
Efficiently Testing Pipelined Microservices
Behind the magically populating dashboards of ShiftLeft lies a complex web of services. We have the state-of the art code property graph generation and querying systems that run on each incoming code artifact, squeezes the security DNA from it and uses it at runtime for providing immediate value of identifying data leakage, exploits in progress etc. This is not a simple task — much of the work is pipelined in nature. Behind the scenes, most of the individual components are following the microservices architecture. This allows the pipelined components to work asynchronously and in tandem with other parts of the Shiftleft architecture. We can equate this to the batch process of brewing beer.

Then quality of the beer here depends on each of the stages in pipeline. The tanks need to be cleaned and there should be proper points in the pipeline where we test the output of each stage along with the temperature and ph levels. This requires observability points throughout the pipeline. If this was to be part of a complete beer development microservices architecture, it would be something like this:
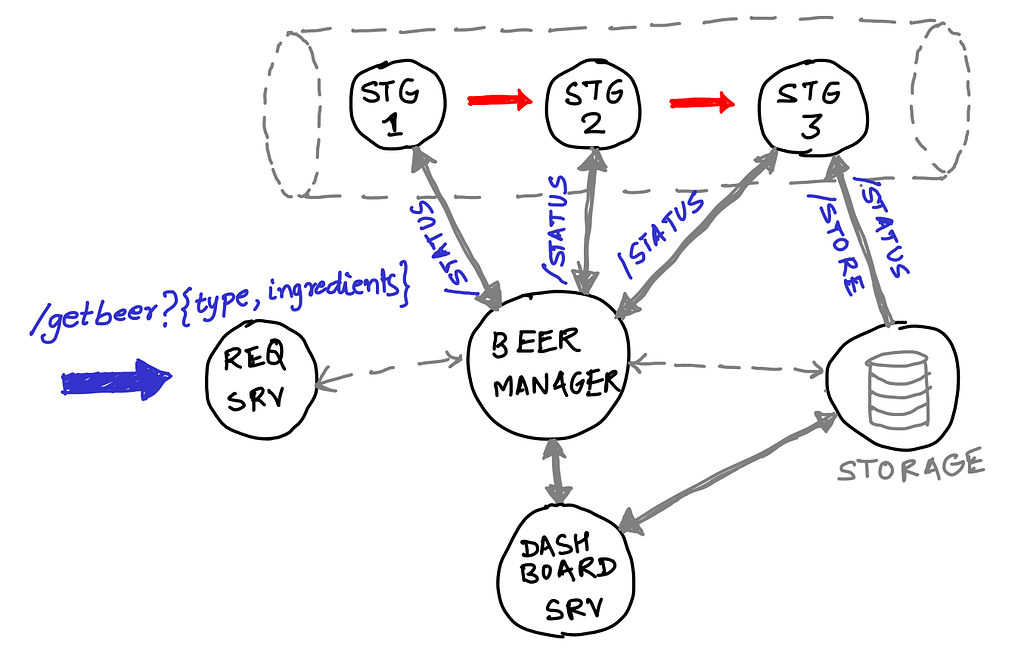
A single request through this service requires all the components to work efficiently. There should be proper request pipelines, event pipelines as well as request management services that can manage incoming requests and route/follow them. And then, of course is the serial 3 staged pipeline through with a request and its associated data flows. Testing such an architecture requires test points in multiple locations and mechanisms to identify them. And not only that, the system should be tested in production as well as staging and integration environments. As Cindy Sridharan pointed out in her comprehensive blog series, testing a staging or integration environment is never enough — the nature of incoming data and requests varies a lot with the application’s runtime environment. What might work in an integration test silo could easily fail in production. At ShiftLeft, we have observed it from time to time. The convoluted nature of the web of microservices also pose a far more greater challenge now. What used to testing the olden days is now a marriage of testing/performance monitoring/live debugging at different steps of software development lifecycle. There is no silver bullet of a “QA Team” that will run their magic tests and can “certify” a release. Testing is a continuous process that starts by empowering developers to perform tests and carrying this forward to a real production environment where we can still do exploratory testing as well as live monitoring. All these intermediate test stages need to inform the developers as well as operations of what fails, when and where it fails, and how to start fixing stuff quickly. We are still young and we have a hot cake 🍰 in our hands and fires 🔥 in production are inevitable. What is required from a team like ours is a marriage of all the observation tools at our disposal and come up with a testing infrastructure and methodology that works and scales as we grow. An interesting solution that we have been following recently and have been quite successful at, is a new form of Test Driven Development.
Test Driven Development — Next Generation
As Noel has pointed out before in his multi-part blog series, TDD is of course not something new and swanky. Everyone does that — even if you don’t actually know you are doing it subconsciously. For example, we all write unit tests. When we build and run those, they might fail, we go back and fix stuff and run them again. For each incoming feature, we add some more tests and ensure that they pass. When we have tests often, and for smaller and manageable chunks of code, it becomes easy to pin-point issues. However, TDD with unit tests is all fine and dandy — the moment we bring interdependent microservices in the picture, developers start scratching their heads. Whose test is the source of truth? Which commit in which microservice was the culprit. Is there a commit in one repository that affected the commit in another? Here is what I have observed how me and my peers have felt with each incoming release:

