

Pararse sobre hombros de gigantes
En nuestro último artículo,
difundimos el descubrimiento de una vulnerabilidad en libpng.
Pero esta es solo una pequeña biblioteca,
se podría decir,
con un alcance muy limitado y solo 556 KiB instalados.
Sin embargo, montones de paquetes dependen de ella.
Para ver cuántos paquetes del repositorio de Arch Linux
dependen de libpng podemos usar el pacgraph
de Kylee Keen:
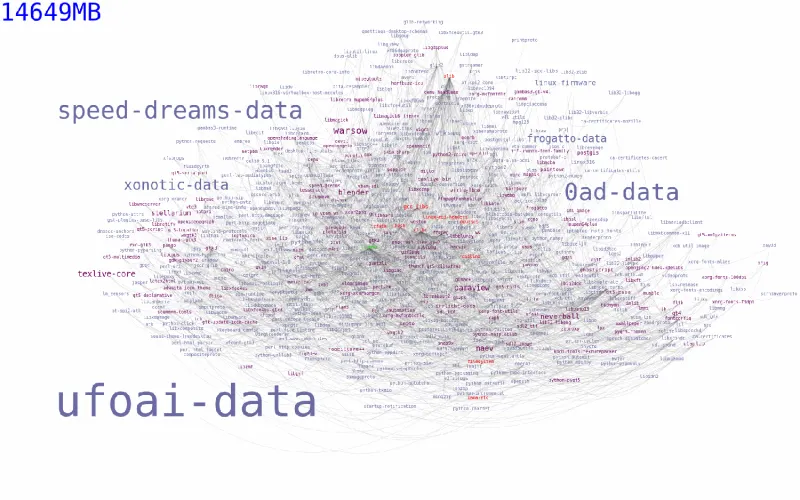
Imagen 1. dependencias inversas de libpng en Arch Linux
¡Más de 14 GiB de software dependen de libpng!
Y eso solo en los repositorios de Arch Linux,
que no es precisamente la distribución Linux más popular.
Además,
la biblioteca es la referencia oficial de PNG y es multiplataforma,
por lo que seguramente muchos otros paquetes
en otros sistemas operativos dependen de ella.
Ahora bien, en el año 2015,
cuando libpng aún no había corregido el error low-high palette,
todos los programas y bibliotecas anteriores
también eran automáticamente vulnerables al mismo problema.
De hecho esto es lo que le pasó a Equifax
con una vulnerabilidad en Apache Struts.
Al igual que muchos servicios web que utilizan OpenSLL con Heartbleed.
Si esto le puede pasar a equipos tan emblemáticos como
bash,
qt,
TeX y
xfce, también le puede pasar a tu organización.
De hecho,
este problema es tan común que forma parte del
Top 10 de OWASP de 2017:
lo llaman “A9: Usar componentes con vulnerabilidades conocidas.”
Dada la rápida adopción del software libre
y de código abierto (FOSS) por parte de las grandes empresas,
de repente la vulnerabilidad de las dependencias parece ser
un problema tremendo.
O más bien, como les gustaría señalar a los yuppies,
¿una “oportunidad de negocio”?
Desde entonces han aparecido en la escena
de la seguridad muchos proveedores del llamado análisis
de la composición del software (SCA)
(no lo busques en Google).
Alguno de ellos están respaldados por empresas de larga trayectoria;
la mayoría, no.
De hecho,
este negocio ha tomado tanto impulso que se espera
que crezca más de un 20% cada año de aquí
al 2022.
Lo peor es que hace quedar mal al FOSS,
al que todas estas empresas se deben.
Sin embargo,
su adopción no se frena y,
como intentaremos demostrar aquí, no es tu culpa,
sino la de la aplicación dependiente;
y también que no es cosa del FOSS,
sino que los esfuerzos de marketing apuntan hacia él.
Las aplicaciones de hoy en día utilizan en promedio más de 30 bibliotecas,
que representan hasta el 80% del código. [2] Piensa en ello
como si tu código fuera solo una fina capa sobre un edificio
de algunas cajas pequeñas y otras más grandes.
Lo que SCA hace entonces es buscar vulnerabilidades
dentro de esas cajas con información de bases de datos externas,
que luego se convierten en vulnerabilidades en tu propia aplicación:
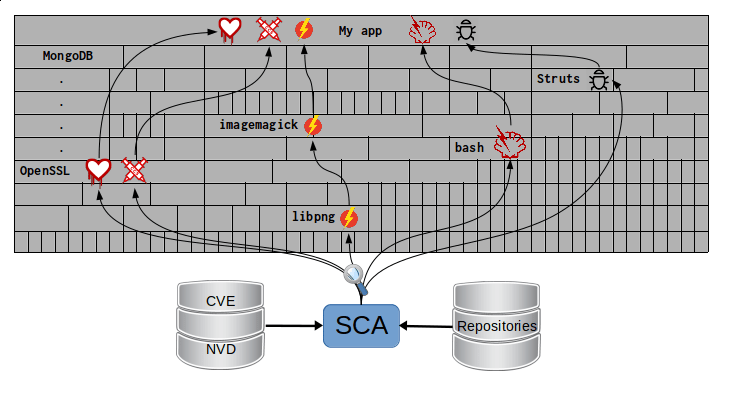
Imagen 2. SCA escanea todos los bloques del edificio de tu app
En lugar de ir desde la supuesta solución hacia el origen del problema,
hagámoslo al revés.
Lo malo
El software libre es desarrollado
y utilizado por miles de personas en todo el mundo.
Esto puede ser un arma de doble filo:
por un lado, según la “Ley de Linus”,
la búsqueda de errores y la aplicación de parches
deberían ser más fáciles al haber más implicados.
