

Why Regression Testing Matters
Why Regression Testing Matters
·
Regression testing is the practice of re-running functional and non-functional tests to ensure that previously developed and tested software still performs after new code commits are submitted. Inevitably, as more functions are added and more code is integrated into existing codebases, this integration of the old and new can result in new mistakes. When previously tested software does not perform successfully against previously run tests, it is called a “regression”.
While the practice may seem simple and trivial in concept, it is a significant effort that, nonetheless, pays off in dividends in practice. In a 2019 Black Hat Europe speaking session, Google’s OSS-Fuzz program revealed that 40% of their thousands of bugs are actually regressions.
Ensuring previously squashed bugs stay dead is crucial to customer satisfaction. When updates are made to software, the user expectation is to gain more features, more functionality, more convenience. When users are no longer able to fulfill the jobs they were able to before an update, it can lead to unflattering questions about this so-called “upgrade”, leading to loss of trust and, in severe cases, breach of contracts in B2B relationships.
If it’s so important, why aren’t we talking about regression testing more? Why aren’t we excited about regression testing more? Truth be told, because it’s boring. Developers and QA are most inspiring by new features, whether it’s building them or testing them. They’re creative individuals who want to either solve problems with new features or find problems in new features. It’s uninteresting to test and retest old code again, and again, and again before every. single. release. Not to mention that with each release the regression test suite grows larger and larger, leading to increasingly longer regression testing, where more time is spent testing old features rather than testing and influencing the build out of high-anticipated, new features before they hit the door. Then there’s the administrative tasks ensuring the test suites are continuously optimized. Those regression test suites aren’t going to maintain themselves!
Make Regression Testing a Snap.
ForAllSecure Mayhem autonomously builds and optimizes test suite, making regression testing quick and easy.
These are the pains that were expressed to us by our customers. That’s why in our v1.9 release, we made major performance improvements on our Mayhem Analysis Engine. We’re excited to share that as a result of this latest release we’ve improved the analysis speed by at least 3x on running regression tests and reporting of test cases. For example, with v1.8 running 10,000 test cases could take up to 25 minutes; it now takes just 4 minutes. Our goal here is shortening time to results so that users can quickly see the initial results, fix the critical defects, and do the next iteration. Customers pointed out to us that faster regression testing speed is critical to speeding up their CI/CD pipeline. We will continue to invest in improving the core Mayhem Analysis Engine so our users can gain more speed and performance when running more complicated targets.
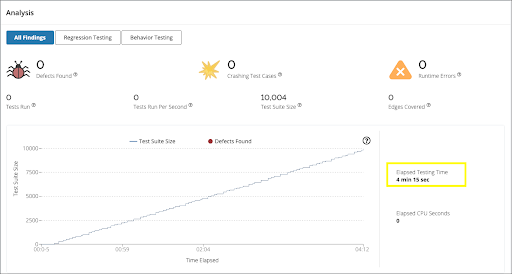
In Mayhem 1.9, the same 10,004 regression tests took 4 minutes.
Our mission to our customers is simple: Allow teams — whether it’s development, security, performance, and/or quality assurance — to focus on what’s most strategic to them, allowing autonomous testing to take care of the rest.
Interested in learning more about Mayhem for Code? Request a personalized chat with our team of security experts here.
Stay Connected
Subscribe to Updates
By submitting this form, you agree to our
Terms of Use
and acknowledge our
Privacy Statement.
This site is protected by reCAPTCHA and the Google
Privacy Policy
and
Terms of Service
apply.
*** This is a Security Bloggers Network syndicated blog from Latest blog posts authored by Mehdi Hashemian. Read the original post at: https://forallsecure.com/blog/why-regression-testing-matters
