

How We Trained an LLM to Find Vulnerabilities in Solidity Smart Contracts

At Positive Web3, we live and breathe smart contract security. Our work revolves around analyzing vulnerabilities, researching exploits, and building tools to make code safer. So when the idea of using large language models (LLMs) to analyze Solidity smart contracts surfaced, it felt like a game-changer. Imagine uploading your code, running the model, and receiving a comprehensive vulnerability report — sometimes even with suggested fixes. It sounded like magic.
But as we quickly discovered, there’s a world of difference between what sounds good and what actually works.
Testing the waters with ChatGPT
Our first step was to explore the capabilities of existing language models. Naturally, we started with ChatGPT. At the time, ChatGPT-4 had just been released, and we’d seen intriguing examples of other teams using it to identify bugs in smart contracts.
In our experiments, ChatGPT impressed us with its ability to identify vulnerabilities in simple contracts and simplify or explain code in more complex ones. However, there was one massive roadblock: ChatGPT works only with public data. For private or sensitive code, it’s a no-go for auditing. That limitation was enough to send us searching for alternatives.
Hunting for Solidity analysis tools
Next, we scoured the landscape for tools and plugins capable of analyzing Solidity smart contracts. Most of what we found was outdated, supporting only early versions of Solidity like 0.4 — this, at a time when many compiler-level bugs were still unresolved. The contrast was stark given the current standard is Solidity 0.8.29. For instance, GPTLens caught our attention initially, but its focus on older versions led to a flood of false positives, rendering it impractical.
Amid the clutter, a few tools stood out. The Solidity AI plugin for VS Code, developed by Consensys Diligence, showed promise. It flagged simple vulnerabilities and explained code effectively — handy for surface-level analysis but not robust enough for a full-scale audit.
We also experimented with the “Refactor Selected Code Block” feature in GitHub Copilot and its free counterpart, Codeium. While they weren’t designed for vulnerability detection, they excelled at helping us write proof-of-concept (PoC) code in Solidity. It was a solid assist but not the solution we were searching for.
Creating our own LLM agent
When it became clear that ready-made solutions weren’t up to the task, we decided to build our own LLM agent. On paper, it sounded straightforward: gather a dataset, pick a model, and define a training method. In practice, though, things got a lot more complicated.
The biggest hurdle was the dataset. Most of the available vulnerability databases were either outdated or cluttered with duplicates, often featuring old contracts that weren’t relevant for modern Solidity. To ensure quality training data, we had to be highly selective.
For the model, we turned to the benchmarks of existing LLMs and landed on Llama 3.1. At the time, it was one of the most powerful options available, but it came with a hefty price that amounted to significant resource requirements. To map out the minimum specs, we relied on an LLM resource calculator, ensuring we could support the intense computational demands of the project.
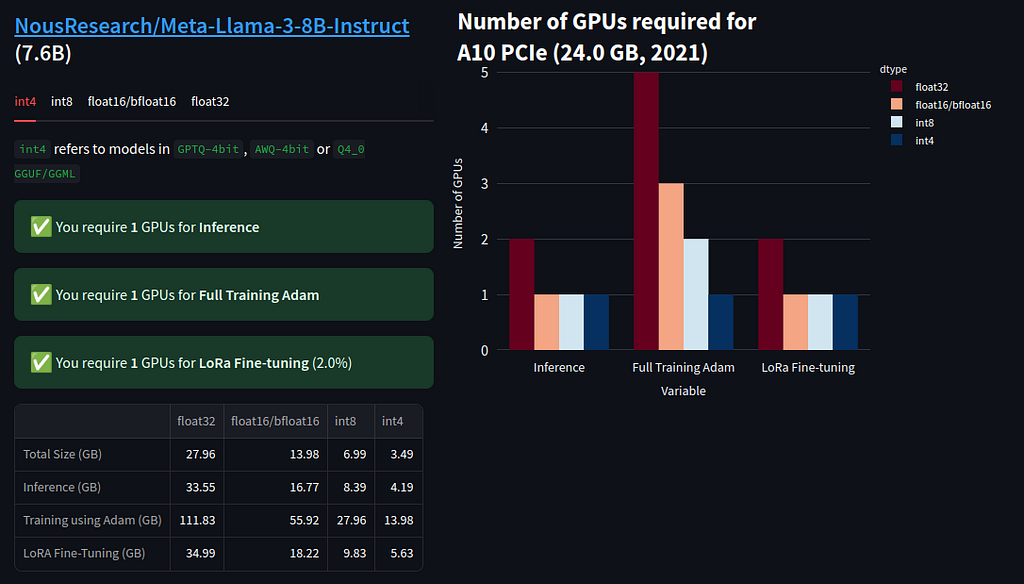
Video memory consumption (GB) for Llama-3–8B:
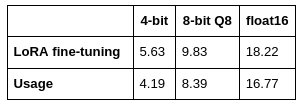
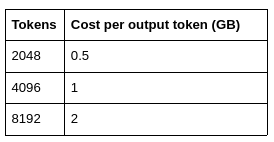
Below are the video memory costs per token, calculated using the formulas provided in this article:
In the end, the only feasible option for training on a laptop was the quantized Llama-3–8B-BNB-4bit with support for 8k tokens, requiring roughly 6 GB of video memory. While far from ideal, this setup fit within our hardware constraints.