Por otro lado, la falta de control centralizado
favorece la aparición de fallas.
Pero eso lo hacen todos los tipos de software.
La diferencia con el software propietario es que,
debido a todas las restricciones,
es “menos probable” que sus fallas se hagan públicas
tan pronto como lo harían en el lado más libre de las cosas.
Así que espera que todas las vulnerabilidades sean de día cero.
Entonces, si el origen del problema no es el software libre,
¿cuál es? Las principales razones por las que tantas empresas sufren de A9:
-
Desconocimiento de las dependencias utilizadas.
-
Desconocimiento de sus vulnerabilidades.
-
No escanear continuamente en busca de vulnerabilidades.
-
No realizar pruebas de compatibilidad.
-
Mala configuración de los componentes.
En definitiva,
todo se reduce a una falta de comunicación entre el usuario
y la fuente de los componentes.
Lo bueno
¿Qué se puede hacer? OWASP recomienda las siguientes recomendaciones
para prevenir A9:[1]
-
Recorta dependencias innecesarias, características, componentes, etc.
Así tendrás menos para revisar. -
Supervisa continuamente los componentes en búsqueda de actualizaciones
y reportes de vulnerabilidades. -
Obtén solo componentes de fuentes fiables.
-
Convierte estas pautas en una política de empresa.
Existen herramientas específicas para este fin:
comparan la versión de la dependencia que estás utilizando tanto
con repositorios remotos
(para comprobar si hay actualizaciones)
como con bases de datos de vulnerabilidades
(como para averiguar si alguna de tus dependencias
ha reportado vulnerabilidades que aún no han sido corregidas.)
-
Para JavaScript puedes usar
retire.js. -
Los usuarios de Java tienen el plugin
Versions
para Maven. -
También para Java y .NET, puedes utilizar la
herramientaOWASP Dependency-Check. -
Hay un plugin SonarQube de evaluación de
dependencias.
Ten en cuenta que las herramientas específicas del lenguaje
tienen que estar integradas con el gestor de paquetes apropiado,
como npm o yarn con retire.
Una vista panorámica de cómo el proceso debe integrarse
con tu flujo de desarrollo se representa
en el siguiente diagrama proporcionado por Source:Clear.

Imagen 3. Integrando SCA en tu flujo de desarrollo. Vía Source:Clear.
Vemos que cada vez que se añade código,
todo el sistema es escaneado en búsqueda de vulnerabilidades de software
de terceros y otros problemas fácilmente identificables
por Análisis Estático cuando el código no está disponible.
Esto se hace siguiendo este procedimiento:
-
El SCA identifica las dependencias
en las que tu software se basa. -
Detecta las versiones de esas dependencias.
-
Comprueba si hay actualizaciones en el repositorio maestro de dependencias.
-
Comprueba una o varias bases de datos de vulnerabilidades, como
CVE y NVD
o las suyas. -
Reporta los hallazgos.
En realidad, se trata de un proceso sencillo.
Ten en cuenta que la integración no es totalmente automática,
y no debería serlo, ya que estas herramientas podrían dar
(y suelen dar) falsas alarmas,
por lo que son revisadas por especialistas en seguridad.
Internamente, el proceso de búsqueda de software de terceros
es el mismo tanto para el propietario como para el libre,
y es una simple cuestión de consultar las bases de datos
de vulnerabilidades como hemos descrito anteriormente.
Hablando de integración, puede que te preguntes:
¿Qué pasa si mi aplicación se despliega dentro de un contenedor?
“El 30% de las imágenes oficiales de Docker Hub contienen vulnerabilidades
de seguridad de alta prioridad”, según Pentestit.
Afortunadamente,
hay herramientas que entran en tu contenedor
y realizan SCA dentro de él (y más), como Anchore
y
Dockerscan.
Lo feo
Sé que buscaste “Análisis de composición de software”
cuando te sugerí que no lo hicieras.
Sólo sé que lo hiciste. Si no lo hiciste,
¡bien por ti! Esto es lo que te estás perdiendo:
Imagen 4. Proveedores de “Análisis de Composición de Software”.
Todos estos líderes de la industria, galardonados,
creadores de avances, oráculos del futuro de la tecnología,
quieren venderte una cosa: análisis de código estático
más las herramientas que hemos comentado antes.
Aunque el análisis estático es una herramienta válida,
es sólo una herramienta.
Puede escanear código y detectar vulnerabilidades
y prácticas poco saludables,
pero también fomenta la detección tardía
y produce muchos falsos positivos.
Podrías contratar un servicio de este tipo,
e incluso intentar complementarlo con herramientas
de análisis dinámico como fuzzing
y debuggers, pero estos tienen sus propios problemas.
Pero no sustituyen a la
revisión de código
a la antigua, por humanos.
Al menos por el momento.
Según [3],
La única forma de afrontar el riesgo de vulnerabilidades
desconocidas en las bibliotecas es que alguien
que entienda de seguridad analice el código fuente.
El análisis estático de las bibliotecas es mejor concebirlo
como una forma de dar señales de dónde pueden estar localizadas
las vulnerabilidades de seguridad en el código,
y no como un sustituto de los expertos.
En el futuro, es posible que veamos cosas como
pruebas de seguridad
distribuidas bajo demanda
y algoritmos de aprendizaje automático[2]
que utilicen máquinas de vectores de soporte para intentar predecir
qué commits tienen más probabilidades de abrir vulnerabilidades.
Referencias
*** This is a Security Bloggers Network syndicated blog from Fluid Attacks RSS Feed authored by Rafael Ballestas. Read the original post at: https://fluidattacks.com/es/blog/sobre-hombros-gigantes/
