

Cloudflare RCA: Major outage was a lot more than “a regular expression went bad”
On July 2, 2019, Cloudflare suffered a major outage due to a massive spike in CPU utilization in the network. Ten days after the outage, on July 12, Cloudflare’s CTO John Graham-Cumming, has released a report highlighting the details about how the Cloudflare service went down for 27 minutes.
During the outage, the company speculated the reason to be a single misconfigured rule within the Cloudflare Web Application Firewall (WAF), deployed during a routine deployment of new Cloudflare WAF Managed rules. This speculation turns out to be true and caused CPUs to become exhausted on every CPU core that handles HTTP/HTTPS traffic on the Cloudflare network worldwide.
Graham-Cumming said they are “constantly improving WAF Managed Rules to respond to new vulnerabilities and threats”.
The CPU exhaustion was caused by a single WAF rule that contained a poorly written regular expression that ended up creating excessive backtracking.

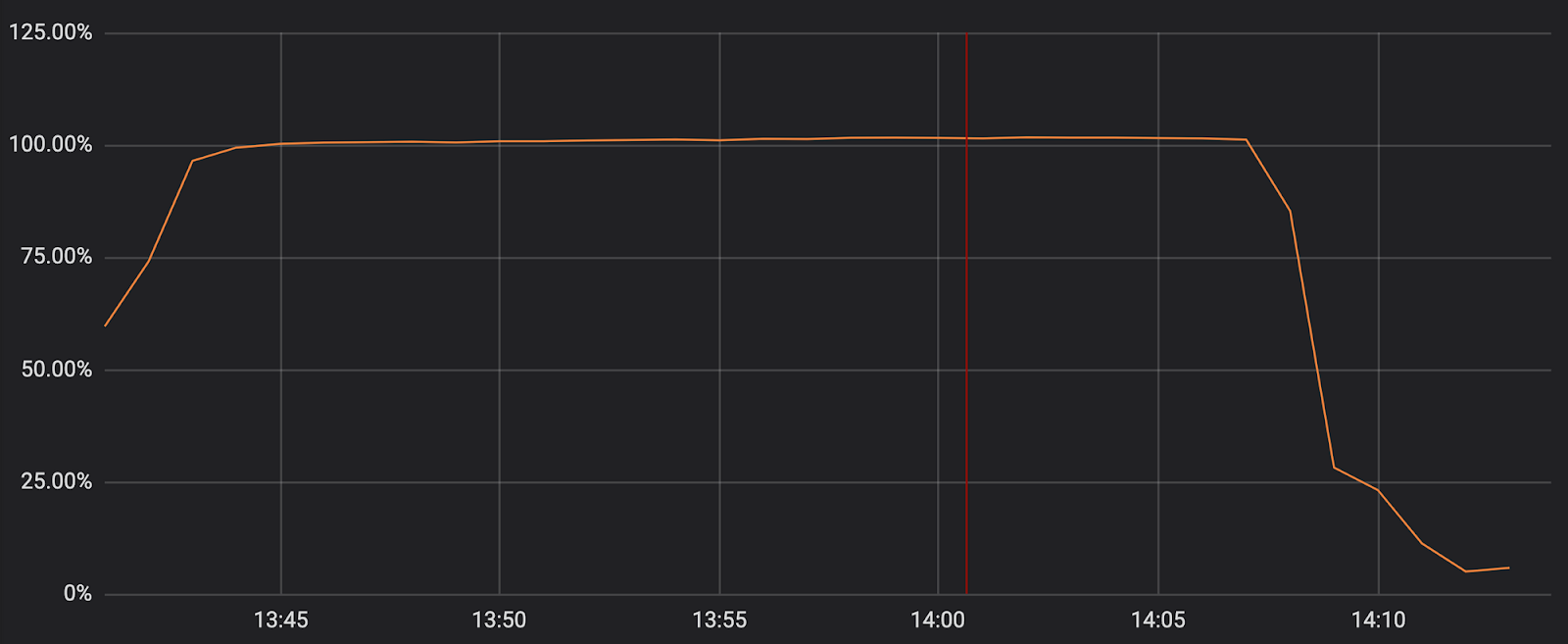
Source: Cloudflare report
The regular expression that was at the heart of the outage is :

Graham-Cumming says Cloudflare deploys dozens of new rules to the WAF every week, and also have numerous systems in place to prevent any negative impact of that deployment. He shared a list of vulnerabilities that caused the major outage.

What’s Cloudflare doing to mend the situation?
Graham-Cumming said they had stopped all release work on the WAF completely and are following some processes:
 He says, for longer-term, Cloudflare is “moving away from the Lua WAF that I wrote years ago”. The company plans to port the WAF to use the new firewall engine, which provides customers the ability to control requests, in a flexible and intuitive way, inspired by the widely known Wireshark language. This will make the WAF both faster and add yet another layer of protection.
He says, for longer-term, Cloudflare is “moving away from the Lua WAF that I wrote years ago”. The company plans to port the WAF to use the new firewall engine, which provides customers the ability to control requests, in a flexible and intuitive way, inspired by the widely known Wireshark language. This will make the WAF both faster and add yet another layer of protection.
Users have appreciated Cloudflare’s efforts in taking immediate calls for the outage and being completely transparent about the root cause of it with a complete post mortem report.
Kudos to @Cloudflare for their excellent postmortem. This is how you write an honest and detailed report after an outage: https://t.co/fcBYgMqmjG
— Fatih Arslan (@fatih) July 13, 2019
Kudos to Cloudflare for publishing a very honest in-depth report on how they broke the Internet for 30 minutes. Love companies who do this.
“Details of the Cloudflare outage on July 2, 2019” https://t.co/zraPNgzZpV
— Neal McQuaid (@nealmcquaid) July 15, 2019
Adding @Cloudflare July 2 incident report as a gold standard example for clients on what a great report looks like. Agree the narrative is very clear and approachable, along with empathy for both the involved teams and their customers. 💯 https://t.co/EbCbJ9ukzh https://t.co/RgsW8VqSqa
— Steve Jansen (@_stevejansen) July 16, 2019
“We are ashamed of the outage and sorry for the impact on our customers. We believe the changes we’ve made mean such an outage will never recur,” Graham-Cumming writes.
Read the complete in-depth report by Cloudflare on their blog post.
Read Next
Cloudflare adds Warp, a free VPN to 1.1.1.1 DNS app to improve internet performance and security
Cloudflare raises $150M with Franklin Templeton leading the latest round of funding
*** This is a Security Bloggers Network syndicated blog from Security News – Packt Hub authored by Savia Lobo. Read the original post at: https://hub.packtpub.com/cloudflare-rca-major-outage-was-a-lot-more-than-a-regular-expression-went-bad/
