
Simbian Advances the AI Frontier With Industry’s First Benchmark for Measuring LLM Performance in the SOC
The flood of AI hype in security has left most organizations asking two basic questions: “Does AI actually work, and how will it add real value to my business?” Simbian believes it’s time to put hard numbers behind the industry marketing noise, and their new benchmark does exactly that.
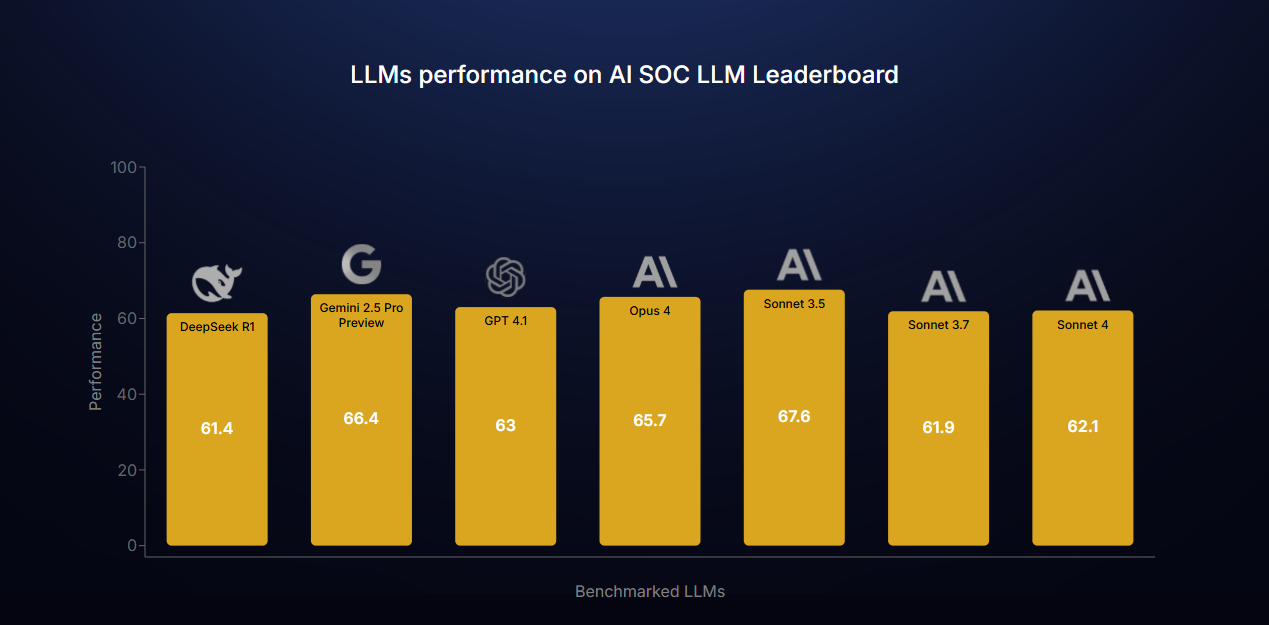
On June 12, 2025 Simbian unveiled what it calls the AI SOC LLM Leaderboard. It’s the first benchmark to fully measure large language model (LLM) autonomous performance across the full life cycle of alert investigation in a Security Operations Center (SOC). And it’s not just another paper tiger. The benchmark runs LLMs through realistic, full-kill-chain scenarios with actual SOC tools in a lab that mirrors enterprise conditions. “SOC analysts and vendors are embracing LLMs to scale operations, increase accuracy, and reduce costs,” said Simbian CEO and co-founder Ambuj Kumar. “But they haven’t had a way to compare options until now.”
The benchmark tested top-tier models from OpenAI, Anthropic, Google and DeepSeek. Each was scored based on how well it performed across all phases of alert investigation, from alert ingestion to final reporting. The surprising result: All models could autonomously complete 61% to 67% of the required tasks, as long as they were supported by a solid framework.
That framework came from Simbian’s own AI SOC Agent, the same solution behind their first AI SOC Hackathon earlier this year. “This isn’t just about fragmented applications of AI, like summarizing alerts,” said Igor Kozlov, Simbian’s AI/ML Lead. “We’re showing what generative AI can do end-to-end in the context of real SOC work. And we’re being honest about where humans are still needed.”