Therefore, we need to change — we need to take this strategy which helps us solve issues fast and allow the modern microservices to adapt to it. I’ve also observed that the testing utopia is unachieveable. You may have 100% unit test coverage, but simple environment configs could send you down an investigation spiral to the point that you don’t even know what you started investigation in the first place! Therefore, modern TDD esp. for pipelines microservices, should have the following characterstics:




Statged Tests: Tests all along from development to production should be run in a staged manner. A single run should follow each stage of the microservice pipeline. If possible, multiple stages should be linked in such a manner that a failure in the pipeline should point us to an error in a given stage. A simple solution is to have staged tests follow the pipeline stages with each run identified with a hash and carrying as much contextual information about the run as possible for making debugging easy in cases of failure. Think of such staged tests as a series of pressure indicators in an actual water pipeline. A pressure gauge showing a sudden drop between the first to the second one means there was a leak nearby. We need not divert our resources to check the pressure gauges at the end stages of pipeline anymore. This helps pinpoint issues faster in such cases. Some real life examples of pipelined architectures that may have similar designs are image processing pipelines. For example, a cloud service that involves cat face detection capabilities on an input image of your cute cat requires a series of actions to be performed in a pipelined fashion on a single input image.
Correlated Observability: All the observability sources — for performance analysis (KPIs, alerts), debugging metrics, and other logs should be synced with test runs. For example, a failure in a pre-production tests when correlated with an alert on database query timings along with a visual observation of an increased latency through a distributed tracing system like Zipkin can help narrow down problems easily and early. They can prevent broken releases faster than you though.
Multi-Environment Testing: Testing should not just be multi environment — but tuned for accommodating idiosyncrasies of each environment. What works in a single environment would not necessarily work in another one. Apart from that, diverting traffic or simulating traffic in production for local tests or integration tests can help in diagnosing errors early and reduces the turnaround time. In addition, production environment tests are mandatory. Along with correlated observability, they form a wall of confidence and are an indication of system’s robustness.
Event Driven and Cron’ed Tests: In some cases, tests need to be cron’ed and/or varying customer workloads at the time of the day and developer activity can indicate possible bottlenecks faster. Tests should also be event driven(service tagging, promoting from one env to another etc.) While tests should not be an indication of the all-hands-on-deck! signal (usually observability tools are designed for it), they can still act as re-enforcing indicators of issues and perhaps help in the investigation further.
Accuracy and Precision: In the modern world, tests should not only test for accuracy, but also for precision. Accuracy is truthfulness of observed data. For example, “Is the beer tasting as good as the baseline taste standard we have set for our beers?”. Precision is the repeatability of the results. “Are all the batches of our beer tasting same consistently?” In our software world, tests should cater to not only robustness of system by checking if for all runs we get the same data, but also check the data against a well defined baseline. Performance tests are the ones that need to be very careful about this point. For example a constant and repeatable saw-tooth patterned memory consumption rising till 50% peak value may be OK from a precision perspective, but if the expected baseline is supposed to be a 10% constant line, this could be an indication that we may be affecting other resources (maybe the garbage collector is increasing CPU usage from time to time, and there is a major underlying issue in the code).
Testing strategies are always evolving. They morph and evolve as the code and infrastructure evolves. What works right now probably won’t work with a million customers. What we have discussed is slightly different from the traditional definition of TDD from the agile standpoint. But it works for the microservices mesh that we have. This too will evolve — as always, we need to focus on some good beer batches coming out, and TDD can help with that! Cheers 🍺
Efficiently Testing Pipelined Microservices was originally published in ShiftLeft Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
*** This is a Security Bloggers Network syndicated blog from ShiftLeft Blog - Medium authored by Suchakra Sharma. Read the original post at: https://blog.shiftleft.io/efficiently-testing-pipelined-microservices-fa219b75e0a9?source=rss----86a4f941c7da---4