We began training the model using the Unsloth framework on a laptop with 6 GB of video memory. It worked — but progress was slow. To speed things up, we switched to Google Colab, leveraging a Tesla GPU with 16 GB of memory. This move significantly accelerated the training process.
Of course, Google Colab came with its own set of headaches. Free sessions were time-limited, it required an internet connection, and we were occasionally interrupted by captchas. It wasn’t perfect, but it got the job done.
Prompt format for LoRA fine-tuning
Fine-tuning with the LoRA method requires datasets structured with prompts in the following format:
### Instruction:
{}
### Input:
{}
### Output:
{}
For this task, the instruction remained consistent, and the prompt was as follows:
Below is a Solidity code snippet. Write a vulnerability analysis report for it.
### Code:
{}
### Response:
{}
Overcoming early challenges with hallucinations and false positives
Training a quality model starts with a quality dataset. We combed through multiple repositories of Solidity vulnerabilities, but most of the data focused on outdated versions. Luckily, the team at Consensys granted us access to a dataset containing detailed bug descriptions and fixes.
After rigorous filtering and preprocessing, we fine-tuned the model and produced the first working version. Testing it on a sample of 100 random contracts revealed some promising results — the fine-tuned model outperformed its untrained counterparts. However, there was a significant issue: it consistently flagged bugs where none existed. This persistent false positive problem underscored the need for further refinement.
To address the false-positive issue, we enriched the dataset with contracts from the 60 largest projects by TVL, including industry staples like OpenZeppelin and Uniswap, marking them as conditionally safe. This was a time-intensive process but ultimately helped improve the model’s accuracy.
In the second version of the model, false positives were significantly reduced. However, this came at a cost — false negatives increased. After careful evaluation, we decided to revert to the previous state. It’s far better to flag potential bugs and manually filter them during result verification than to overlook actual vulnerabilities with a reassuring ‘everything is fine’ response.
Another issue emerged with the model — response looping:
### Response: function totalSupply() public view override returns (uint256) { return supply; } function supply() public view returns (uint256) { return totalSupply; } function totalSupply() public view override returns (uint256) { return supply; } function supply() public view returns (uint256) { return totalSupply; } function totalSupply() public view override returns (uint256) { return supply; }…..
The model also showed a tendency to “hallucinate”, generating information that was completely unrelated to the request. In one instance, the response had no connection to the audit whatsoever:
### Response: Holmes is a detective who is known for his brilliant deductive reasoning and logical analysis. He is often portrayed as a master of disguise, using his skills to solve crimes and bring criminals to justice. Holmes is also known for his keen observation and ability to notice even the smallest details, which he uses to piece together clues and solve cases. He is often depicted as a loner, but he has a close relationship with his trusted friend and colleague, Dr. Watson. Holmes is a complex and fascinating character, and his story has been adapted for film, television, and literature for over a century.
To reduce false positives, we expanded the dataset and fine-tuned the model once again. While this improved performance, it didn’t fully resolve the issue. One potential factor was the aggressive quantization, reducing the model’s parameter precision to just 4 bits — a notably low level. As a result, we often had to generate multiple responses for the same code and manually filter the results.
Results
The table below summarizes the test results on 100 contract fragments from the test sample. Each fragment was tested with up to three responses, and if at least one response was accurate, the test earned a score of 1 point.
We tested Llama 3–8B_4Q_K_M, Llama 3.1–8B-4Q_K_M, codellama-7B-4Q_K_M, and ChatGPT-4.
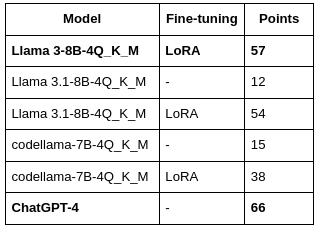
When it comes to public code, ChatGPT-4 can be a handy tool. But if you’re tackling private contract audits, you’ll need your own custom-built agent — and that’s no small task. Creating one demands significant resources, time, and technical expertise.
The key to success lies in data validation and crafting a top-notch dataset. These steps are non-negotiable for building a reliable auditing tool. Developing your own LLM agent is still experimental territory, but the potential is undeniable. With the right approach, you can unlock game-changing possibilities for automating workflows and strengthening blockchain security.
Our socials
How We Trained an LLM to Find Vulnerabilities in Solidity Smart Contracts was originally published in Positive Web3 on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from Positive Web3 - Medium authored by Victor Ryabinin. Read the original post at: https://blog.positive.com/how-we-trained-an-llm-to-find-vulnerabilities-in-solidity-smart-contracts-9337bcae5e46?source=rss----820ff037acec---4