Human Augmentation NOT Replacement
That honesty is key. In a time when some vendors and well-known industry analysts claim, “AI will replace CISOs” and “AI is coming for your job,” Simbian is making the case for something more grounded. “People keep asking, is AI coming for SOC jobs?” said Kozlov. “But the benchmark shows clearly, we’re not at ‘mojitos-on-the-beach levels’ of automation, and honestly, nobody is looking to replace humans. Humans still handle complex tasks. What AI can do is speed up the repetitive, structured parts at scale.”
That framing, AI as augmentation, not replacement, is a key theme Simbian is advocating. And they are spot on correct. “Think about junior analysts,” Kozlov added. “The agent gives them ideas they wouldn’t have thought to ask. For senior analysts, it saves time and mental energy. Different values for different skill levels. But it elevates everyone on the team.”
Black Box Testing and Hard Truths
One of the most unusual elements of Simbian’s benchmark is its black box approach. Instead of tailoring the benchmark to a specific model or capability, they threw a set of 100 full-kill-chain-scenario cases at each model and measured the output. “We didn’t tweak the models or coach them in advance,” Kozlov said. “We wanted to see what they could do straight out of the box, with minimal intervention.”
That led to some deeper insights. LLMs performed similarly across the board, again, in that 61% to 67% range, but only when guided by a clear structure. Without it, the models broke down. “You can’t just plug an LLM into a SOC and expect results,” Kozlov said. “You need guardrails. You need a framework.” And yes, you absolutely need humans!
And that framework matters more than the model itself. In one key finding, Simbian noted that so-called “thinking models,” LLMs trained on solving math problems, performed no better than standard ones in most SOC scenarios. “If your framework is solid, you don’t always need the fanciest model,” Kozlov said. “That’s a big deal for organizations trying to balance cost and performance.”
Why AI Benchmarks Matter to Global Businesses
For Simbian, the benchmark isn’t a marketing play or just about flexing thought leadership. It’s about enabling their team and all organizations to make better decisions about AI, both internally and externally.
The private leaderboard helps the team iterate and evolve their own AI SOC Agent by offering test coverage across 100 full-kill-chain scenarios. That allows developers to experiment confidently, knowing any tweak can be immediately measured for impact. It’s a test harness for their own AI agents. With the benchmark in place, the company can now make changes to its agent architecture with confidence and methodically push innovation while ensuring robustness of the overall solution. “We can try new ideas, tweak how the agent works, and know immediately whether we’re improving or breaking things,” Kozlov said.
It also offers ROI clarity. One LLM might be 2% more accurate than another, but if it costs twice as much and takes longer to execute, it might not be the right choice. “We now have data to decide not just what’s best, but what’s best for a particular use case and budget,” Kozlov noted. “By understanding which models do what best, organizations can deploy the right LLM for the right task, avoiding unnecessary spend on high-end models when simpler ones will do it cheaper and faster.”
Long term, Simbian plans to expand the benchmark to cover more security tasks, from code analysis to vulnerability management. But for now, they’re focused on making the SOC faster, smarter, and more scalable, with humans still at the center. “We don’t think you get rid of the analyst,” Kozlov said. “We think you help them stop babysitting duct-taped pipelines of isolated systems and start pushing the business forward.” Simbian plans to open more of the benchmark to the public and share methodology details. While others may cling to proprietary results, Simbian believes transparency builds trust and helps move the application and innovation of AI forward.
Beyond the AI Marketing Fluff and Shiny Object Syndrome (SOS)
As the security community gears up for events like Black Hat, DEF CON and the global Artificial Unintelligence Conference, Simbian’s approach offers a new blueprint for how to evaluate and evolve AI for real-world use, without losing sight of the human element.
The industry has seen too many fake demos and inflated claims. Kozlov wants Simbian’s benchmark to be different. “We’re not saying AI solves everything,” he said. “We’re saying: Here’s what it can do, right now, in real-world conditions. No smoke. No mirrors.”
That transparency is rare, and oh, so refreshing! When I hear companies, analysts and technology pundits pitching AI replacing people, I tune out.
What Simbian’s doing is smarter, and their vision and approach are spot on. Simbian is showing how AI can support people, not erase them.
That’s a message that resonates beyond just the SOC. It is a message for anyone engaging with AI in any manner to embrace now and in the future.
