principles thinking to quantify an application’s surface in four concrete dimensions: entry point(s) , data , flow(s) and exit point(s).
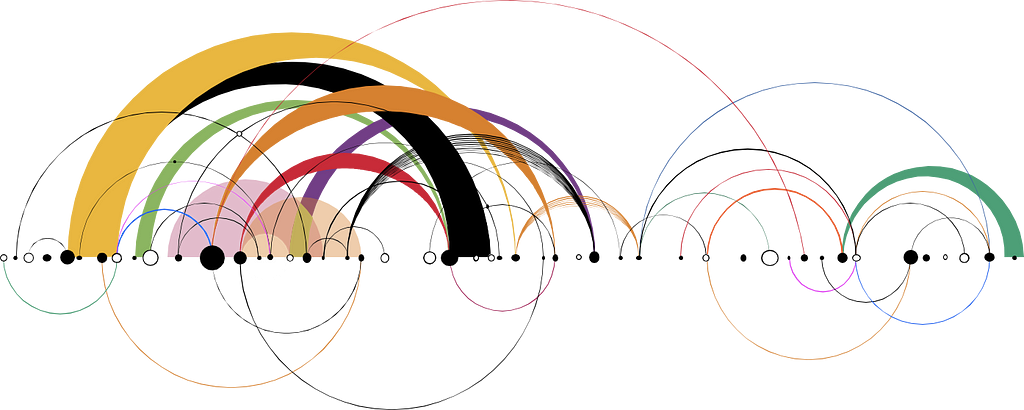
- An application comprises of one of more primary “flows”
- A flow is a set of functions working in concert with each other to serve a business need. Multiple flows in an ordered sequence represent a primary flow
- A flow is triggered at an entry point, which marks the beginning of a business process workflow. The entry point could be a web route (e.g., /login, /register, /logout, /followers, /following, /search?q=meme)
- Upon being triggered, a data model instance is either created, accessed or updated to represent business entities (e.g., customer, adSense, tweets, followers, following) participating in the business process (e.g., updateProfile, unFollow, follow) . Some data models can be deemed sensitive (based on compliance and regulations). Such sensitive data instances need to be treated with proper care. Can we, as application or data stewards, confidentiality answer the following questions about our hosted applications?
Can you identify sensitive data using semantics (based on variable names, entity name and it’s properties and what business purpose is being served)?
Is the sensitive data instance in question participating upon a flow having no authorization at entry point?
Is the sensitive data instance exiting the crevice of an exit point without being hashed, encrypted, salted or anonymized?
Is the sensitive data instance exiting the crevice of an exit point that is not yet authorized to be a point of exit?
If multiple micro-services of an application are working in concert with each other, what is the defined trust boundary?
- When triggered at entry point , a flow establishes communication paths with one or more exit points or interfaces either in read or write mode (e.g., database, filesystem, process, socket, log)
The aerial view above causes perceptive illusion.
In order to make things a bit simpler let us extract one single flow that is easier to comprehend
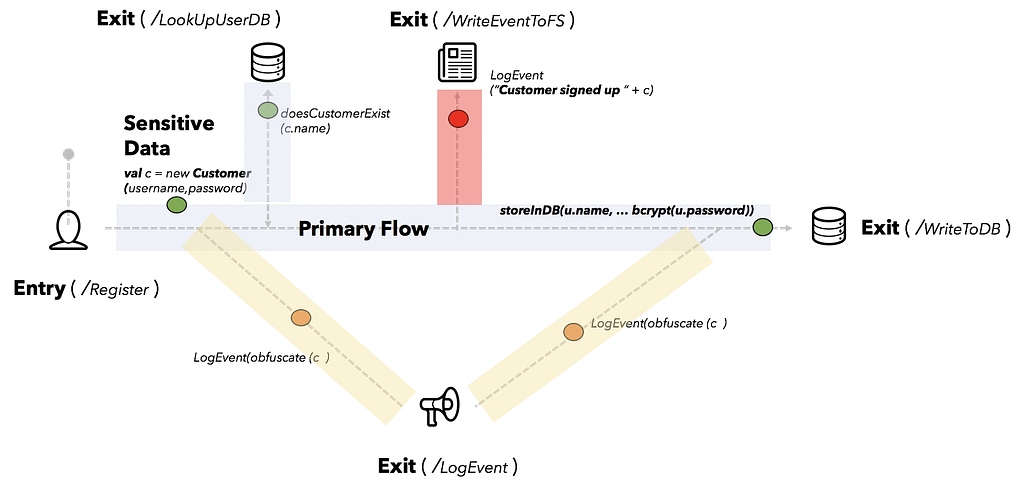
This flow depicts a typical registration or signup process in any SaaS application.
A consumer triggers a /Register process, which in turn starts a series of flows
- Create a customer entity with appropriate properties in scope of session
- Check if customer already exists in system database (/doesCustomerExist)
- Continuously log or trace customer activity for observability (/LogEvent)
- Apply a slow and secure “one-way” hash function upon user password using bcrypt (e.g., bCrypt(u.password))
- Persist user credentials and properties in database (/writeToDB)
Wait a minute, we missed a step. Somewhere between (2) and (4), the entire customer object is serialized and persisted on disk. Note that the customer object contains a field password in cleartext. Thereafter, this file might be streamed to a secondary index for search. This index might be available for administrators, engineers and support staff to triage for incidents. We have inadvertently leaked credentials of the entire customer base. Twitter and GitHub faced somewhat of a similar situation
- Was this an approved exit point ?
- At which version of SDLC was this introduced ?
- What have we done here ?
- Is sha1(FIXED_SALT + password) , sha1(PER_USER_SALT + password) or BCrypt(..) better ?
- Is BCrypt(..) consistently used across all applications/micro-services in the organization?
- How can we fix this ?
- Is there a sustainable automated way to monitor and ensure that this does not repeat ?
We need an instrument to continuously quantify the evolving shape of our application

This shape takes its form by encompassing entry points, exit points, flow binding these points, data elements participating in flows and transform functions applied to data elements in scope of a flow.
This shape is rapidly changing pertaining to every new version of an application deployed in production.
This shape is informed of a risk model derived from all properties specified above, which is extrapolated during CI (build time) and CD (runt time)
I would ask of you readers to speak to your engineering and security teams to ask if they understand the evolution of an application shape. If not, they need to make this a priority as attackers/hackers from the outside have their own sprint, scrums and velocity. Their prize is your “data” and your application’s vulnerabilities are their “attack instruments”.
At ShiftLeft, we’re here to help! We’re offering a free data leakage assessment. It requires minimal effort and you’ll get a wealth of knowledge to harden your app’s security posture. Sign up here:
https://go.shiftleft.io/data-leakage-assessment
Do not meme to shame Twitter’s password leak incident was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from ShiftLeft Blog - Medium authored by Chetan Conikee. Read the original post at: https://blog.shiftleft.io/do-not-meme-to-shame-twitters-password-leak-incident-1713dfbc7c74?source=rss----86a4f941c7da---4
